【Java爬虫】爬取南通大学教务处成绩
没使用自动登录,所以获取是比较麻烦。。
1、http://jwgl.ntu.edu.cn/cjcx 进入官网,进行账号密码登录
2、点击全部成绩查询(也一定要点进去,不然cookie不会返回值),按F12进入控制台,找到Network,看到了ScoreAllData.aspx
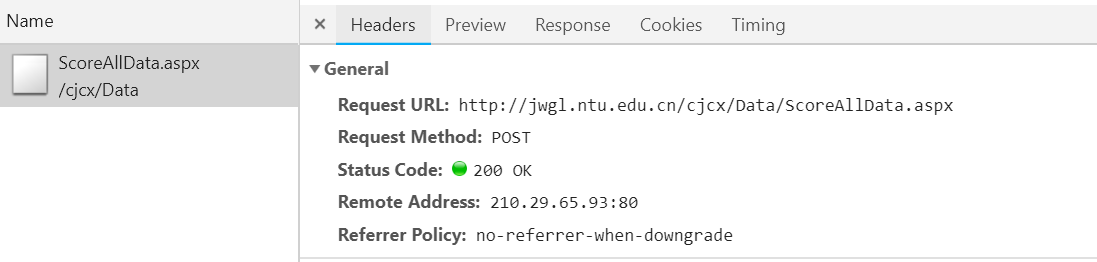
首先看到Response中能看到返回的json数据,证明我们url找对了。。

接下来我们需要看request中的数据
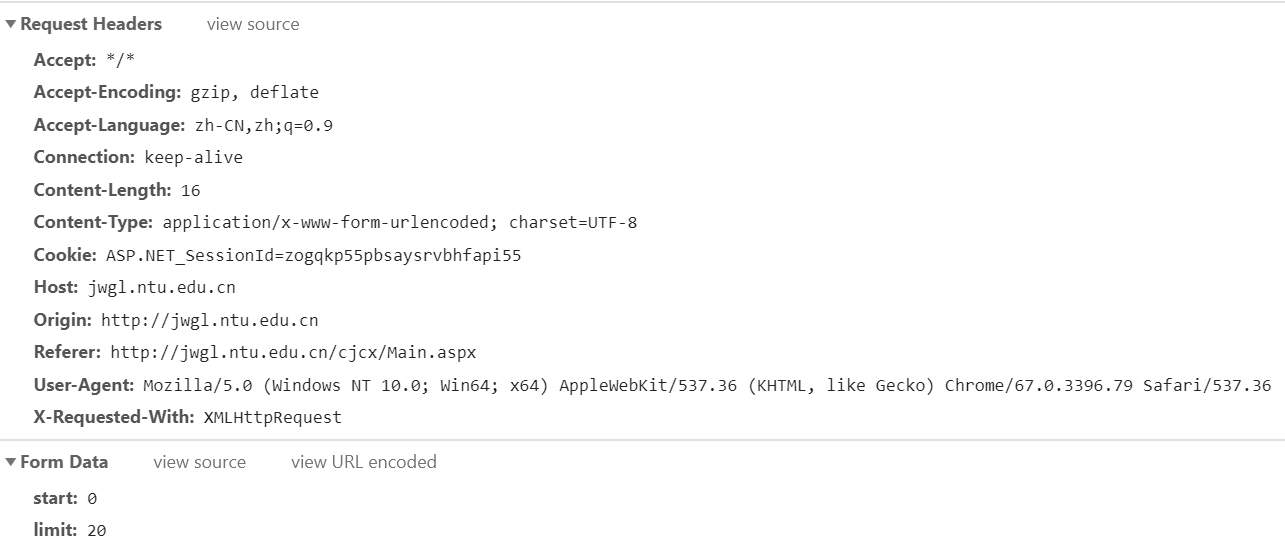
可以看到form data中的start和limit,经过测试,我发现limit只有一个20的值,但是start是可以改变的,所以说换页的时候需要更改start的数据。
还有cookie,登录信息的数据是存在cookie里的(应该是),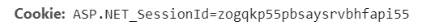
获取这个Id的值,用来使用jsoup爬取数据。
3、下面放代码,再进行分析(代码运行的时候,浏览器页面不要关闭,因为是从cookie获取的值,浏览器一关,cookie就 GG)
package com; import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List; import org.apache.commons.dbutils.QueryRunner;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document; import com.edu.utils.DruidUtils;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken; import net.sf.json.JSONArray;
import net.sf.json.JSONObject; public class Post {
public static void main(String[] args) throws SQLException {
List<Score> scoreList = new ArrayList<>();
try {
scoreList = post(scoreList);
QueryRunner qr = new QueryRunner(DruidUtils.getDatasource());
String sql = "insert into score values(?,?,?,?,?,?,?,?,?,?,?,?)";
for(Score s:scoreList) {
qr.update(sql,s.getKcmc(),s.getJsxm(),s.getXq(),s.getXs(),s.getXf(),s.getZpcj(),s.getPscj(),s.getQmcj(),s.getKcsx(),s.getCjid(),s.getKsfsm(),s.getPxcj());
}
} catch (IOException e) {
e.printStackTrace();
}
} public static List<Score> post(List<Score> scoreList) throws IOException {
// 获取请求连接
Connection con = Jsoup.connect("http://jwgl.ntu.edu.cn/cjcx/Data/ScoreAllData.aspx")
.cookie("ASP.NET_SessionId","zogqkp55pbsaysrvbhfapi55")
