HBase-1集群安装部署
1.1 准备安装包
下载安装包并上传到hadoop01服务器
安装包下载地址:
https://www.apache.org/dyn/closer.lua/hbase/2.2.6/hbase-2.2.6-bin.tar.gz将安装包上传到node01服务器/bigdata/softwares路径下,并进行解压
[hadoop@hadoop01 ~]$ cd /bigdata/soft/
[hadoop@hadoop01 soft]$ tar -zxvf hbase-2.2.6-bin.tar.gz -C /bigdata/install/
1.2 修改HBase配置文件
1.2.1 hbase-env.sh
- 修改文件
[hadoop@hadoop01 softwares]$ cd /bigdata/install/hbase-2.2.6/conf
[hadoop@hadoop01 conf]$ vi hbase-env.sh
- 修改如下两项内容,值如下
export JAVA_HOME=/bigdata/install/jdk1.8.0_141
export HBASE_MANAGES_ZK=false
1.2.2 hbase-site.xml
- 修改文件
[hadoop@hadoop01 conf]$ vi hbase-site.xml
- 内容如下
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:8020/hbase</value>
</property>
<!-- 指定hbase是否分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03:2181</value>
</property>
<!--指定hbase管理页面-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
1.2.3 regionservers
- 修改文件
[hadoop@hadoop01 conf]$ vi regionservers
- 指定HBase集群的从节点;原内容清空,添加如下三行
hadoop01
hadoop02
hadoop03
1.2.4 back-masters
- 创建backup-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
[hadoop@hadoop01 conf]$ vi backup-masters
- 将hadoop03作为备份的HMaster节点,问价内容如下
hadoop03
1.3 分发安装包
- 将 hadoop01上的HBase安装包,拷贝到其他机器上
[hadoop@hadoop01 conf]$ cd /bigdata/install
[hadoop@hadoop01 install]$ xsync hbase-2.2.6/
1.4 创建软连接
