《GPU高性能编程CUDA实战》第十章 流
▶ 本章介绍了页锁定内存和流的使用方法,给出了测试内存拷贝、(单 / 双)流控制下的内存拷贝的例子。
● 测试内存拷贝
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define SIZE (64*1024*1024)
#define TEST_TIMES (100) float cuda_malloc_test(int size, bool up)
{
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime; cudaEventCreate(&start);
cudaEventCreate(&stop); a = (int*)malloc(size * sizeof(int));
cudaMalloc((void**)&dev_a,size * sizeof(*dev_a)); cudaEventRecord(start, );
if (up)
{
for (int i = ; i < TEST_TIMES; i++)
cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
}
else
{
for (int i = ; i < TEST_TIMES; i++)
cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop); free(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsedTime;
} float cuda_host_alloc_test(int size, bool up)
{
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop); cudaHostAlloc((void**)&a, size * sizeof(int), cudaHostAllocDefault);
cudaMalloc((void**)&dev_a, size * sizeof(int)); cudaEventRecord(start, );
if (up)
{
for (int i = ; i < TEST_TIMES; i++)
cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
}
else
{
for (int i = ; i < TEST_TIMES; i++)
cudaMemcpy(a, dev_a, size * sizeof(int), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop); cudaFreeHost(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return elapsedTime;
} int main(void)
{
float elapsedTime;
float testSizeByte = (float)SIZE * sizeof(int) * TEST_TIMES / / ; elapsedTime = cuda_malloc_test(SIZE, true);
printf("\n\tcudaMalloc Upwards:\t\t%3.1f ms\t%3.1f MB/s",elapsedTime, testSizeByte / (elapsedTime / ));
elapsedTime = cuda_malloc_test(SIZE, false);
printf("\n\tcudaMalloc Downwards:\t\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / )); elapsedTime = cuda_host_alloc_test(SIZE, true);
printf("\n\tcudaHostAlloc Upwards:\t\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / ));
elapsedTime = cuda_host_alloc_test(SIZE, false);
printf("\n\tcudaHostAlloc Downwards:\t%3.1f ms\t%3.1f MB/s", elapsedTime, testSizeByte / (elapsedTime / )); getchar();