.referrer("http://jwgl.ntu.edu.cn/cjcx/Main.aspx")
.ignoreContentType(true)
.userAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36");
Document doc = con.post();
JSONObject jsonObject = JSONObject.fromObject(doc.body().text());
Integer count = (Integer) jsonObject.get("totalCount");
for(int i=0;i<count;i+=20) {
con = Jsoup.connect("http://jwgl.ntu.edu.cn/cjcx/Data/ScoreAllData.aspx")
.cookie("ASP.NET_SessionId","zogqkp55pbsaysrvbhfapi55")
.referrer("http://jwgl.ntu.edu.cn/cjcx/Main.aspx")
.ignoreContentType(true)
.userAgent(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36");
con.data("start",String.valueOf(i));
con.data("limit","20");
Document scores = con.post();
JSONObject scoresObject = JSONObject.fromObject(scores.body().text());
JSONArray jsonArray = scoresObject.getJSONArray("data");
Gson g = new Gson();
List<Score> ps = g.fromJson(jsonArray.toString(), new TypeToken<List<Score>>(){}.getType());
if(ps!=null) {
scoreList.addAll(ps);
}
}
return scoreList;
}
}
Score类是返回data的实体类,用来封装数据。
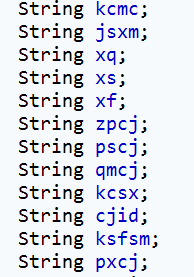
通过post方法进行数据的爬取,在Connection对象里进行cookie,userAgent等数据的封装,注意这个cookie里的值是第二步中从控制台获取到cookie值。
使用JsonObject和Gson进行数据的封装,然后再把数据存入本地数据库中。

4、在JSP中显示或者导出到Excel
(有空再写)
【Java爬虫】爬取南通大学教务处成绩的更多相关文章
- [python爬虫]爬取学校教务处成绩
学校教务处网站 登陆窗口 表单数据 观察登陆窗口和提交的表单数据可知只要将账号.密码.验证码正确赋值提交即可模拟登陆. 账号和密码都有,问题的关键就在验证码上. 右键验证码图片审查观察源码如下图: 刚 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- Java爬虫爬取网站电影下载链接
之前有看过一段时间爬虫,了解了爬虫的原理,以及一些实现的方法,本项目完成于半年前,一直放在那里,现在和大家分享出来. 网络爬虫简单的原理就是把程序想象成为一个小虫子,一旦进去了一个大门,这个小虫子就像 ...
- java爬虫爬取的html内容中空格( )变为问号“?”的解决方法
用java编写的爬虫,使用xpath爬取内容后,发现网页源码中的 全部显示为?(问号),但是使用字符串的replace("?", ""),并不能替换,网上找了一 ...