注意:三台机器均做如下操作
因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们三台机器都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /bigdata/install/hadoop-3.1.4/etc/hadoop/core-site.xml /bigdata/install/hbase-2.2.6/conf/core-site.xml
ln -s /bigdata/install/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /bigdata/install/hbase-2.2.6/conf/hdfs-site.xml
- 执行完后,出现如下效果,以hadoop02为例
1.5 添加HBase环境变量
- 注意:三台机器均执行以下命令,添加环境变量
sudo vi /etc/profile
- 文件末尾添加如下内容
export HBASE_HOME=/bigdata/install/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin
- 重新编译/etc/profile,让环境变量生效
source /etc/profile
1.6 HBase的启动与停止
- 需要提前启动HDFS及ZooKeeper集群
- 如果没开启hdfs,请在node01运行
start-dfs.sh命令 - 如果没开启zookeeper,请在3个节点分别运行
zkServer.sh start命令
- 如果没开启hdfs,请在node01运行
- 第一台机器hadoop01(HBase主节点)执行以下命令,启动HBase集群
[hadoop@hadoop01 ~]$ start-hbase.sh
启动完后,jps查看HBase相关进程
hadoop01、hadoop03上有进程HMaster、HRegionServer
hadoop02上有进程HRegionServer
1.7 访问WEB页面
浏览器页面访问
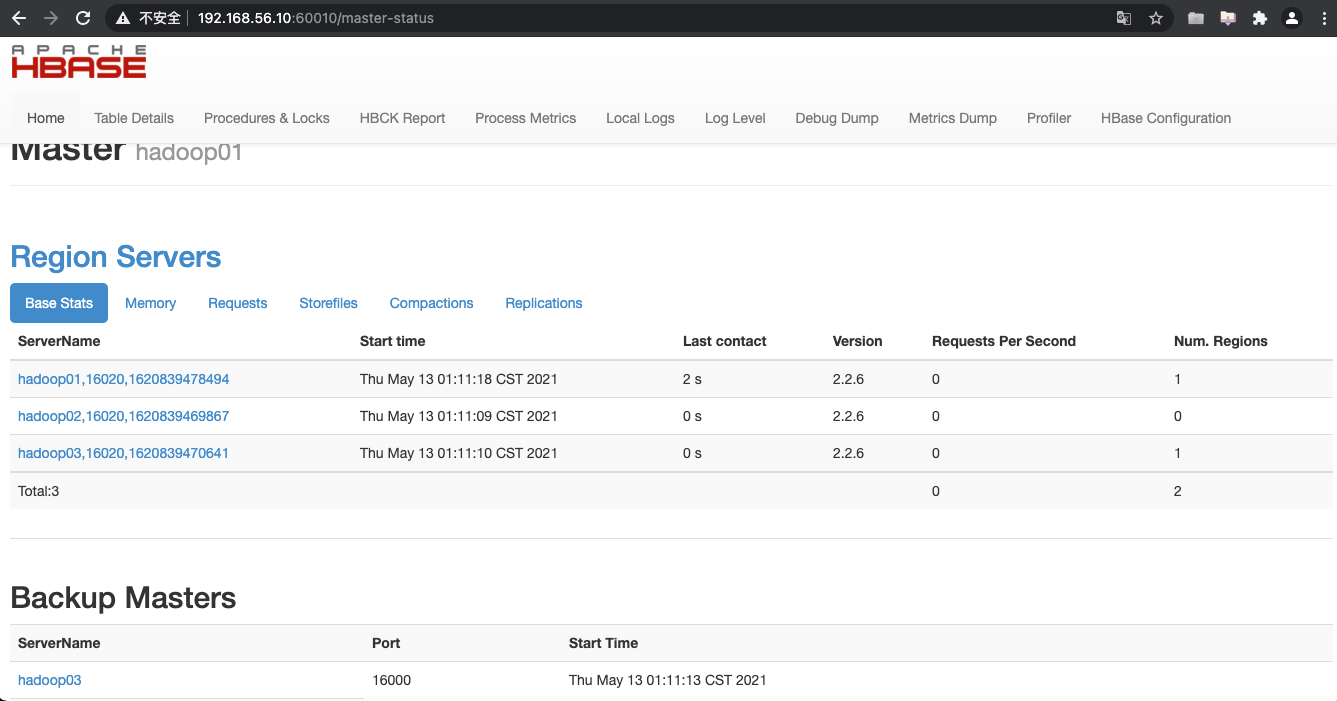
1.8 停止HBase集群
停止HBase集群的正确顺序
- hadoop01上运行,关闭hbase集群
[hadoop@hadoop01 ~]$ stop-hbase.sh
SHELL 复制 全屏- 关闭ZooKeeper集群
- 关闭Hadoop集群
- 关闭虚拟机
- 关闭笔记本
HBase整体架构
HBASE整体架构如下图
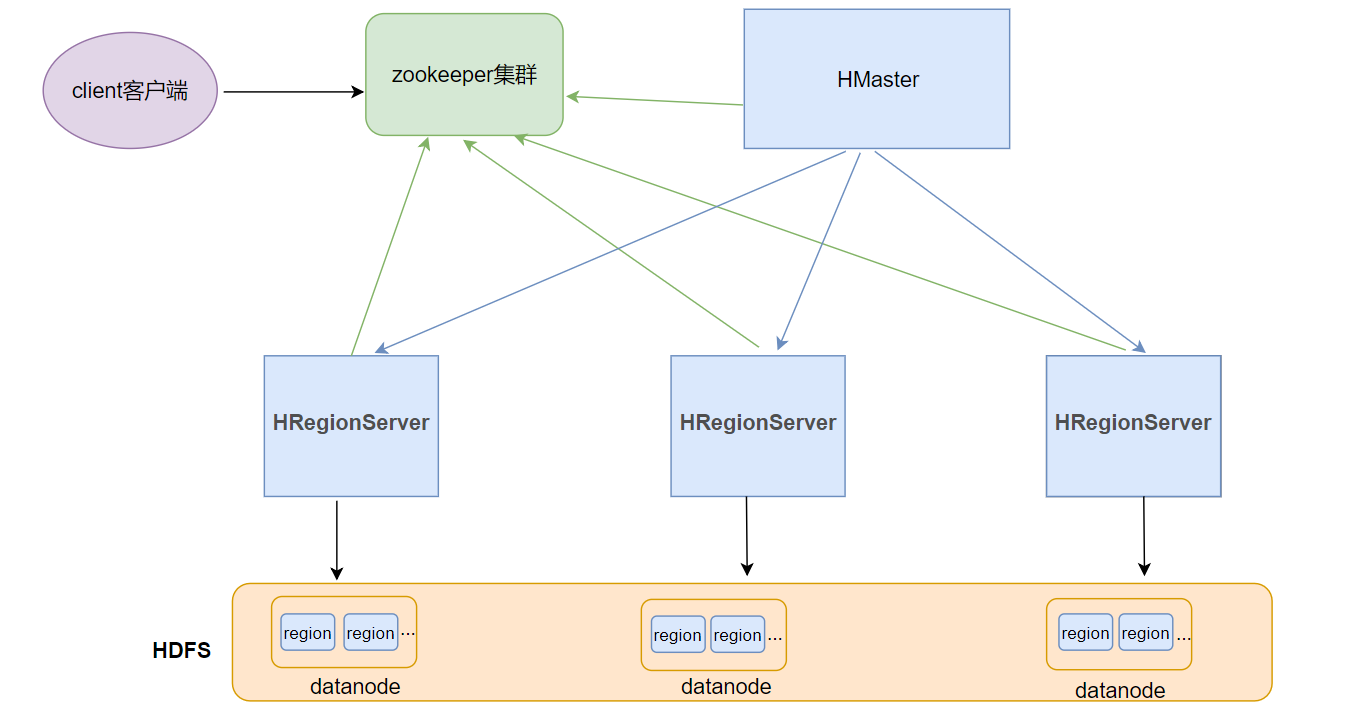
Client客户端
- Client是操作HBase集群的入口
- 对于管理类的操作,如表的增、删、改操纵,Client通过RPC与HMaster通信完成
- 对于表数据的读写操作,Client通过RPC与RegionServer交互,读写数据
