《GPU高性能编程CUDA实战》第十一章 多GPU系统的CUDA C
▶ 本章介绍了多设备胸膛下的 CUDA 编程,以及一些特殊存储类型对计算速度的影响
● 显存和零拷贝内存的拷贝与计算对比
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define imin(a,b) (a<b?a:b)
#define SIZE (33 * 1024 * 1024) const int threadsPerBlock = ;
const int blocksPerGrid = imin(, (SIZE + threadsPerBlock - ) / threadsPerBlock); __global__ void dot(int size, float *a, float *b, float *c)//分段计算点积写入全局内存
{
__shared__ float share[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x; float temp = ;
while (tid < size)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
} share[cacheIndex] = temp;
__syncthreads(); int i = blockDim.x / ;
while (i != )
{
if (cacheIndex < i)
share[cacheIndex] += share[cacheIndex + i];
__syncthreads();
i /= ;
}
if (cacheIndex == )
c[blockIdx.x] = share[]; return;
} void malloc_test()// 利用显存进行计算
{
cudaEvent_t start, stop;
float *a, *b, *partial_c, c;
float *dev_a, *dev_b, *dev_partial_c;
float elapsedTime; cudaEventCreate(&start);
cudaEventCreate(&stop); a = (float*)malloc(SIZE * sizeof(float));
b = (float*)malloc(SIZE * sizeof(float));
partial_c = (float*)malloc(blocksPerGrid * sizeof(float));
cudaMalloc((void**)&dev_a,SIZE * sizeof(float));
cudaMalloc((void**)&dev_b,SIZE * sizeof(float));
cudaMalloc((void**)&dev_partial_c,blocksPerGrid * sizeof(float)); for (int i = ; i<SIZE; i++)
{
a[i] = i;
b[i] = i * ;
} cudaEventRecord(start, ); cudaMemcpy(dev_a, a, SIZE * sizeof(float),cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, SIZE * sizeof(float),cudaMemcpyHostToDevice); dot << <blocksPerGrid, threadsPerBlock >> >(SIZE, dev_a, dev_b,dev_partial_c); cudaMemcpy(partial_c, dev_partial_c,blocksPerGrid * sizeof(float),cudaMemcpyDeviceToHost); cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start, stop); c = ;
for (int i = ; i < blocksPerGrid; c += partial_c[i], i++); free(a);
free(b);
free(partial_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
cudaEventDestroy(start);
