Mac部署hadoop3(伪分布式)
环境信息
- 操作系统:macOS Mojave 10.14.6
- JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home)
- hadoop:3.2.1
开通ssh
在"系统偏好设置"->"共享",设置如下:
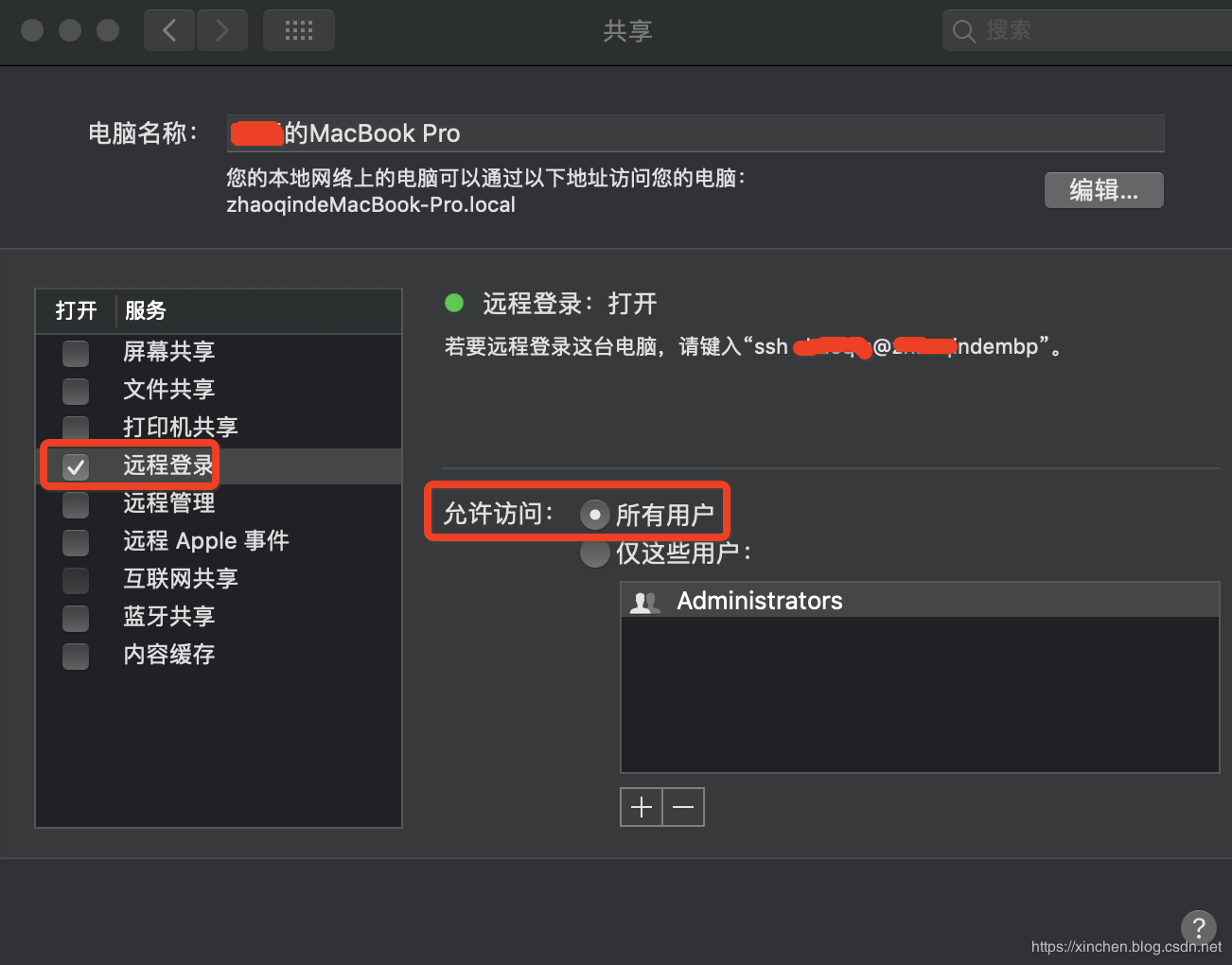
免密码登录
- 执行以下命令创建秘钥:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
一路next,最终会在~/.ssh目录生成id_rsa和id_rsa.pub文件
2. 执行以下命令,将自己的秘钥放在ssh授权目录,这样ssh登录自身就不需要输入密码了:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- ssh登录试试,这次不需要密码了:
Last login: Sun Oct 13 21:44:17 on ttys000
(base) zhaoqindeMBP:~ zhaoqin$ ssh localhost
Last login: Sun Oct 13 21:48:57 2019
(base) zhaoqindeMBP:~ zhaoqin$
下载hadoop
- 下载hadoop,地址是:http://hadoop.apache.org/releases.html
- 将下载文件hadoop-3.2.1.tar.gz解压,我这里解压后的地址是:~/software/hadoop-3.2.1/
如果只需要hadoop单机模式,现在就可以了,但是单机模式没有hdfs,因此接下来要做伪分布模式的设置;
伪分布模式设置
进入目录hadoop-3.2.1/etc/hadoop,做以下设置:
- 打开hadoop-env.sh文件,增加JAVA的路径设置:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home
- 打开core-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 打开hdfs-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 打开mapred-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 打开yarn-site.xml文件,将configuration节点改为如下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 在目录hadoop-3.2.1/bin执行以下命令,初始化hdfs:
./hdfs namenode -format
初始化成功后,可见如下信息:
2019-10-13 22:13:32,468 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2019-10-13 22:13:32,473 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2019-10-13 22:13:32,474 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at zhaoqindeMBP/192.168.50.12
************************************************************/
启动
- 进入目录hadoop-3.2.1/sbin,执行./start-dfs.sh启动hdfs:
(base) zhaoqindeMBP:sbin zhaoqin$ ./start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [zhaoqindeMBP]
zhaoqindeMBP: Warning: Permanently added 'zhaoqindembp,192.168.50.12' (ECDSA) to the list of known hosts.