- Client类型:
- HBase shell
- Java编程接口
- Thrift、Avro、Rest等等
ZooKeeper集群
- 作用
- 实现了HMaster的高可用,多HMaster间进行主备选举
- 保存了HBase的元数据信息meta表,提供了HBase表中region的寻址入口的线索数据
- 对HMaster和HRegionServer实现了监控
HMaster
- HBase集群也是主从架构,HMaster是主的角色,是老大
- 主要负责Table表和Region的相关管理工作:
- 关于Table
- 管理Client对Table的增删改的操作
- 关于Region
- 在Region分裂后,负责新Region分配到指定的HRegionServer上
- 管理HRegionServer间的负载均衡,迁移region分布
- 当HRegionServer宕机后,负责其上的region的迁移
HRegionServer
- HBase集群中从的角色,是小弟
- 作用
- 响应客户端的读写数据请求
- 负责管理一系列的Region
- 切分在运行过程中变大的region
Region
- HBase集群中分布式存储的最小单元
- 一个Region对应一个Table表的部分数据
HBase shell 命令基本操作
进入HBase客户端命令操作界面
- hadoop1执行以下命令,进入HBase的shell客户端
cd /bigdata/install/hbase-2.2.6/
bin/hbase shell
help 帮助命令
help
# 查看具体命令的帮助信息
help 'create'
list 查看有哪些表
- 查看当前数据库中有哪些表
list
create 创建表
- 创建user表,包含info、data两个列族
- 使用create命令
create 'user', 'info', 'data'
#或者
create 'user',{NAME => 'info', VERSIONS => '3'},{NAME => 'data'}
put 插入数据操作
- 向表中插入数据
- 使用put命令
#向user表中插入信息,row key为rk0001,列族info中添加名为name的列,值为zhangsan
put 'user', 'rk0001', 'info:name', 'zhangsan'
#向user表中插入信息,row key为rk0001,列族info中添加名为gender的列,值为female
put 'user', 'rk0001', 'info:gender', 'female'
#向user表中插入信息,row key为rk0001,列族info中添加名为age的列,值为20
put 'user', 'rk0001', 'info:age', 20
#向user表中插入信息,row key为rk0001,列族data中添加名为pic的列,值为picture