cudaEventDestroy(stop); printf("cudaMalloc, time:\t%3.1f ms,value:\t%f\n", elapsedTime, c);
return;
} void cuda_host_alloc_test()// 利用零拷贝内存进行计算
{
cudaEvent_t start, stop;
float *a, *b, *partial_c, c;
float *dev_a, *dev_b, *dev_partial_c;
float elapsedTime; cudaEventCreate(&start);
cudaEventCreate(&stop); cudaHostAlloc((void**)&a,SIZE * sizeof(float),cudaHostAllocWriteCombined |cudaHostAllocMapped);
cudaHostAlloc((void**)&b,SIZE * sizeof(float),cudaHostAllocWriteCombined |cudaHostAllocMapped);
cudaHostAlloc((void**)&partial_c,blocksPerGrid * sizeof(float),cudaHostAllocMapped);
cudaHostGetDevicePointer(&dev_a, a, );
cudaHostGetDevicePointer(&dev_b, b, );
cudaHostGetDevicePointer(&dev_partial_c,partial_c, ); for (int i = ; i < SIZE; i++)
{
a[i] = i;
b[i] = i * ;
} cudaEventRecord(start, ); dot << <blocksPerGrid, threadsPerBlock >> > (SIZE, dev_a, dev_b, dev_partial_c);
cudaThreadSynchronize(); cudaEventRecord(stop, );
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime,start, stop); c = ;
for (int i = ; i < blocksPerGrid; c += partial_c[i], i++); cudaFreeHost(a);
cudaFreeHost(b);
cudaFreeHost(partial_c);
cudaEventDestroy(start);
cudaEventDestroy(stop); printf("cudaHostAlloc, time:\t%3.1f ms,value:\t%f\n", elapsedTime, c);
return;
} int main(void)
{
cudaSetDeviceFlags(cudaDeviceMapHost); malloc_test();
cuda_host_alloc_test(); getchar();
return;
}
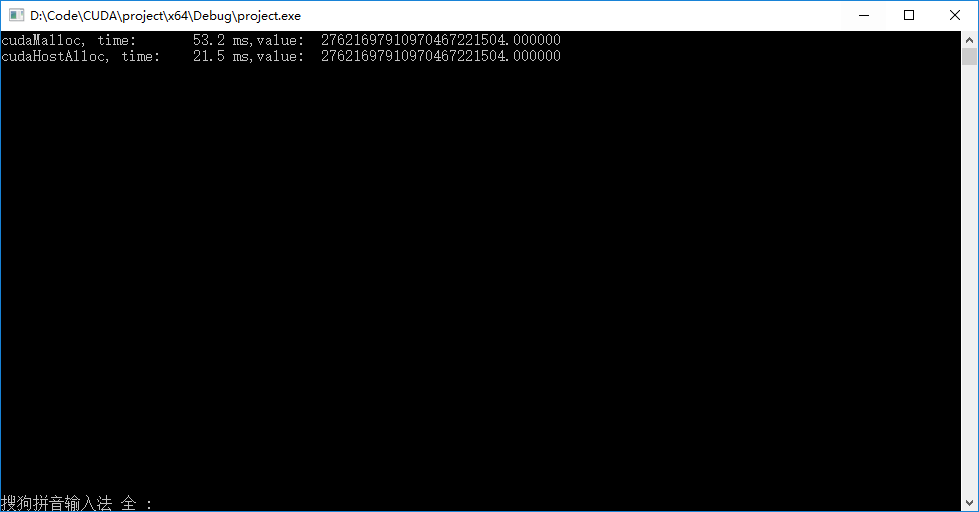
● 程序输出结果,第一行是利用显存进行计算的结果,第二行是利用零拷贝内存进行计算的结果。
● 零拷贝内存的使用过程:
float *a, *dev_a;
cudaSetDeviceFlags(cudaDeviceMapHost);// 设置内存标志,表明希望映射主机内存
cudaHostAlloc((void**)&a,SIZE * sizeof(float),cudaHostAllocWriteCombined |cudaHostAllocMapped);
//标记flag,分别是“合并式写入”和“GPU可访问”
cudaHostGetDevicePointer(&dev_a, a, );// 将内存地址映射到GPU上,以后就可以使用dev_a[n]等下标方式访问dev_a foo << <blocksize, threadsize >> > (dev_a); cudaThreadSynchronize();
cudaFreeHost(a);//释放内存
● 合并式写入不会改变应用程序的性能,却可以显著提升GPU读取内存的性能。但是如果CPU也需要读取这部分的内存时,效率较低.
