2 timeit模块,python中数据结构
1、timeit模块:代码事件测量模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment);
setup参数是运行代码时需要的设置;
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000)
Timer类中测试语句执行速度的对象方法。
number参数是测试代码时的测试次数,默认为1000000次。
方法返回执行代码的平均耗时,一个float类型的秒数。
2、python列表操作的事件效率
(1)list生成方式比较

def t1():
li = []
for i in range(10000):
li.append(i) def t2():
li = []
for i in range(10000):
li = li + [i]
# li += [i] def t3():
li = [i for i in range(10000)] def t4():
li = list(range(10000)) def t5():
li = []
for i in range(10000):
li.extend([i]) from timeit import Timer timer1 = Timer("t1()", "from __main__ import t1")
# "t1()" 要检测的函数(str),
# "from __main__ import t1" 从哪个文件导入 print("append-->", timer1.timeit(1000))
# number参数是测试代码时的测试次数 timer2 = Timer("t2()", "from __main__ import t2")
print("+ -->", timer1.timeit(1000)) timer3 = Timer("t3()", "from __main__ import t3")
print("[i for i in range(10000)]-->", timer1.timeit(1000)) timer4 = Timer("t4()", "from __main__ import t4")
print("list(range(10000))-->", timer1.timeit(1000)) timer5 = Timer("t5()", "from __main__ import t5")
print("list(extend(10000))-->", timer1.timeit(1000))



(2)pop操作测试
x = range(2000000)
pop_zero = Timer("x.pop(0)","from __main__ import x")
print("pop_zero ",pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()","from __main__ import x")
print("pop_end ",pop_end.timeit(number=1000), "seconds") # ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')
测试pop操作:从结果可以看出,pop最后一个元素的效率远远高于pop第一个元素
可以自行尝试下list的append(value)和insert(0,value),即一个后面插入和一个前面插入???
3、list与dict的时间复杂度

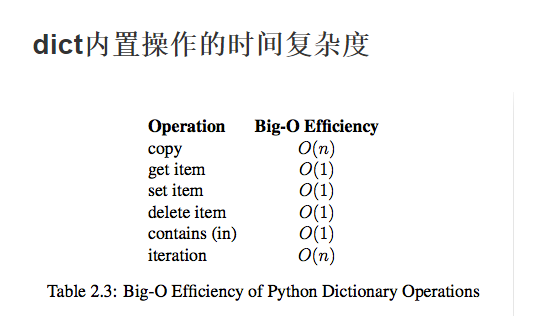




4、引入数据结构
我们如何用Python中的类型来保存一个班的学生信息? 如果想要快速的通过学生姓名获取其信息呢?



列表和字典都可以存储一个班的学生信息,但是想要在列表中获取一名同学的信息时,就要遍历这个列表,其时间复杂度为O(n),
而使用字典存储时,可将学生姓名作为字典的键,学生信息作为值,进而查询时不需要遍历便可快速获取到学生信息,其时间复杂度为O(1)。

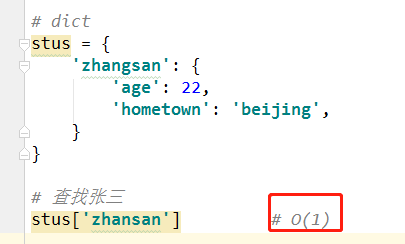
这样的数据组织方式,我们就把他叫做数据结构 组织方式不同,数据结构不同 数据结构解决的一组数据如何保存,它的保存形式是什么样式

