淘宝召回模型MGDSPR-学习笔记
一 简介
本文是论文Embedding-based Product Retrieval in Taobao Search的学习笔记
1 整体概览
电商无处不在,从大规模语料库里面检索出兼顾相关性和用户个性化的商品至关重要。之前先在全网检索领域应用的Ebr检索技术也被应用到这个领域去解决语意Gap、个性化的问题,例如亚马逊、京东构建了基于双塔模型的Ebr检索技术。但是淘宝在自己的电商搜索里应用了Ebr检索之后,却发现相关性下降的问题;并且训练阶段和在线推理阶段模型的表现不一致。为了解决上述问题,淘宝提出了多粒度深度语义商品检索模型MGDSPR.
点评 淘宝的MGDSPR作为和倒排召回并行的一条检索通路,而Facebook在自己的Ebr检索系统里面认为这个方案是次优的,选择了基于当前老的倒排索引构建向量检索同路的方案。facebook 认为1)倒排召回、向量召回存在大量的重叠 2)双索引维护成本高 3)实验显示存在性能问题。不过淘宝和facebook的应用场景不同,一个是电商搜索一个是社交搜索,具体还是看业务场景下的表现。
2 问题发现
此前淘宝的召回模型采用的是you2be的方案, Ebr技术在电商领域兴起后,淘宝也构建了自己的Ebr检索方案,但是上线一段时间后,发现用户反馈比较多,相关性比较差。换句话说倒排技术虽然在语义理解、个性化等方面能力较弱,但是在相关性方面比较可控和稳定。例如用户搜索阿迪达斯运动鞋,在基于Ebr技术的向量空间内,它和耐克运动鞋非常相似,但是对于用户来说他很明确就是想搜阿迪达斯,返回耐克的结果是不相关的。
起初淘宝解决问题的方案是构建一个相关性控制模块,将Ebr召回的结果通过文本匹配来过滤一遍,发现30%的召回结果都被过滤了,这说明召回阶段有30%的结果不相关,造成了系统资源的浪费,因此如何提高召回阶段的相关性同时保持较好的个性化是一个需要重点解决的问题
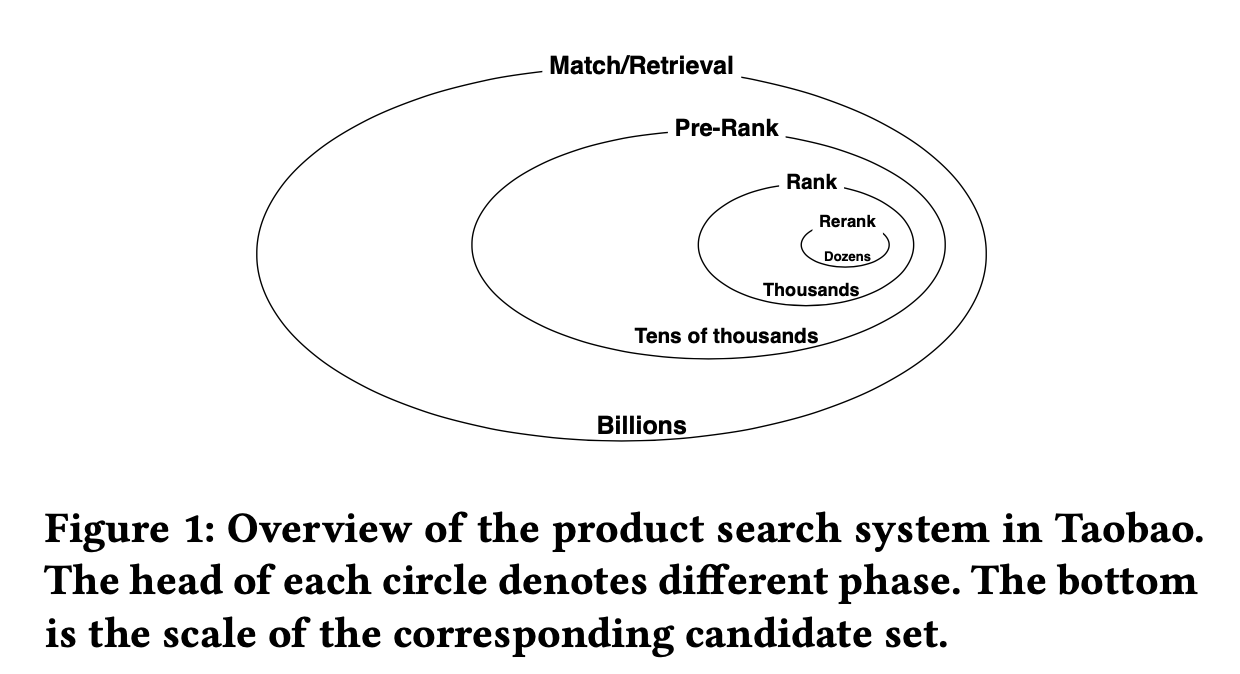
小结 淘宝发现运用Ebr技术遇到相关性下降问题、在线推理阶段的表现和模型离线训练阶段的表现不一致
3 方案概述
由前文可知提高Ebr召回的相关性、训练&推理阶段模型表现的一致性是第一个主要目标,第二个主要目标是从大规模语料库中召回文档的同时考虑用户的个性化信息也非常重要。
相关性 1) 在softmax函数里面添加温度参数来平滑训练数据的噪音。2) 使用难负样本,使得模型可以识别比较难的非常接近正样本的负样本。
模型表现一致性 使用随机负样本后模型表现的偏差依然存在。从损失函数入手 1)hinge 损失函数只能做局部比较 2)交叉熵 损失函数可以做全局比较。因此采用交叉熵损失作为训练目标