put 'user', 'rk0001', 'data:pic', 'picture'
查询数据操作
1 通过rowkey进行查询
- 获取user表中row key为rk0001的所有信息(即所有cell的数据)
- 使用get命令
get 'user', 'rk0001'
2 查看rowkey下某个列族的信息
- 获取user表中row key为rk0001,info列族的所有信息
get 'user', 'rk0001', 'info'
3 查看rowkey指定列族指定字段的值
- 获取user表中row key为rk0001,info列族的name、age列的信息
get 'user', 'rk0001', 'info:name', 'info:age'
4 查看rowkey指定多个列族的信息
- 获取user表中row key为rk0001,info、data列族的信息
get 'user', 'rk0001', 'info', 'data'
#或者你也可以这样写
get 'user', 'rk0001', {COLUMN => ['info', 'data']}
#或者你也可以这样写,也行
get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}
5 指定rowkey与列值过滤器查询
- 获取user表中row key为rk0001,cell的值为zhangsan的信息
get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}
6 指定rowkey与列名模糊查询
- 获取user表中row key为rk0001,列标示符中含有a的信息
get 'user', 'rk0001', {FILTER => "QualifierFilter(=,'substring:a')"}
7 查询所有行的数据
- 查询user表中的所有信息
- 使用scan命令
scan 'user'
8 列族查询
- 查询user表中列族为info的信息
scan 'user', {COLUMNS => 'info'}
#当把某些列的值删除后,具体的数据并不会马上从存储文件中删除;查询的时候,不显示被删除的数据;如果想要查询出来的话,RAW => true
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}
scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}
9 多列族查询
- 查询user表中列族为info和data的信息
scan 'user', {COLUMNS => ['info', 'data']}
10 指定列族与某个列名查询
- 查询user表中列族为info、列标示符为name的信息
scan 'user', {COLUMNS => 'info:name'}
- 查询info:name列、data:pic列的数据