●使用零拷贝内存见减小了PCIE通道的读写延迟,提高了数据访问速率。但是GPU不会缓存零拷贝内存的内容,对于需要多次读写的内存数据效率较低,不如直接在显存中存储。本例子中点积运算满足数据只访问一次的条件,所以效率提高很明显。
● 多设备并行计算(被改成了双线程)
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define imin(a,b) (a<b?a:b)
#define SIZE (33*1024*1024)
#define THREADSIZE (256)
#define BLOCKSIZE (imin(32, (SIZE / 2 + THREADSIZE - 1) / THREADSIZE)) struct DataStruct
{
int deviceID;
int size;
float *a;
float *b;
float returnValue;
}; __global__ void dot(int size, float *a, float *b, float *c)//分段计算点积写入全局内存
{
__shared__ float share[THREADSIZE];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x; float temp = ;
while (tid < size)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
} share[cacheIndex] = temp;
__syncthreads(); int i = blockDim.x / ;
while (i != )
{
if (cacheIndex < i)
share[cacheIndex] += share[cacheIndex + i];
__syncthreads();
i /= ;
}
if (cacheIndex == )
c[blockIdx.x] = share[]; return;
} void* routine(void *pvoidData)// C回调函数标准,void*型函数,传入void型的指针,再转化回原来的的格式
{
DataStruct *data = (DataStruct*)pvoidData;
cudaSetDevice(data->deviceID); int i;
float *partial_c, c;
float *dev_a, *dev_b, *dev_partial_c; partial_c = (float*)malloc(BLOCKSIZE * sizeof(float));
cudaMalloc((void**)&dev_a, data->size * sizeof(float));
cudaMalloc((void**)&dev_b, data->size * sizeof(float));
cudaMalloc((void**)&dev_partial_c, BLOCKSIZE * sizeof(float)); cudaMemcpy(dev_a, data->a, data->size * sizeof(float),cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, data->b, data->size * sizeof(float),cudaMemcpyHostToDevice); dot << <BLOCKSIZE, THREADSIZE >> > (data->size, dev_a, dev_b, dev_partial_c); cudaMemcpy(partial_c, dev_partial_c, BLOCKSIZE * sizeof(float),cudaMemcpyDeviceToHost); for (i = ,c=; i < BLOCKSIZE; c += partial_c[i], i++); free(partial_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c); data->returnValue = c;
printf("\n\troutine finished!");
return NULL;
} int main(void)
{
float *a = (float*)malloc(sizeof(float) * SIZE);//公用的输入数组
float *b = (float*)malloc(sizeof(float) * SIZE); for (int i = ; i < SIZE; i++)
{
a[i] = i;
b[i] = i * ;
} DataStruct data[];
data[].deviceID = ;
data[].size = SIZE / ;
data[].a = a;
data[].b = b;
data[].deviceID = ;//源代码中这里等于1,使用第二台设备进行计算
data[].size = SIZE / ;
data[].a = a + SIZE / ;
data[].b = b + SIZE / ; // 使用CreateThread()创建新线程来分配计算
HANDLE thread = CreateThread(NULL, , (PTHREAD_START_ROUTINE)routine, &(data[]), , NULL);
routine(&(data[])); WaitForSingleObject(thread, INFINITE);// 等待和关闭线程
CloseHandle(thread); free(a);
free(b); printf("\n\tValue calculated: %f\n",data[].returnValue + data[].returnValue);
getchar();
return ;
}
● 关于创建和销毁线程:
HANDLE thread = CreateThread(NULL, , (PTHREAD_START_ROUTINE)routine, &(data[]), , NULL);
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread); static HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpsa,//
DWORD dwStackSize,// 堆栈大小
LPTHREAD_START_ROUTINE pfnThreadProc,// 线程过程
void* pvParam,// 需要传递的线程参数
DWORD dwCreationFlags,// 创建标志,0或CREATE_SUSPENDED
DWORD* pdwThreadId// 接收新线程的线程ID_WORD变量地址
) throw();// 函数不会抛出异常 WaitForSingleObject(thread, INFINITE);
// 第1个参数为线程句柄
// 第2个参数为最小等待时间,可取INFINITE HANDLE list[N];
WaitForMultipleObjects(N, list, , );
// 第1个参数为线程个数
// 第2个参数为句柄列表
// 第3个参数为等待状态,0表示等待所有线程结束再继续,1表示一旦有线程结束或到达等待时间就继续
// 第4个参数为最小等待时间