个性化 1)当今,基于推荐系统的产品如抖音、今日头条等迅速得到人们的喜爱,根本原因在于个性化,给每个人推荐他们喜欢的内容。而搜索场景如果能给出个性化的搜索结果,无疑能提高用户的满意度。2)淘宝将用户的历史行为分为实时、短期、长期行为,基于双塔模型,在query侧进行联合embedding,以期收获较好的个性化效果 3)单看query本身,淘宝进行了多粒度的编码,使用了诸如池化、attention、LSTM等模型,提高了query的表达能力
笔者注 facebook在它的论文里面给出了在线、离线2种方式挖掘难样本的方案,包括了难负样本、难正样本两个类型。而淘宝的这篇论文是通过插值计算的方式产生难负样本。fb还指出在某些场景下要控制难负样本的比例,否则模型的表现可能不如预期,原因是现实世界里大部分样本都是容易的负样本,一眼就能看出不相关那种,难的不容易识别出的负样本比例比较少。
4 论文贡献小结
构建了多粒度深度语义商品检索系统,动态捕捉用户query的含义和历史兴趣
明确了模型训练阶段、在线推理阶段表现的偏差,建议使用交叉熵损失函数
平滑用户隐式反馈的训练数据集,使用插值的方法产生难负样本
大规模线上实验数据验证了模型的表现
二 相关工作
1 检索:深度学习的2种流派
随着自然语言处理技术的发展,不同的神经网络模型涌现出来以解决传统的文本匹配不擅长的语义匹配问题,被称之为semantic gap 。解决这个问题有2个流派,一个是基于表示的学习、另一个是基于交互的学习。基于交互的学习研究query和文档之间的文本相关性模式。基于表示学习的模式,将query和文档进行向量化表示,试图挖掘这两者之间的相似度作为相关性的衡量标准,基于此发展出多种模型,双塔模型便是其中一个典型的代表。
笔者注 提到基于交互学习向量和文档之间的相关性,雅虎在ranking relevence in yahoo search中的向量传播算法与之挺像的。那篇论文里根据用户的点击构建query、文档之间的矩阵图,通过文档的向量更新query向量,反之亦然,信息在两边互相传播,最终构建出query、文档在同一个向量空间的表示。
2 双塔模型
简介
overview双塔模型包括query塔、doc塔,每一个塔用单独的模型训练出embedding向量表示,然后2者之间的点积或者consine相似度作为它们之间的相关性打分,模型的训练目标就是最大化正样本的相似度。
进阶 在每一个塔里面可以使用联合embedding的方案,将多个特征编码到一个向量表示中,例如facebook 在query塔里面嵌入了用户地理位置、社交关系等上下文信息训练出最终的query塔向量表示,以提高个性化搜索。淘宝的MGDSPR里面也采用了联合embedding的方案,将用户的实时、短期、长期行为和query在一块进行embedding编码
ANN近似最近邻