return;
}
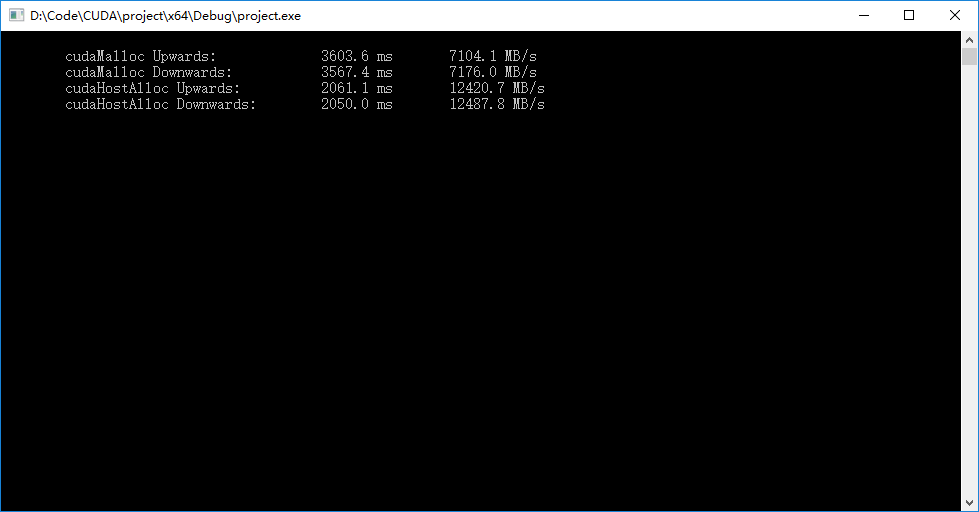
● 程序输出如下图,可见页锁定内存的读取速度要比内存快一些。
● 页锁定内存的使用方法
int *a, *dev_a, size; cudaHostAlloc((void**)&a, sizeof(int) * size, cudaHostAllocDefault);// 申请页锁定内存
cudaMalloc((void**)&dev_a, sizeof(int) * size); cudaMemcpy(dev_a, a, sizeof(int) * size, cudaMemcpyHostToDevice);// 使用普通的内存拷贝
cudaMemcpy(a, dev_a, sizeof(int) * size, cudaMemcpyDeviceToHost); cudaFreeHost(a);// 释放内存
cudaFree(dev_a);
● 单流内存拷贝
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define N (1024*1024)
#define LOOP_TIMES (100) __global__ void kernel(int *a, int *b, int *c)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N)
{
int idx1 = (idx + ) % ;
int idx2 = (idx + ) % ;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / ;
}
} int main(void)
{
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream;
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c; cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaStreamCreate(&stream); cudaMalloc((void**)&dev_a, N * sizeof(int));
cudaMalloc((void**)&dev_b, N * sizeof(int));
cudaMalloc((void**)&dev_c, N * sizeof(int)); cudaHostAlloc((void**)&host_a, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, N * LOOP_TIMES * sizeof(int), cudaHostAllocDefault); for (int i = ; i < N * LOOP_TIMES; i++)
{
host_a[i] = rand();
host_b[i] = rand();
} cudaEventRecord(start, );
for (int i = ; i < N * LOOP_TIMES; i += N)
{
cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream); kernel << <N / , , , stream >> >(dev_a, dev_b, dev_c); cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream);
}
cudaStreamSynchronize(stream); cudaEventRecord(stop, ); cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("\n\tTest %d times, spending time:\t%3.1f ms\n", LOOP_TIMES, elapsedTime); cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaStreamDestroy(stream);
cudaEventDestroy(start);
cudaEventDestroy(stop);
getchar();
return ;
}
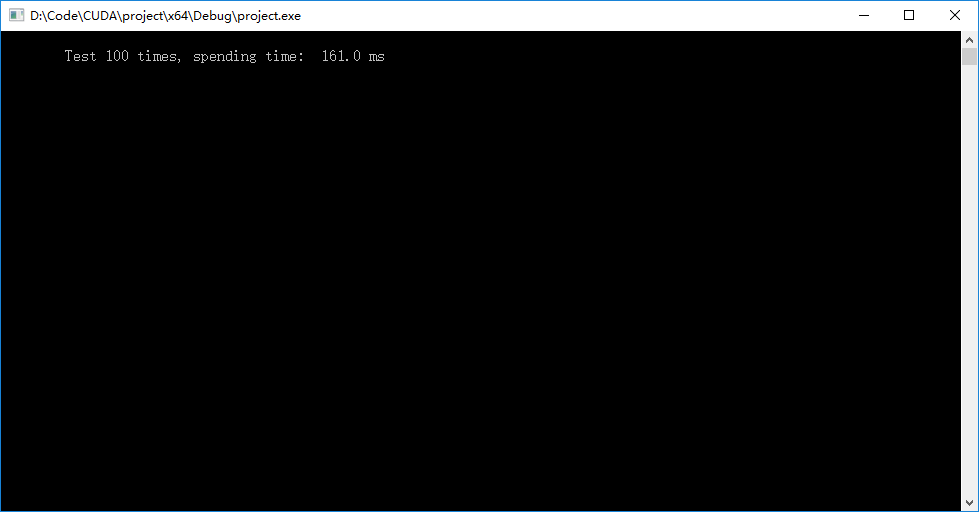
● 程序输出
● 限定流作为内存拷贝工作时要使用函数cudaMemcpyAsync(),其简单声明和使用为:
cudaError_t cudaMemcpyAsync(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream __dv()); cudaMemcpyAsync(dev_a, host_a, size, cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(host_a, dev_a, size, cudaMemcpyDeviceToHost, stream);
● 使用流的基本过程
cudaStream_t stream;// 创建流变量
int *host_a;
int *dev_a;
host_a = (int *)malloc(sizeof(int)*N);
cudaMalloc((void**)&dev_a, N * sizeof(int)); cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);// 采用异步内存拷贝 kernel << <blocksize, threadsize, stream >> > (dev_a);// 执行核函数,注意标记流编号 cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream);/ cudaStreamSynchronize(stream);// 流同步,保证该留内的工作全部完成 free(a);// 释放内存和销毁流变量
cudaFree(dev_a);
cudaStreamDestroy(stream);
● 双流内存拷贝
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define N (1024*1024)
#define LOOP_TIMES (100)
#define NAIVE true __global__ void kernel(int *a, int *b, int *c)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N)
{
int idx1 = (idx + ) % ;
int idx2 = (idx + ) % ;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / ;
}
} int main(void)
{
cudaEvent_t start, stop;
float elapsedTime;
cudaStream_t stream0, stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1; cudaEventCreate(&start);
cudaEventCreate(&stop); cudaStreamCreate(&stream0);
cudaStreamCreate(&stream1); cudaMalloc((void**)&dev_a0,N * sizeof(int));
cudaMalloc((void**)&dev_b0,N * sizeof(int));
cudaMalloc((void**)&dev_c0,N * sizeof(int));
cudaMalloc((void**)&dev_a1,N * sizeof(int));
cudaMalloc((void**)&dev_b1,N * sizeof(int));
cudaMalloc((void**)&dev_c1,N * sizeof(int)); cudaHostAlloc((void**)&host_a, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, N * LOOP_TIMES * sizeof(int),cudaHostAllocDefault); for (int i = ; i < N * LOOP_TIMES; i++)
{
host_a[i] = rand();
host_b[i] = rand();
}
printf("\n\tArray initialized!"); cudaEventRecord(start, );
for (int i = ; i < N * LOOP_TIMES; i += N * )// 每次吃两个N的长度
{
#if NAIVE
cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int),cudaMemcpyHostToDevice,stream0);// 前半段给dev_a0和dev_b0
cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int),cudaMemcpyHostToDevice,stream0); kernel << <N / , , , stream0 >> >(dev_a0, dev_b0, dev_c0); cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int),cudaMemcpyDeviceToHost,stream0); cudaMemcpyAsync(dev_a1, host_a + i + N,N * sizeof(int),cudaMemcpyHostToDevice,stream1);//后半段给dev_a1和dev_b1
cudaMemcpyAsync(dev_b1, host_b + i + N,N * sizeof(int),cudaMemcpyHostToDevice,stream1); kernel << <N / , , , stream1 >> >(dev_a1, dev_b1, dev_c1); cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int),cudaMemcpyDeviceToHost,stream1);
#else
cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);// 两个半段拷贝任务
cudaMemcpyAsync(dev_a1, host_a + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);// 两个半段拷贝任务
cudaMemcpyAsync(dev_b1, host_b + i + N, N * sizeof(int), cudaMemcpyHostToDevice, stream1); kernel << <N / , , , stream0 >> >(dev_a0, dev_b0, dev_c0);// 两个计算执行
kernel << <N / , , , stream1 >> >(dev_a1, dev_b1, dev_c1); cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0);// 两个半段拷贝任务
cudaMemcpyAsync(host_c + i + N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1);
#endif
}
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1); cudaEventRecord(stop, ); cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start, stop);
printf("\n\tTest %d times, spending time:\t%3.1f ms\n", LOOP_TIMES, elapsedTime); cudaFree(dev_a0);
cudaFree(dev_b0);
cudaFree(dev_c0);
cudaFree(dev_a1);
cudaFree(dev_b1);
cudaFree(dev_c1);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaStreamDestroy(stream0);
cudaStreamDestroy(stream1);
getchar();
return ;
}
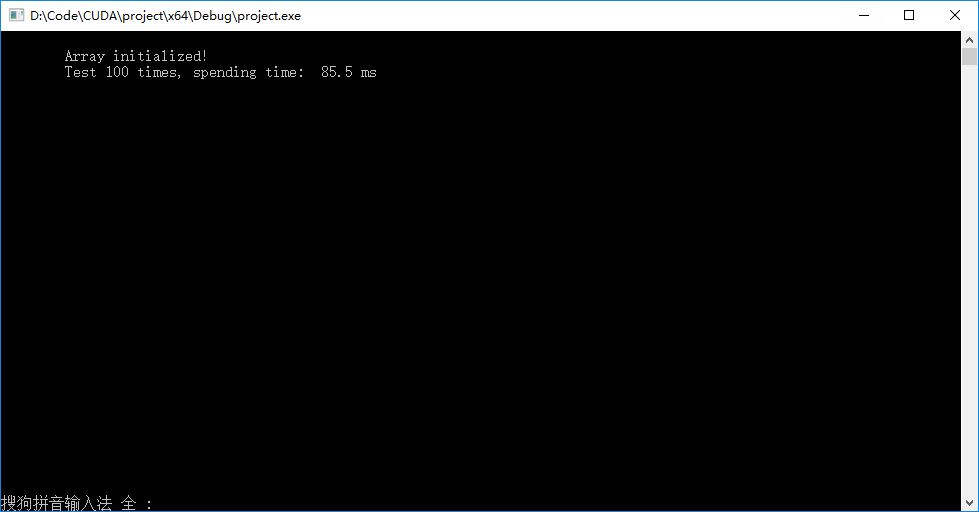
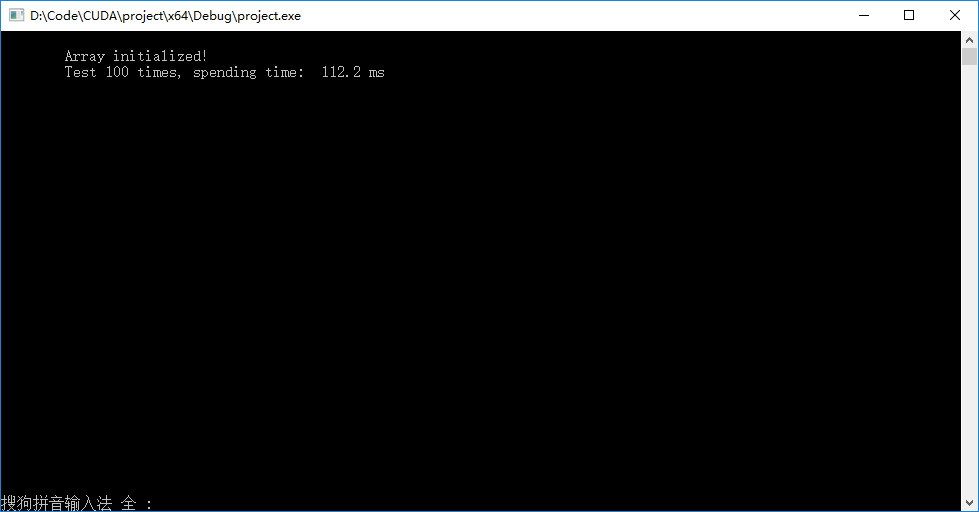
● 书上简单双流版本输出结果如下左图,异步双流版本输出结果如下右图。发现异步以后速度反而下降了。
《GPU高性能编程CUDA实战》第十章 流的更多相关文章
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- 《GPU高性能编程CUDA实战》第十一章 多GPU系统的CUDA C
▶ 本章介绍了多设备胸膛下的 CUDA 编程,以及一些特殊存储类型对计算速度的影响 ● 显存和零拷贝内存的拷贝与计算对比 #include <stdio.h> #include " ...