● 使用可移动内存进行多设备并行计算(被改成了双线程)
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define imin(a,b) (a<b?a:b)
#define SIZE (33*1024*1024)
#define THREADSIZE (256)
#define BLOCKSIZE (imin(32, (SIZE / 2 + THREADSIZE - 1) / THREADSIZE)) struct DataStruct
{
int deviceID;
int size;
float *a;
float *b;
float returnValue;
}; __global__ void dot(int size, float *a, float *b, float *c)//分段计算点积写入全局内存
{
__shared__ float share[THREADSIZE];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x; float temp = ;
while (tid < size)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
} share[cacheIndex] = temp;
__syncthreads(); int i = blockDim.x / ;
while (i != )
{
if (cacheIndex < i)
share[cacheIndex] += share[cacheIndex + i];
__syncthreads();
i /= ;
}
if (cacheIndex == )
c[blockIdx.x] = share[]; return;
} void* routine(void *pvoidData)
{
DataStruct *data = (DataStruct*)pvoidData;
cudaSetDevice(data->deviceID);
if (data->deviceID != )// 若使用新设备,则要设置内存地址映射(在我的电脑上这部分不会被运行)
cudaSetDeviceFlags(cudaDeviceMapHost); int i;
float *partial_c, c;
float *dev_a, *dev_b, *dev_partial_c; partial_c = (float*)malloc(BLOCKSIZE * sizeof(float));
cudaHostGetDevicePointer(&dev_a, data->a, );
cudaHostGetDevicePointer(&dev_b, data->b, );
cudaMalloc((void**)&dev_partial_c, BLOCKSIZE * sizeof(float)); dot << <BLOCKSIZE, THREADSIZE >> > (data->size, dev_a, dev_b, dev_partial_c); cudaMemcpy(partial_c, dev_partial_c, BLOCKSIZE * sizeof(float), cudaMemcpyDeviceToHost); for (i = , c = ; i < BLOCKSIZE; c += partial_c[i], i++); free(partial_c);
cudaFree(dev_partial_c); data->returnValue = c;
printf("\n\tRoutine finished!");
return ;
} int main(void)
{
float *a, *b;
cudaSetDevice();
cudaSetDeviceFlags(cudaDeviceMapHost);
cudaHostAlloc((void**)&a, SIZE * sizeof(float),cudaHostAllocWriteCombined |cudaHostAllocPortable |cudaHostAllocMapped);
cudaHostAlloc((void**)&b, SIZE * sizeof(float),cudaHostAllocWriteCombined |cudaHostAllocPortable |cudaHostAllocMapped); for (int i = ; i < SIZE; i++)
{
a[i] = i;
b[i] = i * ;
} DataStruct data[];
data[].deviceID = ;
data[].size = SIZE / ;
data[].a = a;
data[].b = b;
data[].deviceID = ;
data[].size = SIZE / ;
data[].a = a + SIZE / ;
data[].b = b + SIZE / ; HANDLE thread = CreateThread(NULL, , (PTHREAD_START_ROUTINE)routine, &(data[]), , NULL);
routine(&(data[]));
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread); cudaFreeHost(a);
cudaFreeHost(b); printf("\n\tValue calculated: %f\n",data[].returnValue + data[].returnValue);
getchar();
return ;
}
● 可移动内存说明:“固定内存”是针对线程而言的,也就是说除了申请该固定内存的县城以外其他线程不能将其看作固定内存,而是可分页内存。这时需要添加固定内存的“可移动”属性,使得所有线程都将该段内存看做固定内存。
● 可移动内存的使用
float *a;
cudaSetDeviceFlags(cudaDeviceMapHost);// 设置内存标志,表明希望映射主机内存
cudaHostAlloc((void**)&a, SIZE * sizeof(float), cudaHostAllocWriteCombined | cudaHostAllocPortable | cudaHostAllocMapped);
// 增加标记“可移动内存” cudaSetDeviceFlags(cudaDeviceMapHost);
// 在其他设备中使用这部分内存时需要再次声明内存标志 cudaFreeHost(a);
《GPU高性能编程CUDA实战》第十一章 多GPU系统的CUDA C的更多相关文章
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- 《GPU高性能编程CUDA实战》第五章 线程并行
▶ 本章介绍了线程并行,并给出四个例子.长向量加法.波纹效果.点积和显示位图. ● 长向量加法(线程块并行 + 线程并行) #include <stdio.h> #include &quo ...
- 《GPU高性能编程CUDA实战》第四章 简单的线程块并行
▶ 本章介绍了线程块并行,并给出两个例子:长向量加法和绘制julia集. ● 长向量加法,中规中矩的GPU加法,包含申请内存和显存,赋值,显存传入,计算,显存传出,处理结果,清理内存和显存.用到了 t ...