双塔模型的文档侧离线训练结束后,文档的向量表示会存到索引里面,query侧的模型用于在线推理,得出query向量,然后找出和query向量打分最高的TOP-K个文档。离线索引的规模在10亿、100亿级别,显然不可能挨个和query向量打分然后再挑选TOP-K,那样性能肯定非常差。
而ANN近邻搜索就是为了解决这个问题,它找出和query文档的近邻空间,只在这个局部空间搜索,牺牲一点精度,换来性能的提升。
淘宝的双塔模型
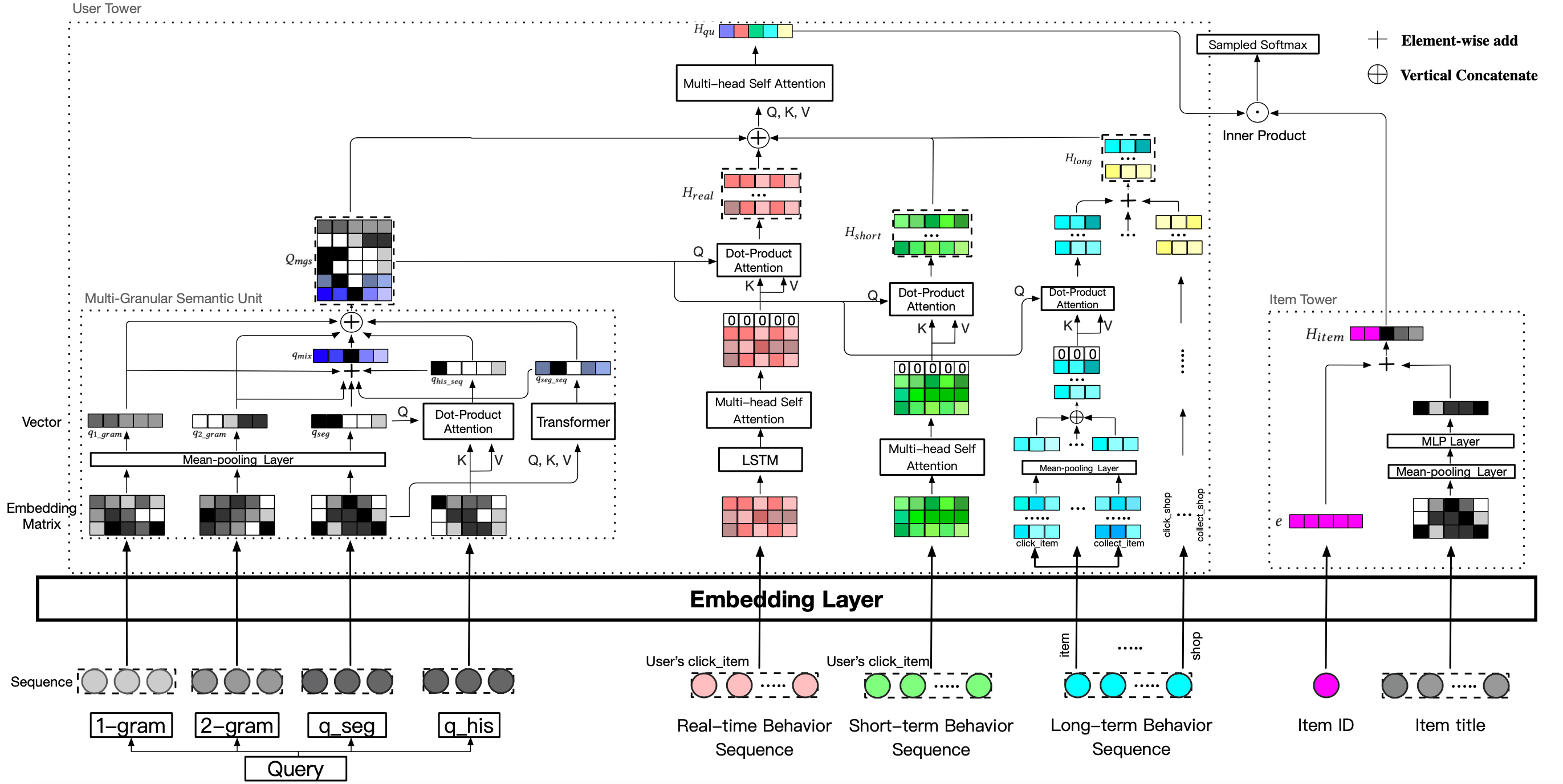
上面这个图是淘宝的双塔模型,可以看出整个模型架构非常复杂,后文会针对每一个部分进行介绍
3 业界的做法
fb的ebr也是一个双塔模型,在query侧使用了ensemble embeding :将地理位置、社交关系等信息和query进行联合embeding,以达到个性化搜索的目的。模型训练阶段使用了难样本:难正样本,难负样本,并给出了在线、离线挖掘难样本的方案,经过实验验证难样本超过一定的比例效果反而会下降。还提出了模型级连的方案。基于倒排索引实现向量检索,最终和现有的倒排索引形成混合检索。注 区别于其他公司的多路召回,fb是把向量检索融入到倒排机制中,可以在bool表达式的子项里面指定向量检索的语法。
百度
广告领域MOBIUS模型,待阅读学习
谷歌
模型离线训练需要样本,这个样本通常来源于收集到的海量的用户点击日志,样本\(<query,doc+>\) 表示用户在query下点击了对应的文档;然后存在一个冷启动问题:新进入索引的数据还没有被点击过,不存在于搜索日志中,这种冷启动问题如何解决?谷歌的方案是从推荐系统进行迁移学习,学习到的知识作为辅助task在检索模型的训练阶段使用。
亚马逊
也是双塔模型,没有考虑个性化的问题
京东
同样是双塔模型,考虑了个性化的问题,通过平均池化来聚合用户的行为,个性化比较弱
笔者注 池化是卷积神经网络的概念。对于一个\(M*N\)矩阵,有另外一个小的\(a*b\)的矩阵作为滑动窗口,在大矩阵上面滑动,窗口里面的数据元素求平均值,最后产生的所有数据形成另外一个矩阵,这种就是平均池化。当然还有其他各种诸如最大值、最小值等池化方式。池化里面还有步幅、填充的概念。
三 模型
1 问题定义
用户
\(U\) ={\(U_1\),...,\(U_u\),...,\(U_n\) } 代表\(n\)个用户
query
\(Q\) = {1,...,,..., } 代表每一个用户对应搜索的query
商品
\(I\) = {1, ..., , ..., } 代表商品的列表
行为历史
实时行为
\(R^u\) ={\(i^u_1\),...,\(i^u_t\),...,\(i^u_T\)} 代表用户的实时行为,当前行为之前的行为。