- 《GPU高性能编程CUDA实战》第五章 线程并行
▶ 本章介绍了线程并行,并给出四个例子.长向量加法.波纹效果.点积和显示位图. ● 长向量加法(线程块并行 + 线程并行) #include <stdio.h> #include &quo ...
- 《GPU高性能编程CUDA实战》第四章 简单的线程块并行
▶ 本章介绍了线程块并行,并给出两个例子:长向量加法和绘制julia集. ● 长向量加法,中规中矩的GPU加法,包含申请内存和显存,赋值,显存传入,计算,显存传出,处理结果,清理内存和显存.用到了 t ...
- 《GPU高性能编程CUDA实战》附录二 散列表
▶ 使用CPU和GPU分别实现散列表 ● CPU方法 #include <stdio.h> #include <time.h> #include "cuda_runt ...
- 《GPU高性能编程CUDA实战》第八章 图形互操作性
▶ OpenGL与DirectX,等待填坑. ● basic_interop #include <stdio.h> #include "cuda_runtime.h" ...
- 《GPU高性能编程CUDA实战》第七章 纹理内存
▶ 本章介绍了纹理内存的使用,并给出了热传导的两个个例子.分别使用了一维和二维纹理单元. ● 热传导(使用一维纹理) #include <stdio.h> #include "c ...
- 《GPU高性能编程CUDA实战》第六章 常量内存
▶ 本章介绍了常量内存的使用,并给光线追踪的一个例子.介绍了结构cudaEvent_t及其在计时方面的使用. ● 章节代码,大意是有SPHERES个球分布在原点附近,其球心坐标在每个坐标轴方向上分量绝 ...
- 《GPU高性能编程CUDA实战》第三章 CUDA设备相关
▶ 这章介绍了与CUDA设备相关的参数,并给出了了若干用于查询参数的函数. ● 代码(已合并) #include <stdio.h> #include "cuda_runtime ...
随机推荐
- python去掉字符串'\xa0'
AssertionError: '5\xa0e\xa0*\xa0*\xa0*\xa05' != '5e***5'mystr = '5\xa0e\xa0*\xa0*\xa0*\xa05'mystr = ...
- 洛谷 1020:导弹拦截(DP,LIS)
题目描述 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能高于前一发的高度.某天,雷达捕捉到敌国的导弹 ...
- Codeforces Round #224 (Div. 2) A. Ksenia and Pan Scales
A. Ksenia and Pan Scales time limit per test 1 second memory limit per test 256 megabytes input stan ...
- 初次实践数据库--SQL Server2016
初学数据库使用 安装了SQL Server2016的开发者版本,本来以为就可以愉快地开始数据库的挖坑了,发现开出来之后除了创建数据库.选择数据库以外,并没有什么操作. 后来才发现还需要再安装SSMS( ...
- hdu2098 分拆素数和 素数筛
将一个偶数拆成两个素数的和,欧拉筛暴力 #include<stdio.h> #include<string.h> #define N 10001 ]; ]; ,j; void ...
- LG1955 [NOI2015]程序自动分析
题意 题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考虑一个约束满足问题的简化版本:假设x1,x2,x3...代表程序中出现的变量,给定n个形如xi=xj或xi≠x ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- SQL 存储过程入门(五)
好久没来博客园留下点东西,忙到找工作,最近把工作落实了. 最近公司的业务都是存储过程开发,发现去维护起来相当困难. 由于是维护项目,产品很久前都发布了,然而有一些修改,让我们去修改现在的逻辑,去看懂人 ...
- SQL语言:DDL/DML/DQL/DCL
SQL (Structure Query Language)语言是数据库的核心语言. SQL 的发展是从1974年开始的,其发展过程如下: 1974年-----由Boyce和Chamberlin提出, ...
- tomcat和servlet关系
https://blog.csdn.net/weixin_30531261/article/details/78574410 图不错:https://www.cnblogs.com/fengli999 ...