scan 'user', {COLUMNS => ['info:name', 'data:pic']}
- 查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}
11 指定多个列族与条件模糊查询
- 查询user表中列族为info和data且列标示符中含有a字符的信息
scan 'user', {COLUMNS => ['info', 'data'], FILTER => "QualifierFilter(=,'substring:a')"}
12 指定rowkey的范围查询
- 查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
scan 'user', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}
13 指定rowkey模糊查询
- 查询user表中row key以rk字符开头的数据
scan 'user',{FILTER=>"PrefixFilter('rk')"}
14 指定数据版本的范围查询
- 查询user表中指定范围的数据(前闭后开)
scan 'user', {TIMERANGE => [1392368783980, 1610288780669]}
更新数据操作
1 更新数据值
- 更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
- 使用put命令
2 更新版本号
- 将user表的info列族版本数改为5
alter 'user', NAME => 'info', VERSIONS => 5
删除数据以及删除表操作
1 指定rowkey以及列名进行删除
- 删除user表row key为rk0001,列标示符为info:name的数据
delete 'user', 'rk0001', 'info:name'
2 指定rowkey,列名以及版本号进行删除
- 删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
delete 'user', 'rk0001', 'info:name', 1392383705316
3 删除一个列族
- 删除一个列族:
alter 'user', NAME => 'data', METHOD => 'delete'
#或
alter 'user', 'delete' => 'info'
4 清空表数据
truncate 'user'
5 删除表
- 首先需要先让该表为disable状态,使用命令:
disable 'user'
- 然后使用drop命令删除这个表
drop 'user'
(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)
统计一张表有多少行数据
count 'user'HBase的高级shell管理命令
