Spark RDD概念学习系列之RDD的创建(六)
RDD的创建
两种方式来创建RDD:
1)由一个已经存在的Scala集合创建
2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase、Amazon S3等。
RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。这些确定性操作称为转换,如map、filter、groupBy、join。
第1个RDD:代表了spark应用程序输入数据的来源,通过Transformation来对RDD进行各种算子的转换和实现算法。
初始RDD(或第1个RDD)创建的几个方式:(有300多种)
1、 使用程序中的集合创建RDD; 意义是:测试
2、 使用本地文件系统创建RDD; 意义是:测试大量数据的文件
3、 使用HDFS创建RDD; 意义是:生产环境里最常用
4、 基于DB创建RDD;
5、 基于NoSQL,例如HBase
6、 基于S3创建RDD;
7、 基于数据流创建RDD;
以上是典型的7种,我们这里重点讲解前3种方式。







SparkContext.scala里, SparkContext.createTaskScheduler,进入该方法



我们进一步,来学习







原来如此,所以是32。



以上是并行度,默认为1。
会利用最大,即32 = 8 X 4台worker
现在,我们来采取并行度为10,来玩玩。


问:实际上spark的并行度到底应该设置为多少呢?
答:最佳是,2-4 partitions for each CPU core。
如我们这里的CPU core是32个。每个worker给的是8个。共4台机器。
32 X 2 =64 32 X 4 = 128 即64~128之间。
说明的是,跟数据规模没关系,只跟每个task在计算partitions时的CPU使用时间和内存使用情况有关。
oom是内存溢出。


RDDBaseedOnLocalFile.scala
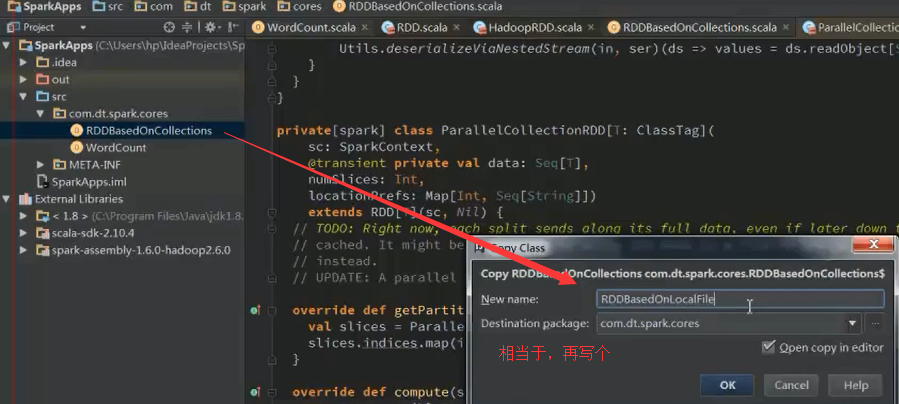

假如,计算每行的长度总和











好的,关于此处的源码解读,自行去深究。不多赘述。
以上是在local模式下,下面开始
集群模式





Spark RDD概念学习系列之RDD的创建(六)的更多相关文章
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的5大特点(五)
RDD的5大特点 1)有一个分片列表,就是能被切分,和Hadoop一样,能够切分的数据才能并行计算. 一组分片(partition),即数据集的基本组成单位,对于RDD来说,每个分片都会被一个计 ...
随机推荐
- 使用Jenkins构建持续集成环境
简介 Jenkins是一个开源的持续集成工具,提供了数百种插件供用户选择,能够完成整套持续集成环境的构建. 它具有如下的特点: 持续集成和持续发布 作为可扩展的自动服务器,Jenkins可以作为简单的 ...
- I.MX6 Linux、Jni ioctl 差异
/*********************************************************************** * I.MX6 Linux.Jni ioctl 差异 ...
- HDU 5319 Painter (模拟)
题意: 一个画家画出一张,有3种颜色的笔,R.G.B.R看成'\',B看成'/',G看成这两种的重叠(即叉形).给的是一个矩阵,矩阵中只有4种符号,除了3种颜色还有'.',代表没有涂色.问最小耗费多少 ...
- python - 简明 性能测试
简洁测试: # python -m cProfile test.py 代码注入: # -*- coding: utf-8 -*- class test(object): pass class test ...
- php flock注意事项
对于实际的运用,必须将其添加到所有使用的文件脚本中 但注意:其函数无法再NFS或其他网络文件系统中使用也无法在多线程服务器API中使用.
- js sleep效果
js sleep效果 s = setInterval(function(){ //需要执行的函数 alert("我延迟了2秒弹出"); },2000); 并不是每2秒执行一次,而是 ...
- hadoop——在命令行下编译并运行map-reduce程序 2
hadoop map-reduce程序的编译需要依赖hadoop的jar包,我尝试javac编译map-reduce时指定-classpath的包路径,但无奈hadoop的jar分布太散乱,根据自己 ...
- bootstrap-datetimepicker时间控件
欢迎各种吐槽. 本人小前端,学习过程中,某日遇到做时间控件的需求,于是无休止的召唤了度娘,发现看不太懂.算是为自己做个笔记,也便于菜鸟级别的看的懂. 首先,我们看看点击选择时间的时候的展示页面吧 年 ...
- suse linux中apache+php服务器安装
主站下载源码 tar zxvf httpd-2.2.4.tar.bz2cd httpd-2.2.4 ./configure --prefix=/usr/local/apache --sysconfdi ...
- 百度地图Api之自定义标注:(获得标注的经纬度和中心经纬度即缩放度)
百度地图Api之自定义标注:(获得标注的经纬度和中心经纬度即缩放度) <%@ Page Language="C#" AutoEventWireup="true&qu ...