在上面的问题中我们可以选择Python中的列表或字典来存储学生信息。列表和字典就是Python内建帮我们封装好的两种数据结构。
5、数据结构概念
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。
数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。
而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
6、算法与数据结构的区别
数据结构只是静态的描述了数据元素之间的关系。
高效的程序需要在数据结构的基础上设计和选择算法。
程序 = 数据结构 + 算法
总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
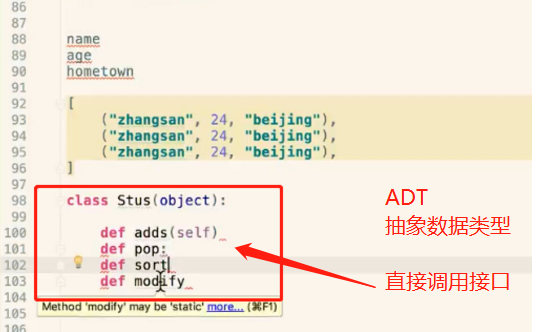
7、抽象数据类型(Abstract Data Type)
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。
引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
最常用的数据运算有五种:
- 插入
- 删除
- 修改
- 查找
- 排序
2 timeit模块,python中数据结构的更多相关文章
- re模块(Python中的正则表达式)
re模块 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎 ...
- python中数据结构
列表:数组,矩阵 元组 映射:字典 集合
- Python中好用的模块们
目录 Python中好用的模块们 datetime模块 subprocess模块 matplotlib折线图 importlib模块 Python中好用的模块们 datetime模块 相信我们都使 ...
- 转载:【学习之家】Python中__init__.py文件的作用
Python中__init__.py文件的作用详解 Python中__init__.py文件的作用详解 来源:学习之家 作者:xuexi110 人气:357 发布时间:2016-09-29 摘要:__ ...
- python中使用正则表达式处理文本(仅记录常用方法和参数)
标准库模块 python中通过re模块使用正则表达式 import re 常用方法 生成正则表达式对象 compile(pattern[,flags]) pattern:正则表达式字符串 flags: ...
- python中的计时器:timeit模块
python中的计时器:timeit模块 (1) timeit - 通常在一段程序的前后都用上time.time()然后进行相减就可以得到一段程序的运行时间,不过python提供了更强大的计时库:ti ...
- python中计时模块timeit的使用方法
timeit 模块: timeit 模块定义了接受两个参数的 Timer 类.两个参数都是字符串. 第一个参数是你要计时的语句或者函数. 传递给 Timer 的第二个参数是为第一个参数语句构建环境的导 ...
- Python中的高级数据结构详解
这篇文章主要介绍了Python中的高级数据结构详解,本文讲解了Collection.Array.Heapq.Bisect.Weakref.Copy以及Pprint这些数据结构的用法,需要的朋友可以参考 ...
- Python中的高级数据结构(转)
add by zhj: Python中的高级数据结构 数据结构 数据结构的概念很好理解,就是用来将数据组织在一起的结构.换句话说,数据结构是用来存储一系列关联数据的东西.在Python中有四种内建的数 ...
随机推荐
- swift知识点 [1]
swift知识点 [1] 循环遍历元素 三目运算符用途 Optional 与 ImplicitlyUnwrappedOptional 以及常规类型数据 is 的用法
- October 08th 2017 Week 41st Sunday
Talent wins games, but teamwork and intelligence wins championships. 才华让你赢得比赛,团队及智慧让你赢得冠军. But the m ...
- Nodejs Redis 全部操作方法
安装 npm install redis --save demo var redis = require('redis'); var client = redis.createClient('637 ...
- BZOJ1001: [BeiJing2006]狼抓兔子【最短路+对偶图】
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1001 1001: [BeiJing2006]狼抓兔子 Time Limit: 15 Se ...
- Docker镜像搭建Linux下samba共享目录
Samba 是 SMB/CIFS 网络协议的重新实现, 它作为 NFS 的补充使得在 Linux.OS/2.DOS 和 Windows 系统中进行文件共享.打印机共享更容易实现.SMB协议是客户机/服 ...
- 1798. [AHOI2009]维护序列【线段树】
Description 老师交给小可可一个维护数列的任务,现在小可可希望你来帮他完成. 有长为N的数列,不妨设为a1,a2,…,aN .有如下三种操作形式: (1)把数列中的一段数全部乘一个值; (2 ...
- Hadoop学习之路(十七)MapReduce框架Partitoner分区
Partitioner分区类的作用是什么? 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中:按照性别划分的话,需要 ...
- java读入和输出
一: 在python里直接使用input函数就可以,在java里,需要使用Scanner类,用System.in进行初始化,获取用户输入可以用nextLine获取字符串,nextInt获取整形数据. ...
- Maven/Ant的安装(Win10 x64)
一.Maven安装 1.官网下载安装包,http://maven.apache.org/download.cgi. 2.安装包解压到某一目录,然后配置maven的环境变量. PS:也可以不配置环境变量 ...
- iOS 11 使用方法替换(Method Swizzling),去掉导航栏返回按钮的文字
方法一:设置BarButtonItem的文本样式为透明颜色,代码如下: [[UIBarButtonItem appearance] setTitleTextAttributes:@{NSForegro ...