1 status
- 例如:显示服务器状态
status 'hadoop01'
2 whoami
- 显示HBase当前用户,例如:
whoami
3 list
- 显示当前所有的表
list
4 count
- 统计指定表的记录数,例如:
count 'user'
5 describe
- 展示表结构信息
describe 'user'
6 exists
- 检查表是否存在,适用于表量特别多的情况
exists 'user'
7 is_enabled、is_disabled
- 检查表是否启用或禁用
is_enabled 'user'
is_disabled 'user'
8 alter
- 该命令可以改变表和列族的模式,例如:
- 为当前表增加列族:
alter 'user', NAME => 'CF2', VERSIONS => 2
- 为当前表删除列族:
alter 'user', 'delete' => 'CF2'
9 disable/enable
- 禁用一张表/启用一张表
disable 'user'
enable 'user'
10 drop
- 删除一张表,记得在删除表之前必须先禁用
11 truncate
- 禁用表-删除表-创建表
HBase的数据存储原理
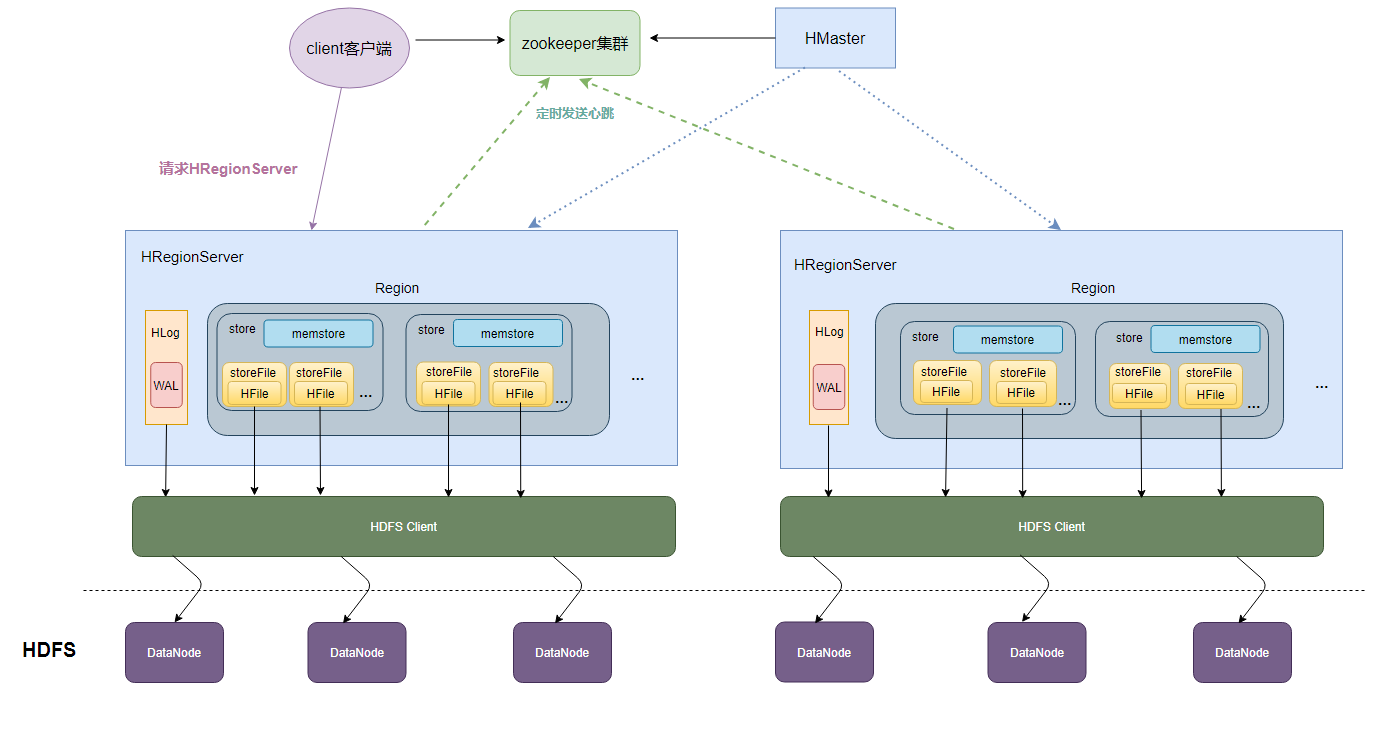
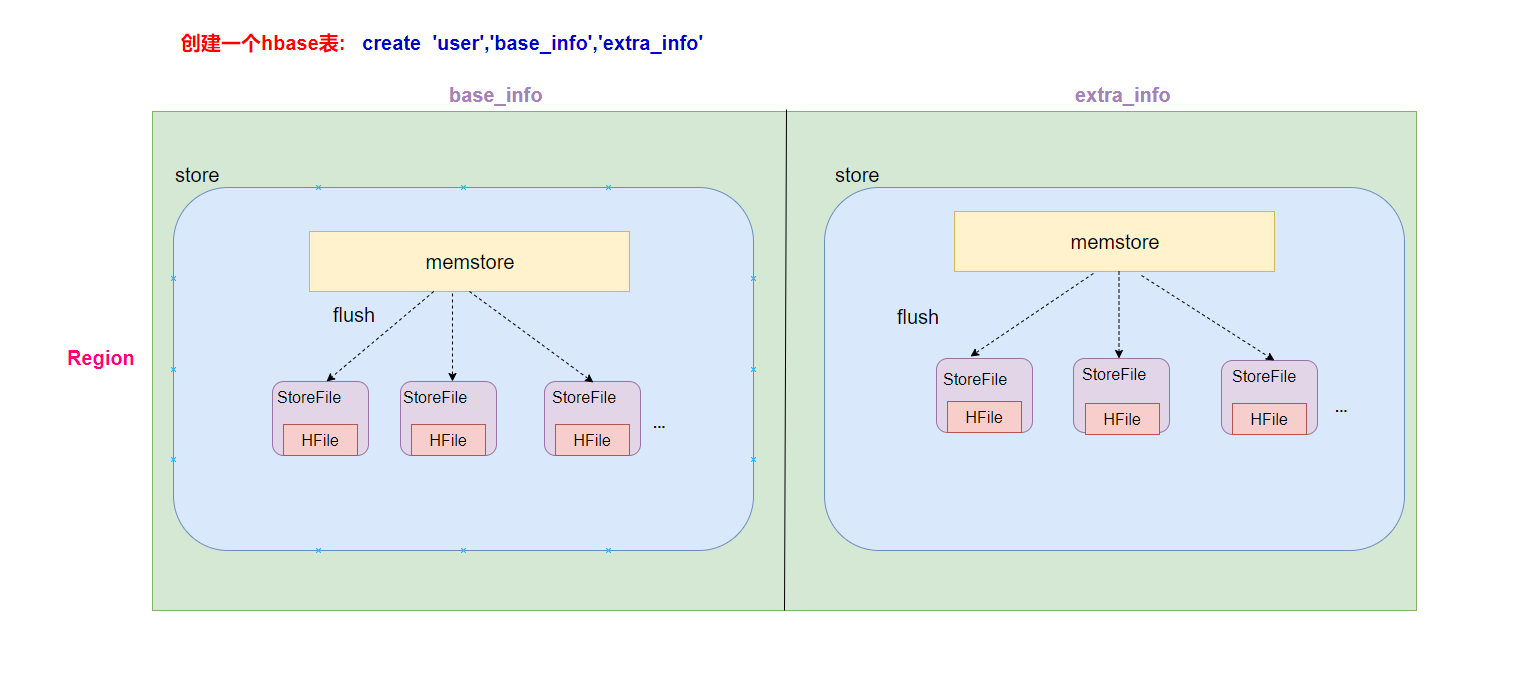
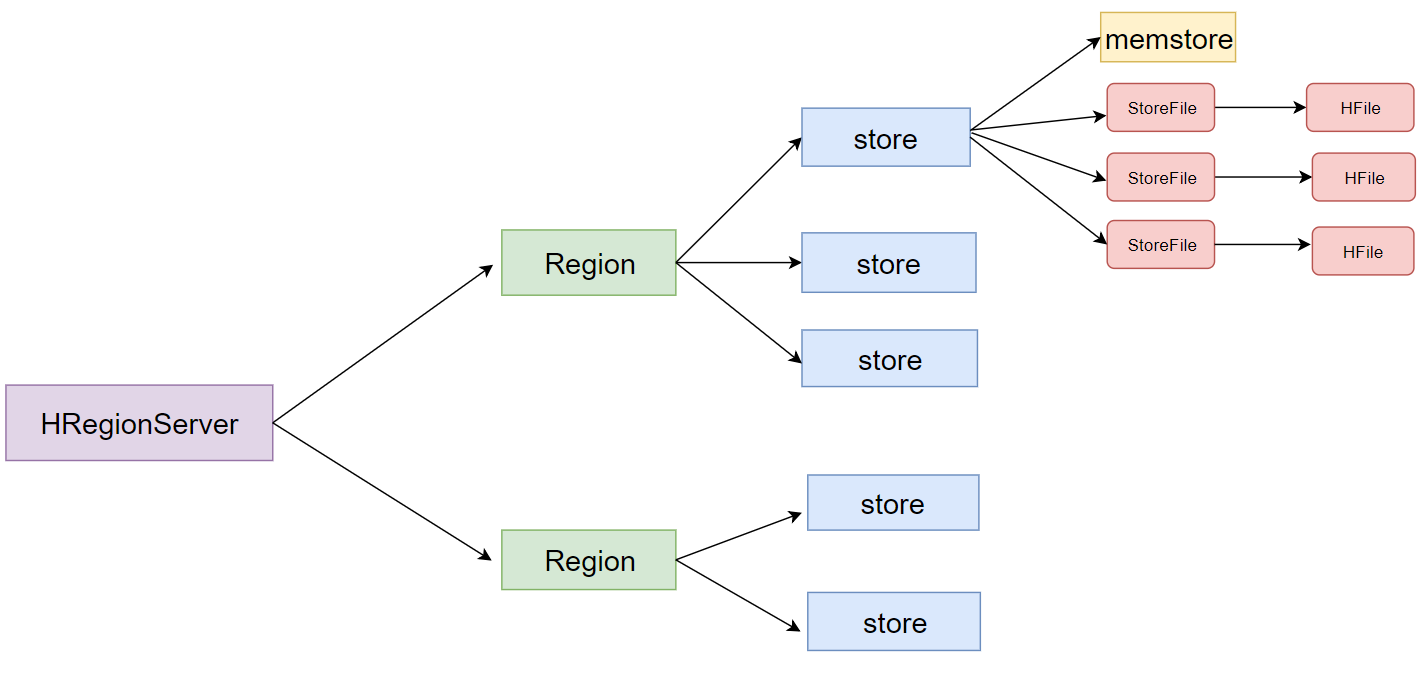
- 一个HRegionServer会负责管理很多个region
- 一个region包含很多个store
- 一个列族就划分成一个store
- 如果一个表中只有1个列族,那么这个表的每一个region中只有一个store
- 如果一个表中有N个列族,那么这个表的每一个region中有N个store
- 一个store里面只有一个memstore
- memstore是一块内存区域,写入的数据会先写入memstore进行缓冲,然后再把数据刷到磁盘
- 一个store里面有很多个StoreFile, 最后数据是以很多个HFile这种数据结构的文件保存在HDFS上
- StoreFile是HFile的抽象对象,如果说到StoreFile就等于HFile
- 每次memstore刷写数据到磁盘,就生成对应的一个新的HFile文件出来
HBase表的预分区
HBase表的预分区
- 当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。
- 解决这个问题可以用pre-splitting,在创建table的时候就配置好,生成多个region。
1 为何要预分区?
- 增加数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
- 优化Map数量
2 预分区原理