短期行为
\(S^u\) 同理代表短期行为,10天前
长期行为
\(L^u\) 同理代表长期行为,一个月之内
打分函数
\(z\) = F((\(q^u\),\(R^u\),\(S^u\),\(L^u\)),()) 其中 分别代表双塔模型用户侧、商品侧的encoder,其结果是一个向量,F是打分函数,此处是向量的内积。
2 用户塔
2.1多粒度语义单元
n-gram语法
n-gram是一种概率语言模型,它先按大小为n的照滑动窗口对文本进行分词,然后使用条件概率来预测一个序列构成一个句子的概率。例如刘德华演唱会在2-gram下将分词为<刘德,德华,华演,演唱,唱会>。然后模型根据条件概率预测在出现\(刘德\)的条件下出现\(德华\)的概率,出现\(刘德、德华\)的条件下出现\(华演\)的概率,以此类推,条件概率逐步累积,最终预测#刘德华演唱会#成为一个正常句子的概率。概率的计算依赖于事先对海量文档的统计分析。
分词、分字
以红色连衣裙为例,在论文中先分词为\(<红色、连衣裙>\) 继续分字为\(<红、色>\) \(<连、衣、裙>\)
多粒度query编码
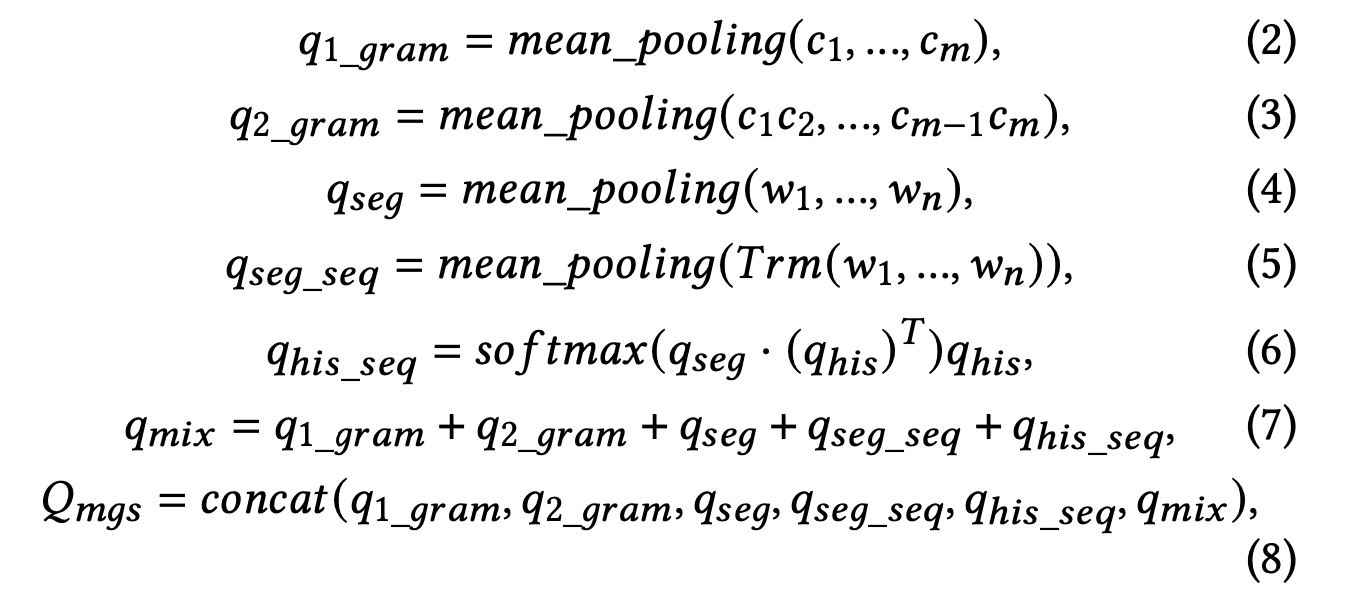
\(q1{gram}\) 使用了字级别的1-gram语言模型,每一个字是一个d维向量,所有的字对应的向量表示串联后经过平均池化操作后得到d维向量
\(q_{2gram}\) ,很显然从\(c_1c_2\),\(c_{m-1}c_{m}\) 能看出来使用了字级别的2-gram语言模型,然后平均池化后得到d维向量表示
\(q_{seq}\) 分词后平均池化
\(q_{seg}\)_\(_{seq}\) 分词后过一遍transformer模型,再做平均池化,得到d维向量表示
\(q_{his}\)_\(_{seq}\) 用户的历史搜索query和当前搜索query做softmax加权操作,最终得到d维向量
\(q_{mix}\) 上面5个做向量的加法
\(Q_{mgs}\) 将上述6个粒度的query表示串联成6*d维矩阵表示
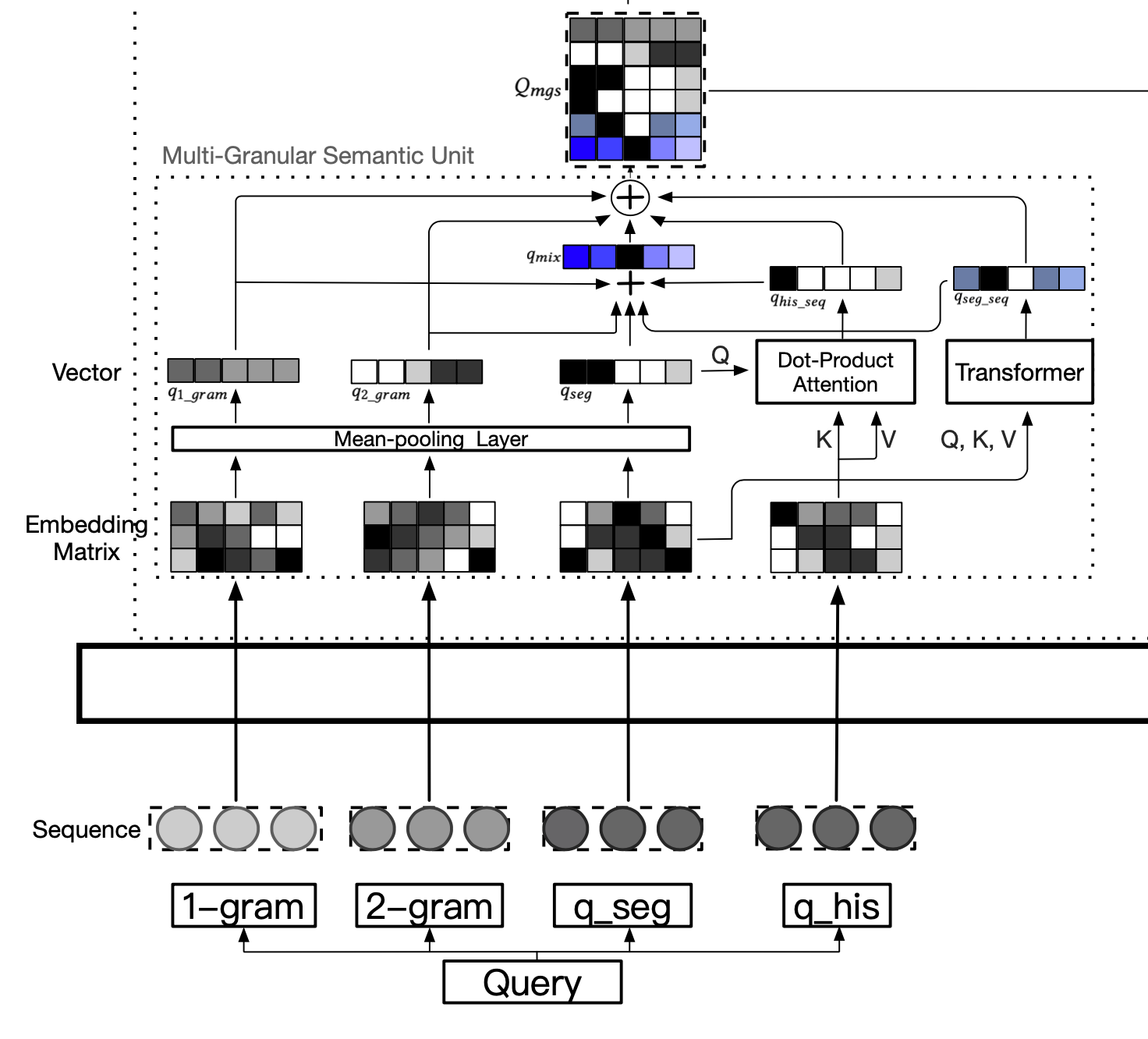
\(Q_{mgs}\) 整体生成图解
笔者注 word2vec是专门产生词向量的一个工具,那篇论文里面提到,通常情况下一个模型产生的词向量会作为另一个模型的输入这种2阶段方式来工作。论文里还提到词向量往往是模型的副产品,含义大概是:模型的训练目标是A,但是最终提取训练出来的参数作为词向量。
2.2 用户行为中的item表示
\(i^u_t\) \(\in\) \(S^u\) 定义了用户某一个短期行为,用户\(u\)在时间\(t\)点击了商品\(i\) . 商品由它的Id、品牌、商店等信息表示,定位集合\(F\).