- java爬虫爬取网页内容前,对网页内容的编码格式进行判断的方式
近日在做爬虫功能,爬取网页内容,然后对内容进行语义分析,最后对网页打标签,从而判断访问该网页的用户的属性. 在爬取内容时,遇到乱码问题.故需对网页内容编码格式做判断,方式大体分为三种:一.从heade ...
- java爬虫爬取资源,小白必须会的入门代码块
java作为目前最火的语言之一,他的实用性也在被无数的java语言爱好者逐渐的开发,目前比较流行的爬取资源,用java来做也更简单一些,下面是爬取网页上所有手机型号,参数等极为简便的数据 packag ...
- 用Java爬虫爬取凤凰财经提供的沪深A股所有股票代号名称
要爬取的凤凰财经网址:http://app.finance.ifeng.com/list/stock.php?t=hs 本作主要采用的技术是jsoup,相关介绍网页:https://www.jians ...
- java爬虫爬取https协议的网站时,SSL报错, java.lang.IllegalArgumentException TSLv1.2 报错
目前在广州一家小公司实习,这里的学习环境还是挺好的,今天公司从业十几年的大佬让我检查一下几年前的爬虫程序是否还能使用…… 我从myeclipse上check out了大佬的程序,放到workspace ...
- Java爬虫爬取京东商品信息
以下内容转载于<https://www.cnblogs.com/zhuangbiing/p/9194994.html>,在此仅供学习借鉴只用. Maven地址 <dependency ...
随机推荐
- 牛客集训第七场J /// DP
题目大意: 在矩阵(只有52种字符)中找出所有不包含重复字符的子矩阵个数 #include <bits/stdc++.h> #define ll long long using names ...
- js 删除数组中指定值
var arr = ['1','2'];delete('1'); function delete(i){ var index = arr.indexOf(i); arr.splice(index, 1 ...
- Markdown语法--整理
Markdown基本语法 [TOC] 优点: 1.因为是纯文本,所以只要支持Markdown的地方都能获得一样的编辑效果,可以让作者摆脱排版的困扰,专心写作. 2.操作简单.比如:word编辑时标记个 ...
- 进程互斥软件实现之Lamport面包店算法
一. 进程互斥的实现方式 1. 软件方式: 保护临界区, 自己编写代码来实现对进程的控制. Dekker算法Peterson算法Lamport算法等 2. 硬件方式: 使用特殊指令保护临界区. 开关中 ...
- leetccode-130-被围绕的区域
题目描述: 方法一:dfs class Solution: def solve(self, board: List[List[str]]) -> None: """ ...
- 2017.1.16【初中部 】普及组模拟赛C组总结
2017.1.16[初中部 ]普及组模拟赛C组 这次总结我赶时间,不写这么详细了. 话说这次比赛,我虽然翻了个大车,但一天之内AK,我感到很高兴 比赛 0+15+0+100=115 改题 AK 一.c ...
- BZOJ2594:水管局长数据加强版
Description SC省MY市有着庞大的地下水管网络,嘟嘟是MY市的水管局长(就是管水管的啦),嘟嘟作为水管局长的工作就是:每天供水公司可能要将一定量的水从x处送往y处,嘟嘟需要为供水公司找到一 ...
- C#一般处理程序设置和读取session(session报错“未将对象引用设置到对象的实例”解决)
登陆模块时,用到了session和cookie.在一般处理程序中处理session,一直报错.最后找到问题原因是需要调用 irequiressessionstate接口. 在ashx文件中,设置ses ...
- Win10弹出需要管理员权限才能删除文件夹,解决办法
Win键+R(就是开始-运行),弹出的输入框输入gpedit.msc回车. 绿色圈内是正解,设置为已禁用.已禁用.已禁用.记着重启才生效.
- QQ邮箱发送信息
#以下库为python自带的库,不需要进行安装 #邮件发信动作 import smtplib #构造邮件内容 from email.mime.text import MIMEText #构造邮件头 f ...