- 每一个region维护着startRowKey与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
3 手动指定预分区(三种方式)
- 方式一
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']
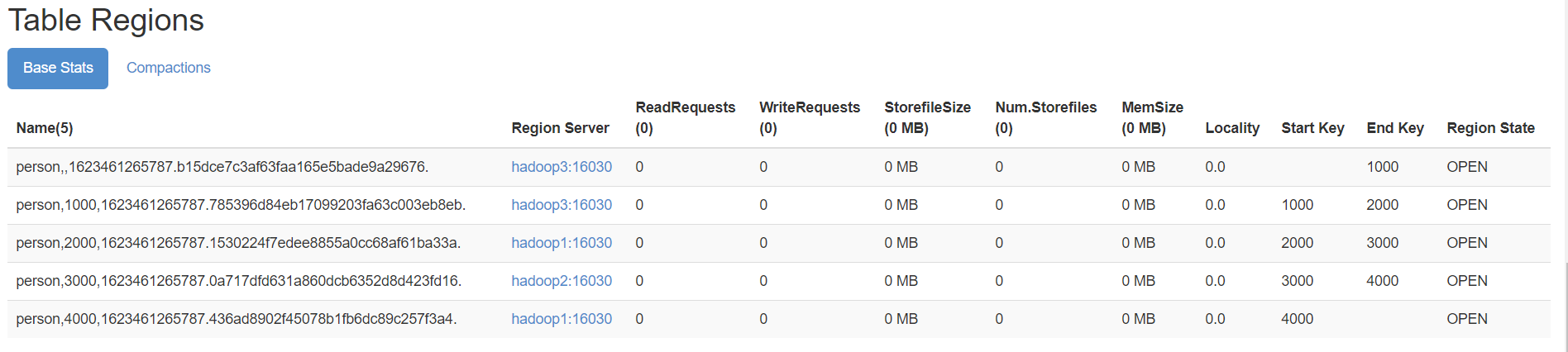
- 方式二:也可以把分区规则创建于文件中
cd /bigdata/install
vi split.txt
- 文件内容
aaa
bbb
ccc
ddd
- hbase shell中,执行命令
create 'student','info',SPLITS_FILE => '/bigdata/install/split.txt'
- 成功后查看web界面
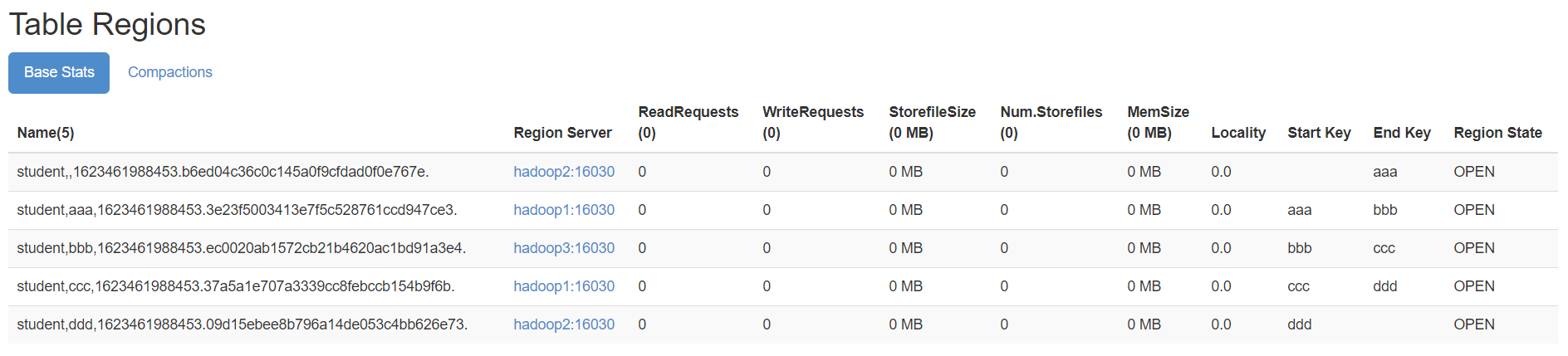
- 方式三: HexStringSplit 算法
- HexStringSplit会将数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为拆分点。
- 例如:
create 'mytable', 'base_info',' extra_info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
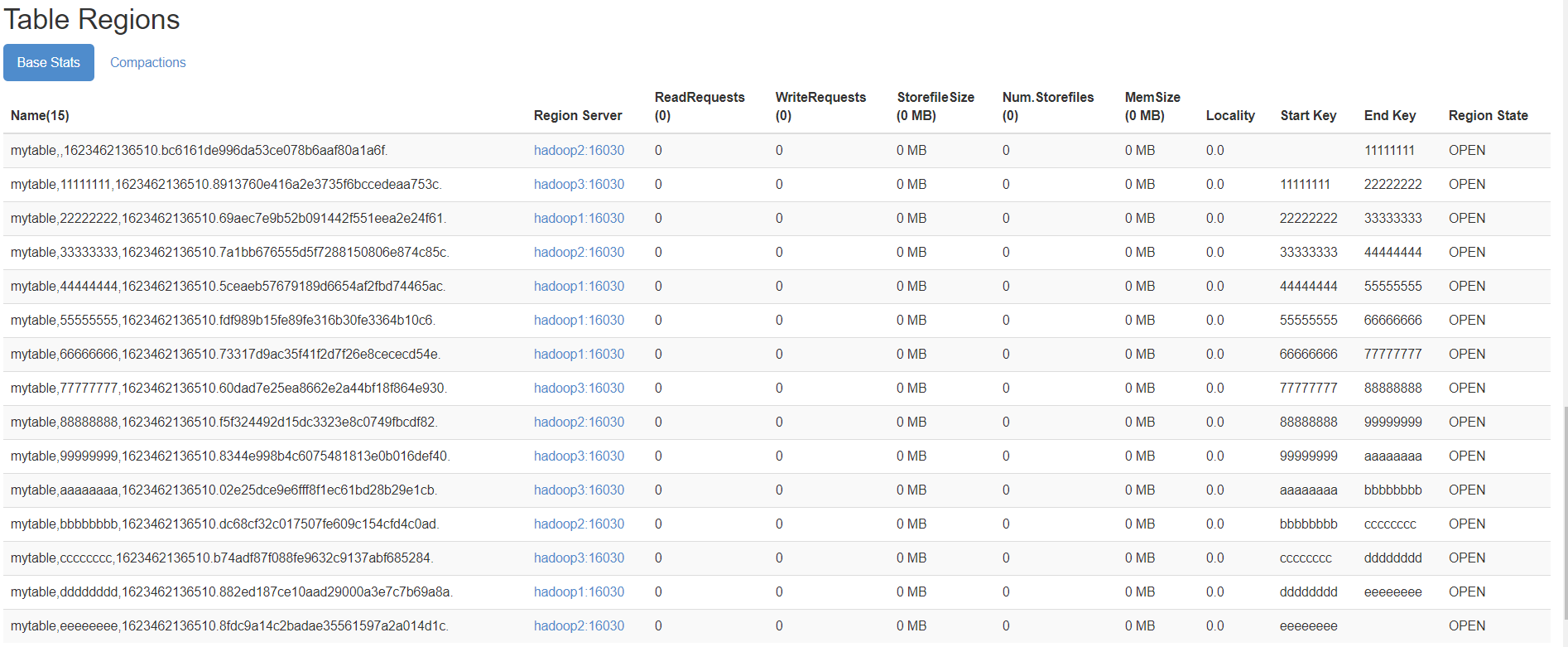
HBase Region 分裂于合并
Region 分裂
1 region分裂说明
- region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率.
- 当region过大的时候,hbase会将region拆分为两个region , 这也是Hbase的一个优点.
2 Region分裂策略
2.1 ConstantSizeRegionSplitPolicy
- 0.94版本前,HBase region的默认切分策略
- 当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
- 但是在生产线上这种切分策略却有相当大的弊端:
- 切分策略对于大表和小表没有明显的区分。
- 阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
- 如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
2.2 IncreasingToUpperBoundRegionSplitPolicy
- 0.94版本~2.0版本默认切分策略
- 总体看和ConstantSizeRegionSplitPolicy思路相同
- 一个region中最大的store大小大于设置阈值就会触发切分。
- 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.