item embedding表示
\(e_i^f\) = \(W_f\) ·\(X_i^f\) \(W_f\)是一个矩阵,可能是一个权重矩阵,\(f\)表示商品\(i\)的一个纬度,例如品牌、所属店铺等
\(i^u_t\) = concat(\(e_i^f\)|\(f\) \(\in\) \(F\) ) 将各个维度信息串联起来作为item的向量表示
上面以短期行为为例,实时、长期行为也是类似
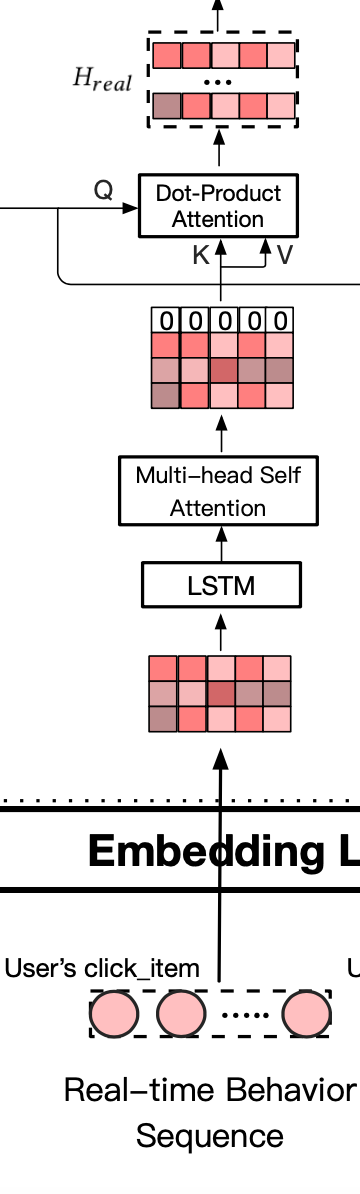
2.3 实时行为
- 使用LSTM捕捉用户历史行为的演进,并提取隐状态
\(R_{lstm}^u\) ={\(h^u_1,...,h^u_t,...,h^u_T\)}
使用多头自注意力机制从\(R^u_{lstm}\) 中捕捉多个兴趣点
\(R_{self-att}^u\) ={\(h^u_1,...,h^u_t,...,h^u_T\)}
放置全0向量:应对潜在的噪音、历史行为和当前的query不相关
\(R_{zero-att}^u\) ={\(0,h^u_1,...,h^u_t,...,h^u_T\)}
softmax操作
\(H_{real}\) = \(Sofmax(Q_{mgs}*R^T_{zero})*R^T_{zero}\)
通过softmax操作后生成6*d维矩阵
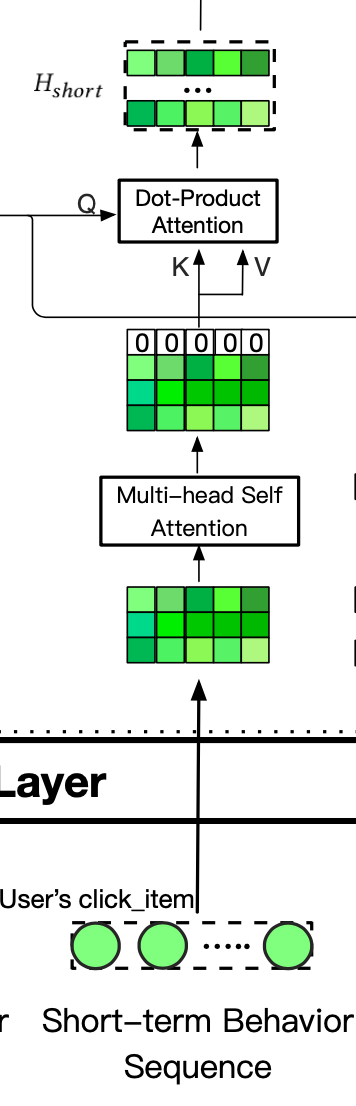
2.4 短期行为
对\(S^u\) 使用多头自注意力机制,得到隐状态\(S^_{self-attr}\) = {$h^_1 , ..., h^_t , ..., h^_T $}
放置全0向量
同\(Q_{mgs}\)做softmax操作,得到\(H_{short}\)
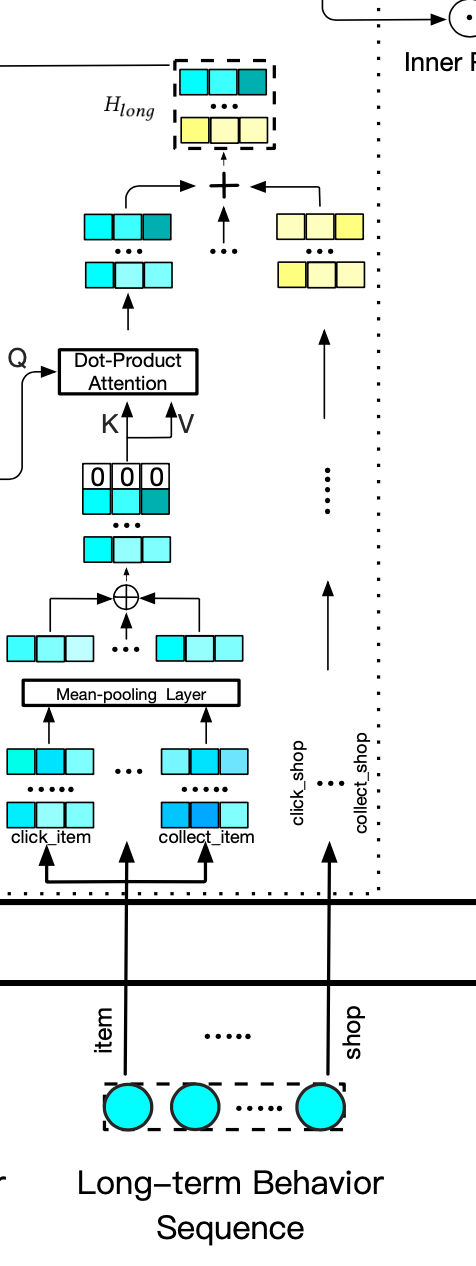
2.5 长期行为
用户的长期行为使用4个信息表示,item、shop、brand、leaf,以item为例:\(L^u_{item}\) 包含了点击、购买、收藏行为。
\(L^u_{item}\) = {\(0, H_{click},H_{buy},H_{click}\)} 其中每一个元素使用2.2中的公式计算。最终通过池化操作聚集到一个向量里,经过softmax 操作后,得到\(H_{a-item}\) 同理得到\(H_{a-shop}\) \(H_{a-brand}\) \(H_{a-leaf}\) 这四个6*d的矩阵相加最终得到用户长期行为的表示\(H_{long}\)
2.6 融合语义和个性化
所谓语义即前文提到的用户query的多粒度语义向量表示\(Q_{mgs}\) 个性化指的是用户的实时、短期、长期行为。通过自注意力机制动态捕捉它们之间的关系,将它们融合编码到一个表示中
\(H_{qu}\) = \(SelfAttr^{first}\)([[\(CLS\)], \(Q_{mgs},H_{Real},H_{Short},H_{Long}\))
3 Item塔
Item塔的结构比较简单,根据经验淘宝选择了商品id、title作为商品item的表示\(e_i\) 是商品id的d维向量表示,title经过分词得到\(T_i\) ={\(W^i_1,...W^i_N\)} 经过如下计算得到item最终的向量表示
\(H_{item}\) = \(e\) + tanh(\(W_t*\) \(\frac{\sum_{i=1}^nW_i}{N}\))
因为商品的title比较短缺乏语法结构,使用LSTM、注意力机制不如简单的池化操作
4 损失函数
4.1 损失函数的选择
为了解决模型在训练阶段、在线推理阶段不一致的问题,facebook等使用随机负样本来解决这个问题,淘宝的论文指出他们使用的pairwise损失函数,只能做局部比较,而TopK需要全局比较的能力,因此模型的不一致行为依然存在。淘宝论文里建议使用softmax交叉熵损失函数.