2019-10-13 22:28:30,597 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
上面的警告不会影响使用;
2. 浏览器访问地址:localhost:9870 ,可见hadoop的web页面如下图:
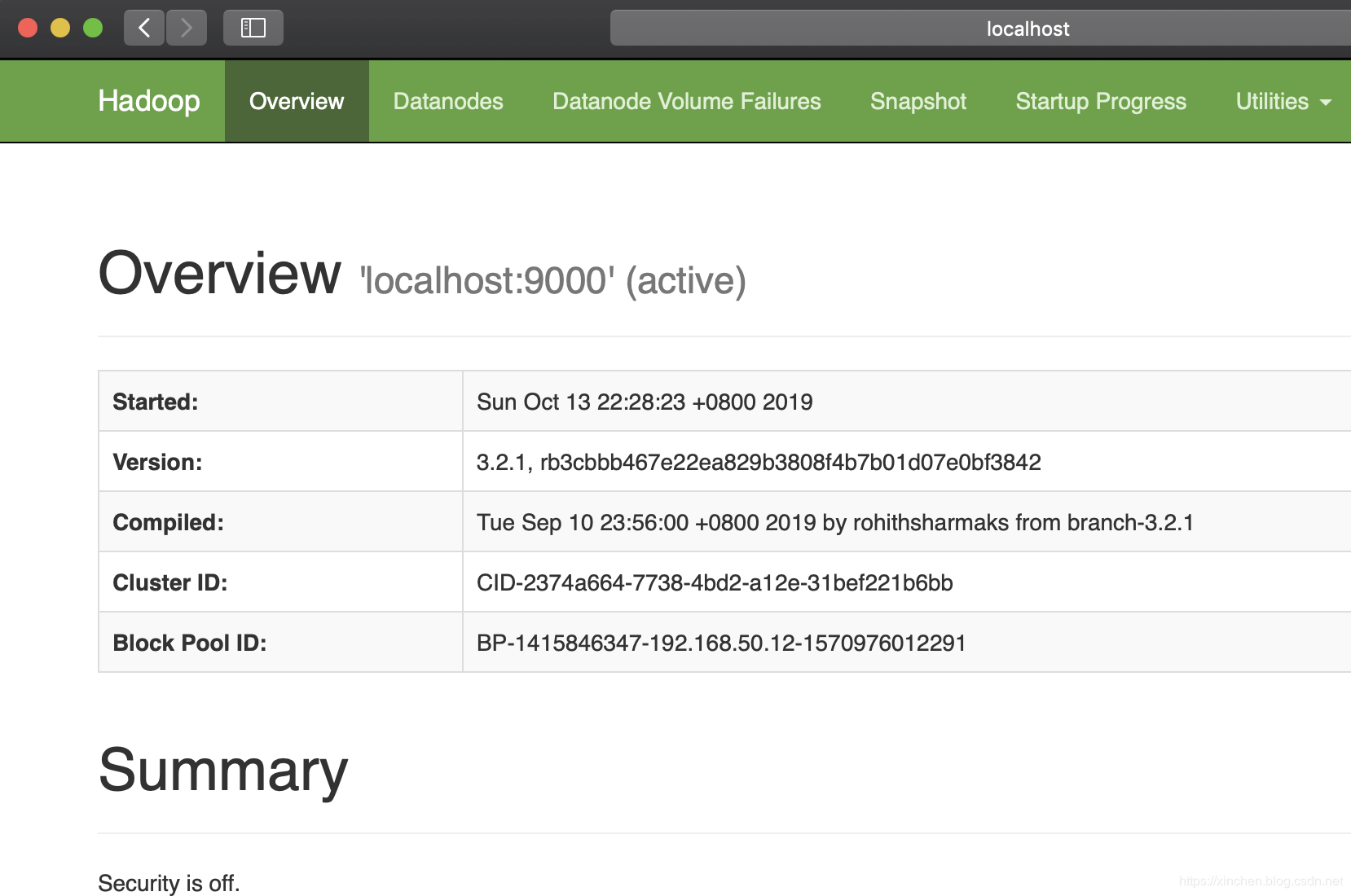
3. 进入目录hadoop-3.2.1/sbin,执行./start-yarn.sh启动yarn:
base) zhaoqindeMBP:sbin zhaoqin$ ./start-yarn.sh
Starting resourcemanager
Starting nodemanagers
- 浏览器访问地址:localhost:8088 ,可见yarn的web页面如下图:

- 执行jps命令查看所有java进程,正常情况下可以见到以下进程:
(base) zhaoqindeMBP:sbin zhaoqin$ jps
2161 NodeManager
1825 SecondaryNameNode
2065 ResourceManager
1591 NameNode
2234 Jps
1691 DataNode
至此,hadoop3伪分布式环境的部署、设置、启动都已经完成。
停止hadoop服务
进入目录hadoop-3.2.1/sbin,执行./stop-all.sh即可关闭hadoop的所有服务:
(base) zhaoqindeMBP:sbin zhaoqin$ ./stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as zhaoqin in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [zhaoqindeMBP]
2019-10-13 22:49:00,941 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping nodemanagers
Stopping resourcemanager
以上就是Mac环境部署hadoop3的全部过程,希望能给您一些参考。
欢迎关注公众号:程序员欣宸
Mac部署hadoop3(伪分布式)的更多相关文章
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Mac部署spark2.4.4
环境信息 操作系统:macOS Mojave 10.14.6 JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jd ...