- region split阈值的计算公式是:
- 设regioncount:是region所属表在当前regionserver上的region的个数
- 阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G);当region中最大的store的大小达到该阈值的时候进行region split
- 例如:
第一次split阈值 = 1^3 * 256 = 256MB
第二次split阈值 = 2^3 * 256 = 2048MB
第三次split阈值 = 3^3 * 256 = 6912MB
第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
后面每次split的size都是10GB了 - 特点
- 相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
- 在集群规模比较大的情况下,对大表的表现比较优秀
- 但是,它并不完美,小表可能产生大量的小region,分散在各regionserver上
2.3 SteppingSplitPolicy
- 2.0版本默认切分策略
- 相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些
- region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
- 如果region个数等于1,切分阈值为flush size 128M * 2
- 否则为MaxRegionFileSize。
- 这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
2.4 KeyPrefixRegionSplitPolicy
- 根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
2.5 DelimitedKeyPrefixRegionSplitPolicy
- 保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
2.6 DisabledRegionSplitPolicy
- 不启用自动拆分, 需要指定手动拆分
Region 合并
1 region合并说明
- Region的合并不是为了性能, 而是出于便于运维的目的 .
- 比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点
2 如何进行region合并
2.1 通过Merge类冷合并Region
执行合并前,需要先关闭hbase集群
创建一张hbase表:
create 'person','info1',SPLITS => ['1000','2000','3000','4000']
查看表region

需求:
需要把person表中的2个region数据进行合并:
person,,1623461265787.b15dce7c3af63faa165e5bade9a29676.
person,1000,1623461265787.785396d84eb17099203fa63c003eb8eb.这里通过org.apache.hadoop.hbase.util.Merge类来实现,不需要进入hbase shell,直接执行(需要先关闭hbase集群):
hbase org.apache.hadoop.hbase.util.Merge person person,,1623461265787.b15dce7c3af63faa165e5bade9a29676. person,1000,1623461265787.785396d84eb17099203fa63c003eb8eb.
成功后界面观察

2.2 通过online_merge热合并Region
不需要关闭hbase集群,在线进行合并
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分。
需求:需要把person表中的2个region数据进行合并:
person,2000,1623461265787.1530224f7edee8855a0cc68af61ba33a.
person,3000,1623461265787.0a717dfd631a860dcb6352d8d423fd16.需要进入hbase shell:
merge_region '1530224f7edee8855a0cc68af61ba33a','0a717dfd631a860dcb6352d8d423fd16'
成功后观察界面

HBase-1集群安装部署的更多相关文章
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- K8S集群安装部署
K8S集群安装部署 参考地址:https://www.cnblogs.com/xkops/p/6169034.html 1. 确保系统已经安装epel-release源 # yum -y inst ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- Hbase的集群安装
hadoop集群的搭建 搭建真正的zookeeper集群 Hbase需要安装在成功部署的Hadoop平台,并且要求Hadoop已经正常启动. 同时,HBase需要集群部署,我们分别把HBase 部署到 ...
随机推荐
- 使用Boost.asio与Boost.beast基于协程连接ws
目录 目录 前言 准备工作 实现 初始化io_context并监听信号 启动连接ws的线程并启动io_context 建立tcp链接(以下步骤皆位于ws函数中) ws握手 传输数据 效果 总结 前言 ...
- 初识cuda一文通
cuda学习博客 本文为本人cuda学习过程中的记录和理解,多参考@谭升等大佬前辈的博客,以及NVIDIA官方文档.如有错误烦请指正,如有侵权请联系删除. 0. 并行计算与计算机架构 计算机架构是并行 ...
- CF2025E Card Game 题解
太喜欢这个题了,这个题出得很启发性,我以前还没见过,于是把这个题记录下来. 题面 在伯兰最流行的纸牌游戏中,使用的是一副 \(n \times m\) 纸牌.每张牌都有两个参数:花色和等级.游戏中花色 ...
- Apache Tomcat AJP 实现负载均衡
大部分一开始接触WEB服务器的人可能和我一样对为什么有Apache又有Tomcat服务器感到奇怪(它们还都是Apache开发的呵呵),其实他们不是冗余的服务器,虽然他们都能对外提供WEB服务器,但总的 ...
- Spring MVC 3.2 技术预览(一):Servlet 3介绍,异步支持
原文地址:http://blog.springsource.org/2012/05/06/spring-mvc-3-2-preview-introducing-servlet-3-async-supp ...
- Pycharm之使用git merge合并分支
当我们在某个分支上代码开发完成,代码测试没问题后需要把分支上的代码合并到 master 分支上.这样保证 master 分支的代码永远都是最新的,也是最干净的,这样才可以持续的开发自己的项目.本篇讲解 ...
- CF 3000+
CF1981F / *3000 首先有朴素的 dp:\(f_{u, i}\) 表示以 \(u\) 为根的子树已经 finish 了,经过 \(u\) 往上走的路径 MEX 为 \(i\).\(i\) ...
- 《Django 5 By Example》阅读笔记:p521-p542
<Django 5 By Example>学习第 18 天,p521-p542 总结,总计 22 页. 一.技术总结 1.django-parler django-parler 用于 mo ...
- ast-hook-for-js-RE安装
# ast-hook-for-js-RE安装 1.项目地址 点我去 2.clone到本地 git clone https://github.com/CC11001100/ast-hook-for-js ...
- NATS: 自定义服务 (Service)
使用 NATS 服务框架来创建服务会变得非常简单,基于 NATS 的服务框架,NAST 的客户端库可以更简单的构建.服务发现和监控服务.服务框架自动将所有的订阅归类到一个队列组中,提供构建基于层次化的 ...