- facebook论文中的损失函数
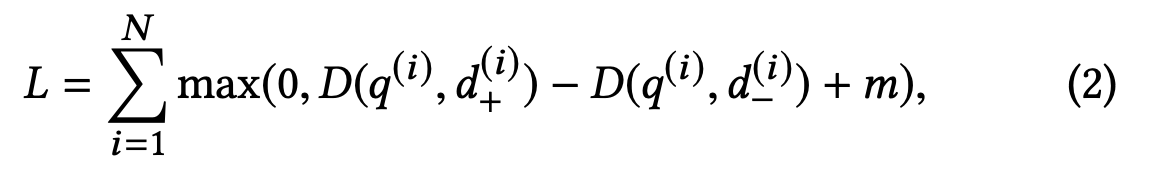
- 淘宝论文中的损失函数
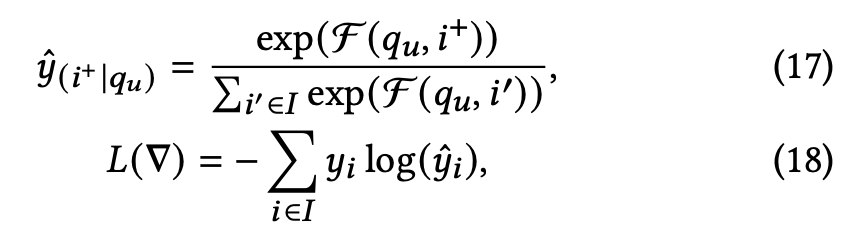
笔者注 个人理解,fb的损失函数里累加的每一项是一个打分的差值,累加项之间没有比较关系,所以具备的是局部比较能力。二淘宝使用的softmax交叉熵损失函数累加的每一项相当于一个概率,这个概率在累加项之间具有可比较性,因此谓之具备全局比较能力。
为了解决softmax引入的昂贵的partition function而导致的计算效率问题,淘宝使用量sampled softmax
4.2 平滑训练数据的噪音
除了相关性因素外,用户点击或者购买某个商品还会受到字体、颜色、价格、个人偏好等因素影响。如果模型训练阶段过度拟合了这种训练样本,那么会降低相关性。如下图所示指数部分的分母引入一个温度超参数后新的预测公式
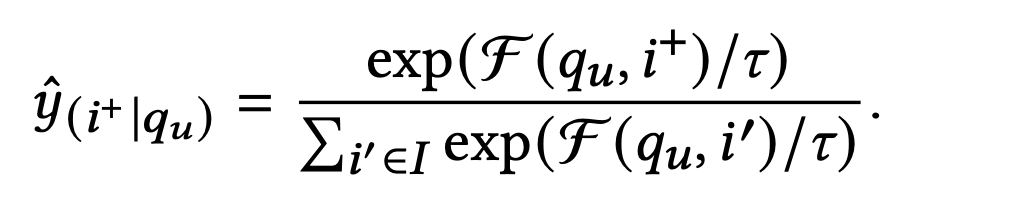
将$\tau \(从指数里面分离出来得到\)e^\tau$ 当\(\tau\) 趋近于零的时候值趋近于1,趋近于无穷大时值也趋近于无穷大。因此前者相当于正常拟合噪音数据,因为温度参数贡献的值较小;而后者温度参数贡献的值非常大,大到可以忽略打分函数的影响。
笔者注 个人理解,温度参数趋近于0,仍然贡献了接近1的值,\(exp^\digamma\) 应该是一个大于1超过一定阈值才能视温度参数对噪音数据没影响
4.3 生成难负样本
找到这样的负样本:和query打分后TopK个,与正样本做插值计算\(I_{mix}\) = \(\alpha*i^+\) +(1 - \(\alpha\))\(i_{hard}\)
四 系统架构
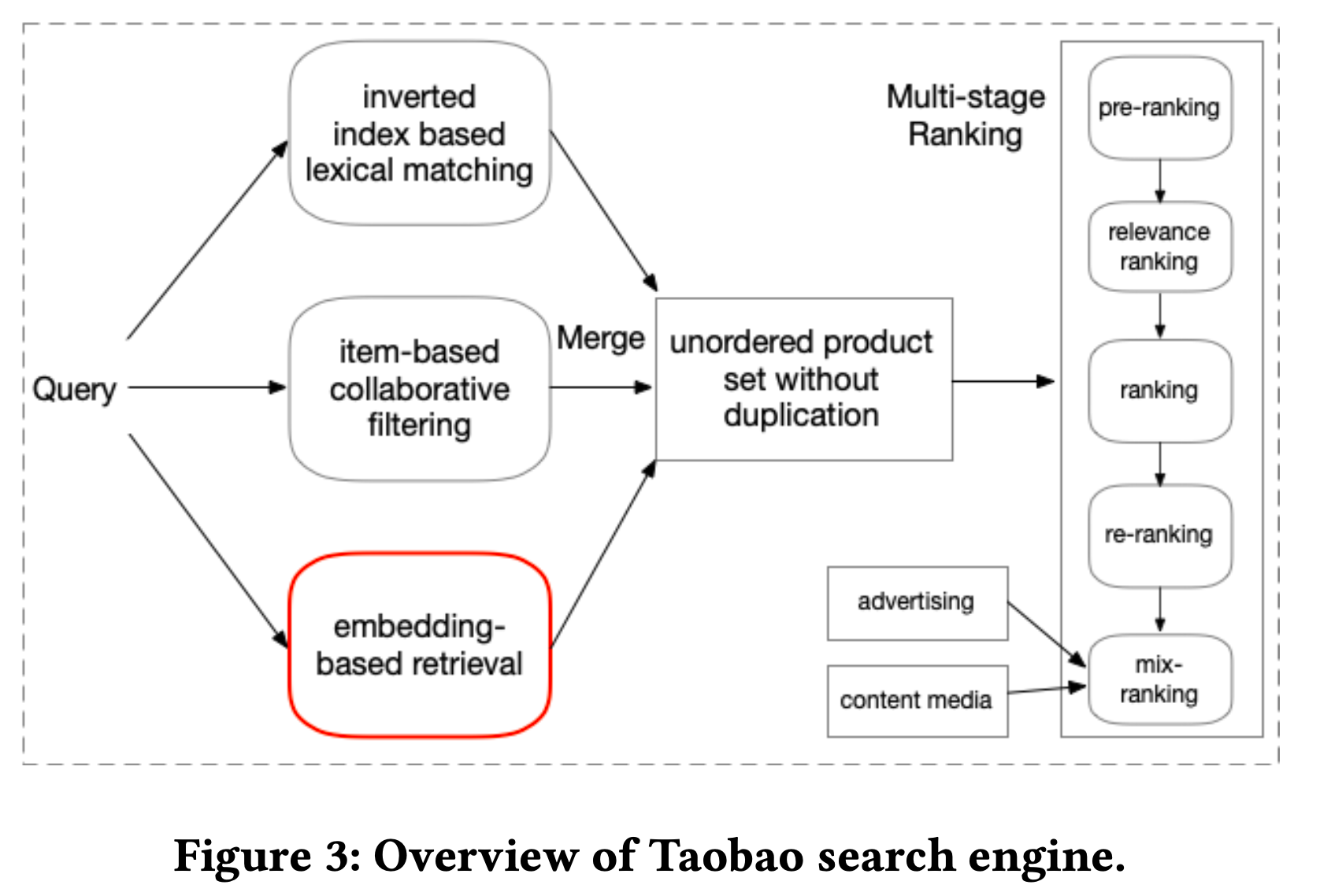
1 离线训练&索引
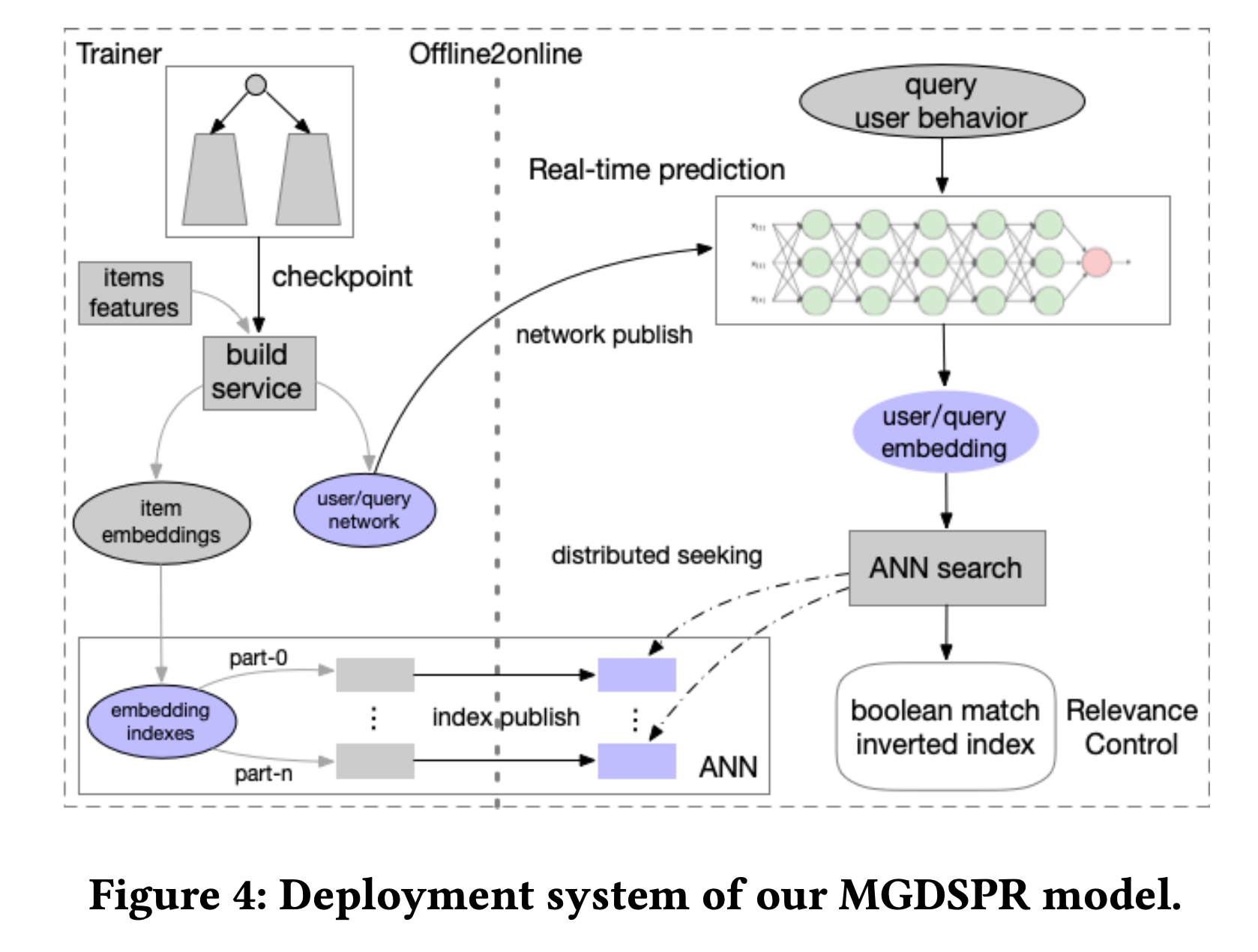