- Hadoop2 伪分布式部署
一.简单介绍 二.安装部署 三.执行hadoop样例并測试部署环境 四.注意的地方 一.简单介绍 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop的框架最核心的设计就是: ...
- 【Hadoop基础教程】3、Hadoop之伪分布式环境搭建(转)
伪分布式模式即单节点集群模式,所有的守护进程都运行在同一台机器上.这种模式下增加了代码调试功能,可以查看内存.HDFS文件系统的输入/输出,以及与其他守护进程交互.以hadoop用户远程登录K-Mas ...
- hadoop3.1伪分布式部署
1.环境准备 系统版本:CentOS7.5 主机名:node01 hadoop3.1 的下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/hado ...
- 大数据技术之Hadoop3.1.2版本伪分布式部署
大数据技术之Hadoop3.1.2版本伪分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.主机环境准备 1>.操作系统环境 [root@node101.yinzh ...
- linux18.04+jdk11.0.2+hadoop3.1.2部署伪分布式
1. 下载 安装hadoop3.1.2http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz 注意 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- Hadoop安装-单机-伪分布式简单部署配置
最近在搞大数据项目支持所以有时间写下hadoop随笔吧. 环境介绍: Linux: centos7 jdk:java version "1.8.0_181 hadoop:hadoop-3.2 ...
随机推荐
- Windows 7 上怎样打开SQL Server 配置管理器
场景 在Windows 7 上打开 SQL Server 的配置管理器. 实现 右击电脑--管理 在计算机管理--服务和应用程序-SQL Server 配置管理器 注: 博客首页: https://b ...
- Kubernetes监控实践
一.Kubernetes介绍 Kubernetes(K8s)是一个开源平台,能够有效简化应用管理.应用部署和应用扩展环节的手动操作流程,让用户更加灵活地部署管理云端应用. 作为可扩展的容错平台,K8s ...
- 松软科技课堂:SQL--RIGHTJOIN关键字
发布时间:2019/3/15 9:27:31 SQL RIGHT JOIN 关键字 RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name ...
- Linux 笔记 - 第十一章 正则表达式
博客地址:http://www.moonxy.com 一.前言 正则表达式(英语为 Regular Expression,在代码中常简写为 regex.regexp 或 RE),是使用单个字符串来描述 ...
- Day 23 系统服务之救援模式
1.CentOS6与Centos 7启动流程 4.运行级别C6&C7 0 关机 1 单用户模式 (超级权限 必须面对实体硬件) 2 暂未使用 3 字符界面(黑框) 4 暂未使用 5 图形界面 ...
- 快速获取dom到body左侧和顶部的距离,简单粗暴无bug-getBoundingClientRect
获取dom到body左侧和顶部的距离-getBoundingClientRect 平时在写js的时候,偶尔会需要用js来获取当前div到 body 左侧.顶部的距离.网上查一查,有很多都是通过offs ...
- Hbase入门(一)——初识Hbase
本文将介绍大数据的知识和Hbase的基本概念,作为大数据体系中重要的一员,Hbase弥补了Hadoop只能离线批处理的不足,支持存储小文件,随机检索.而这种特性使得Hbase对于实时计算体系的事件存储 ...
- 使用SpringDataRedis的入门
在使用ssm框架下,我们会到redis做缓存. 1> 第一步,导包. <!-- Redis客户端 --> <dependency> <groupId>redi ...
- 关于canvas合成分享图
最近在uni-app项目中遇到一个合成分享图的需求,其实最开始是用原生写法来做的,后台发现在PC端测试是可以的,但在APP模拟器中会出现问题,可能是因为两者的js环境不同吧,uni-app官网也说了这 ...
- Flume系列二之案例实战
Flume案例实战 写在前面 通过前面一篇文章http://blog.csdn.net/liuge36/article/details/78589505的介绍我们已经知道flume到底是什么?flum ...