- 《GPU高性能编程CUDA实战》第七章 纹理内存
▶ 本章介绍了纹理内存的使用,并给出了热传导的两个个例子.分别使用了一维和二维纹理单元. ● 热传导(使用一维纹理) #include <stdio.h> #include "c ...
- 《GPU高性能编程CUDA实战》第六章 常量内存
▶ 本章介绍了常量内存的使用,并给光线追踪的一个例子.介绍了结构cudaEvent_t及其在计时方面的使用. ● 章节代码,大意是有SPHERES个球分布在原点附近,其球心坐标在每个坐标轴方向上分量绝 ...
- 《GPU高性能编程CUDA实战》第三章 CUDA设备相关
▶ 这章介绍了与CUDA设备相关的参数,并给出了了若干用于查询参数的函数. ● 代码(已合并) #include <stdio.h> #include "cuda_runtime ...
- 《GPU高性能编程CUDA实战》第九章 原子性
▶ 本章介绍了原子操作,给出了基于原子操作的直方图计算的例子. ● 章节代码 #include <stdio.h> #include "cuda_runtime.h" ...
- 《GPU高性能编程CUDA实战中文》中第四章的julia实验
在整个过程中出现了各种问题,我先将我调试好的真个项目打包,提供下载. /* * Copyright 1993-2010 NVIDIA Corporation. All rights reserved. ...
- 《GPU高性能编程CUDA实战》附录二 散列表
▶ 使用CPU和GPU分别实现散列表 ● CPU方法 #include <stdio.h> #include <time.h> #include "cuda_runt ...
随机推荐
- vue components
https://github.com/vuejs/awesome-vue#components--libraries
- test20181005 序列
题意 考场30分 维护差值,考虑每次移动的变更,当前2-n位置上的差加1,1位置上的差减n-1. 然后要求的是绝对值的和,用吉司机线段树维护最大最小值.次大次小值. 期望复杂度\(O(n \log n ...
- nyoj 三个水杯
三个水杯 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 给出三个水杯,大小不一,并且只有最大的水杯的水是装满的,其余两个为空杯子.三个水杯之间相互倒水,并且水杯没有标识,只 ...
- MOSFET 线路 12V 无法工作的问题(等待回复)
问题: ˇ星空-北京:5V的时候,MOS管可以关断:12V的时候关不断: 初步判断在 Q4 上,先建议按以下方式测量数据. (Excel 文件) 等待回复. 参考链接:http://blog.51ct ...
- springboot 知识点
---恢复内容开始--- 1springBoot项目引入方式, 1,继承自父 project (需要没有付项目才能用,一般我们的项目都会有 父 项目 所以 这种方式不推荐 ,记住有这种方式 就可以了) ...
- JS怎么把字符串数组转换成整型数组
今天在学习highcharts时,遇到了一个把字符串数组转换为整形数组的问题,拿在这里讨论一下: 比如有一个字符串: var dataStr="1,2,3,4,5"; 现在需要把它 ...
- 【Spring学习笔记-MVC-7】Spring MVC模型对象-模型属性讲解
作者:ssslinppp 来自为知笔记(Wiz) 附件列表 处理模型数据.png
- 【Spring学习笔记-MVC-4】SpringMVC返回Json数据-方式2
<Spring学习笔记-MVC>系列文章,讲解返回json数据的文章共有3篇,分别为: [Spring学习笔记-MVC-3]SpringMVC返回Json数据-方式1:http://www ...
- 垃圾收集器之:G1收集器
G1垃圾收集器是一种工作在堆内不同分区上的并发收集器.分区既可以归属于老年代,也可以归属新生代,同一个代的分区不需要保持连续.为老年代设计分区的初衷是我们发现并发后台线程在回收老年代中没有引用的对象时 ...
- [转]Windows 注册自定义的协议
[转自] http://blog.sina.com.cn/s/blog_86e4a51c01010nik.html 1.注册应用程序来处理自定义协议 你必须添加一个新的key以及相关的value到HK ...