如图所示离线训练出的模型的query塔的神经网络作为在线推理使用,将用户的query转化为向量表示。Item塔产出的商品embedding向量,写入ANN索引中。一共1亿个商品,分6列存储,每一列使用K-means算法存储为层次聚类形式,其中使用了int8量化。训练阶段使用了400万个样本。
2 在线服务
离线训练结束后,用户侧神经网络和商品embeddings被发布到线上,前者作为在线实时推理平台将用户搜索大query和用户的历史行为编码为embedding向量,然后ANN检索系统从6列数据中检索出9600条结果,耗时10ms
3 相关性控制
在向量空间里阿迪达斯运动鞋 和耐克运动鞋非常相似,因此如果用户搜索了前者,后者也会出现在召回列表里,然而这并不符合用户的意图。因此淘宝的做法是在ANN结果的基础上进行bool过滤,过滤出用户比较关心的那些term,例如品牌、商品分类。当然这些term是通过query分析得出的。否则如果每一个term都去匹配过滤下,Ebr就没有存在的意义了。
(ANN results) and (Brand: Adidas) and (Category: Shoes)
五 实现细节
用户实时、短期、长期历史行为序列的长度分别是\(50,100,100\)
用户塔、商品塔、LSTM隐状态的维度是128
batch- size 256 笔者注 这个batch应该指的是模型训练中的小批量mini-batch
使用2层LSTM,丢弃率0.2 笔者注 丢弃法是模型训练过程中的一个优化手段,解决过拟合的问题
使用8-head 自注意力机制
产生的样本数684 笔者注 应该指的是生成的难负样本数
温度参数设置为2
20个参数服务,100张GPU
AdaGrad 优化 + 0.1 学习率
梯度裁剪
54小时,3500万步后模型收敛
淘宝召回模型MGDSPR-学习笔记的更多相关文章
- YY一下淘宝商品模型
淘宝的电商产品种类非常丰富,必然得力于其商品模型的高度通用性和扩展性. 下面我将亲自操作淘宝商品的发布过程,结合网上其他博客对淘宝网商品库的分析,简单谈谈我的理解. 注:下面不特殊说明,各个表除主键外 ...
- 淘宝 rem 机制入门学习
一 移动设备尺寸多种多样,带来适配难度,有时甚至无从下手.1 移动设备上的Px 像素不等于设备的物理像素.iphone 6 作为开发标准设备不等于设备的物理像素.iPhone 5 物理宽度320iPh ...
- java 深入理解jvm内存模型 jvm学习笔记
jvm内存模型 这是java堆和方法区内存模型 参考:https://www.cnblogs.com/honey01/p/9475726.html Java 中的堆也是 GC 收集垃圾的主要区域.GC ...
- [深度概念]·Attention Model(注意力模型)学习笔记
此文源自一个博客,笔者用黑体做了注释与解读,方便自己和大家深入理解Attention model,写的不对地方欢迎批评指正.. 1.Attention Model 概述 深度学习里的Attention ...
- Linux五种IO模型 ——Java学习笔记
本文摘自网络: 1.阻塞IO(blocking IO) 在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样: 图1 阻塞IO 当用户进程调用了re ...
- LDA算法 (主题模型算法) 学习笔记
转载请注明出处: http://www.cnblogs.com/gufeiyang 随着互联网的发展,文本分析越来越受到重视.由于文本格式的复杂性,人们往往很难直接利用文本进行分析.因此一些将文本数值 ...
- Caffe学习笔记4图像特征进行可视化
Caffe学习笔记4图像特征进行可视化 本文为原创作品,未经本人同意,禁止转载,禁止用于商业用途!本人对博客使用拥有最终解释权 欢迎关注我的博客:http://blog.csdn.net/hit201 ...
- JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
JUC源码学习笔记4--原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法 volatile的原理和内存屏障参考<Java并发编程的艺术> 原子类源码基于JDK8 ...
- 淘宝网触屏版 - 学习笔记(1 - 关于meta)
注:本文是学习笔记,并不是教程,所以会有很多我不理解或猜测的问题,也会有不尽详实之处,望见谅. <meta charset="utf-8"> <meta cont ...
- 淘宝网触屏版 - 学习笔记(0 - 关于dpr)
注:本文是学习笔记,并不是教程,所以会有很多我不理解或猜测的问题,也会有不尽详实之处,望见谅. 对于pc端网页设计师来说,移动端的网页制作,我之前只是简单的加了一个 <meta name=&qu ...
随机推荐
- 机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别
1.机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别 1.1 LDA算法简介和应用 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种 ...
- Unity3D中的Attribute详解(四)
本篇我们将逐一讲解Unity中经常使用的Attribute(Unity对应的文档版本为2018.1b). 首先是Serializable,SerializeField以及NonSerialized,H ...
- tkinter的标签和按钮以及输入和文本
一.标签和文本 import tkinter as tk #1.定义tk的实例对象,也就是窗口对象 window = tk.TK() #2.设置窗口大小无法缩小和放大 window.resiable( ...
- 多态、抽象、Object类
1.方法重写要求:方法名相同.参数类型相同.返回值相同或其子类返回值相同,子类修饰符要不小于父类 2.方法重载要求:方法名相同.参数类型不同.返回值没有改变.修饰符无关 3.多态的前提是继承.多态是定 ...
- LeeCode 317周赛复盘
T1: 可被3整数的偶数的平均值 思路:数组遍历 被3整数的偶数 \(\Leftrightarrow\) 被6整数的数 public int averageValue(int[] nums) { in ...
- Python常见面试题017: Python中是否可以获取类的所有实例
017. Python中是否可以获取类的所有实例 转载请注明出处,https://www.cnblogs.com/wuxianfeng023 出处 https://docs.python.org/zh ...
- php+mysql实现微信公众号回复关键词新闻列表
非常抱歉,我之前理解有误.如果您想要实现在公众号发送关键词,返回新闻列表的功能,可以按照以下步骤进行操作: 1. 创建一个数据库表,用于存储新闻的标题.链接和内容等信息.例如,可以创建一个名为news ...
- 使用Python代码远程连接服务器
目录 一.paramiko模块的介绍 二.基本使用(用户名密码登录) 三.用公钥私钥连接 一.paramiko模块的介绍 模块介绍 使用Python的第三方模块paramiko实现远程连接服务器 功能 ...
- Tmux 使用教程
本文转载自阮一峰老师的博客文章<Tmux 使用教程>,感谢阮老师! Tmux 是一个终端复用器(terminal multiplexer),非常有用,属于常用的开发工具. 本文介绍如何使用 ...
- Redis的缓存穿透+解决方案
1.缓存穿透现象介绍 缓存穿透 :缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库. 常见的解决方案有两种: 缓存空对象 优点:实现简单,维护方便 ...