语义分割评价指标(Dice coefficient, IoU)
语义分割任务常用的评价指标为Dice coefficient和IoU。Dice和IoU都是用来衡量两个集合之间相似性的度量,对于语义分割任务而言即用来评估网络预测的分割结果与人为标注结果之间的相似度。
1 混淆矩阵
混淆矩阵(confusion matrix)是一种特定的矩阵用来呈现算法性能的可视化效果,其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。下面是二分类的混淆矩阵:

预测值与真实值相同为True,反之则为False。混淆矩阵的对角线是判断正确的,期望TP和TN越大越好,FN和FP越小越好。
Accuracy(准确率)
表示预测正确的样本数量占全部样本的百分比,具体表示如下:
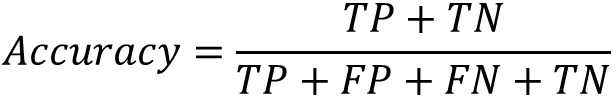
缺点:当数据类别分布不平衡时,不能评价模型的好坏。
Precision(查准率)
表示模型预测为正例的所有样本中,预测正确(真实标签为正)样本的占比:
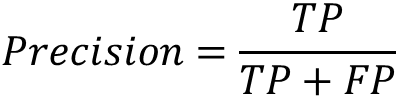
Recall (查全率)
表示所有真实标签为正的样本,有多大百分比被预测出来
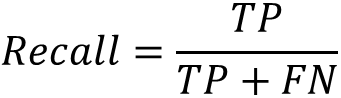
F1-score
表示precision和recall的调和平均数,具体公式如下:
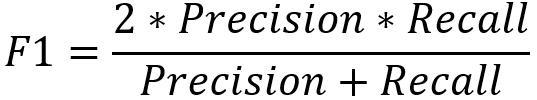
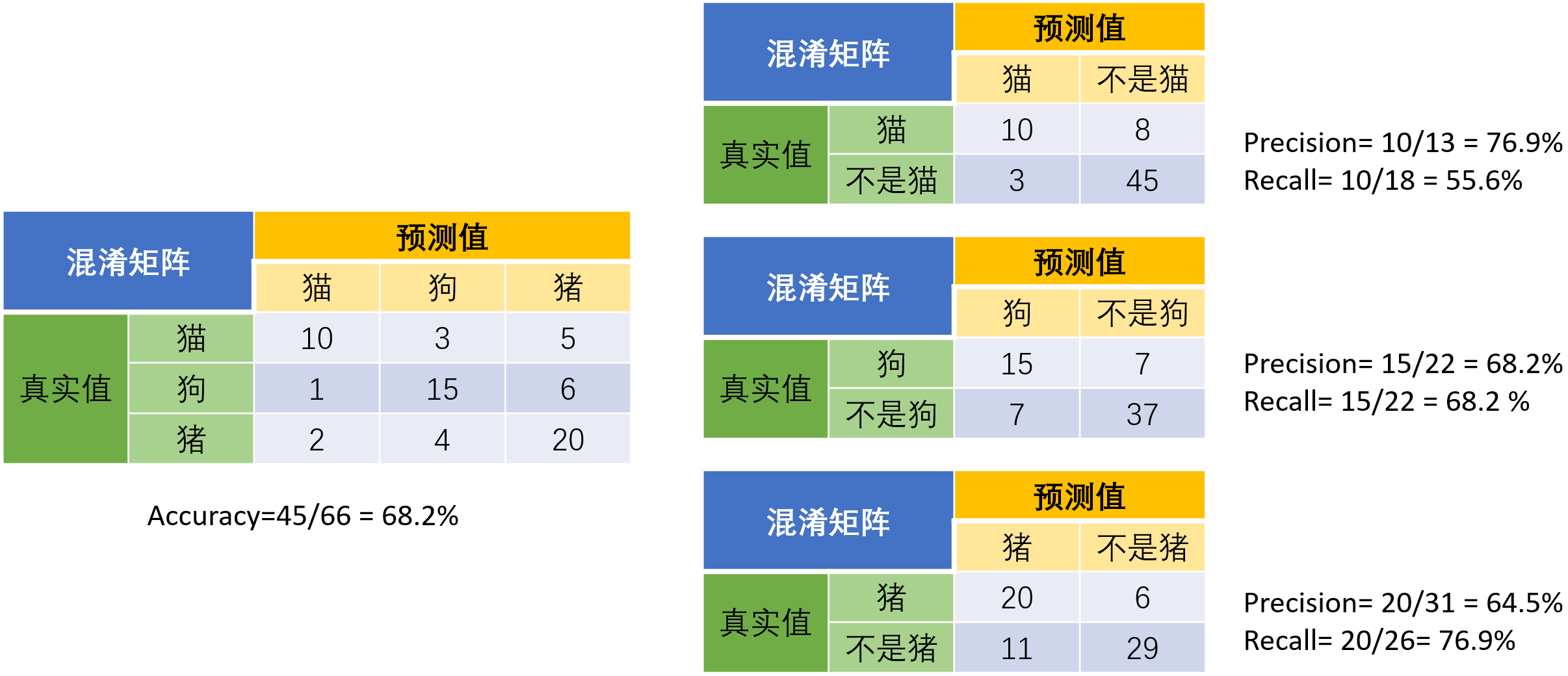
示例 猫狗猪三分类评价指标计算
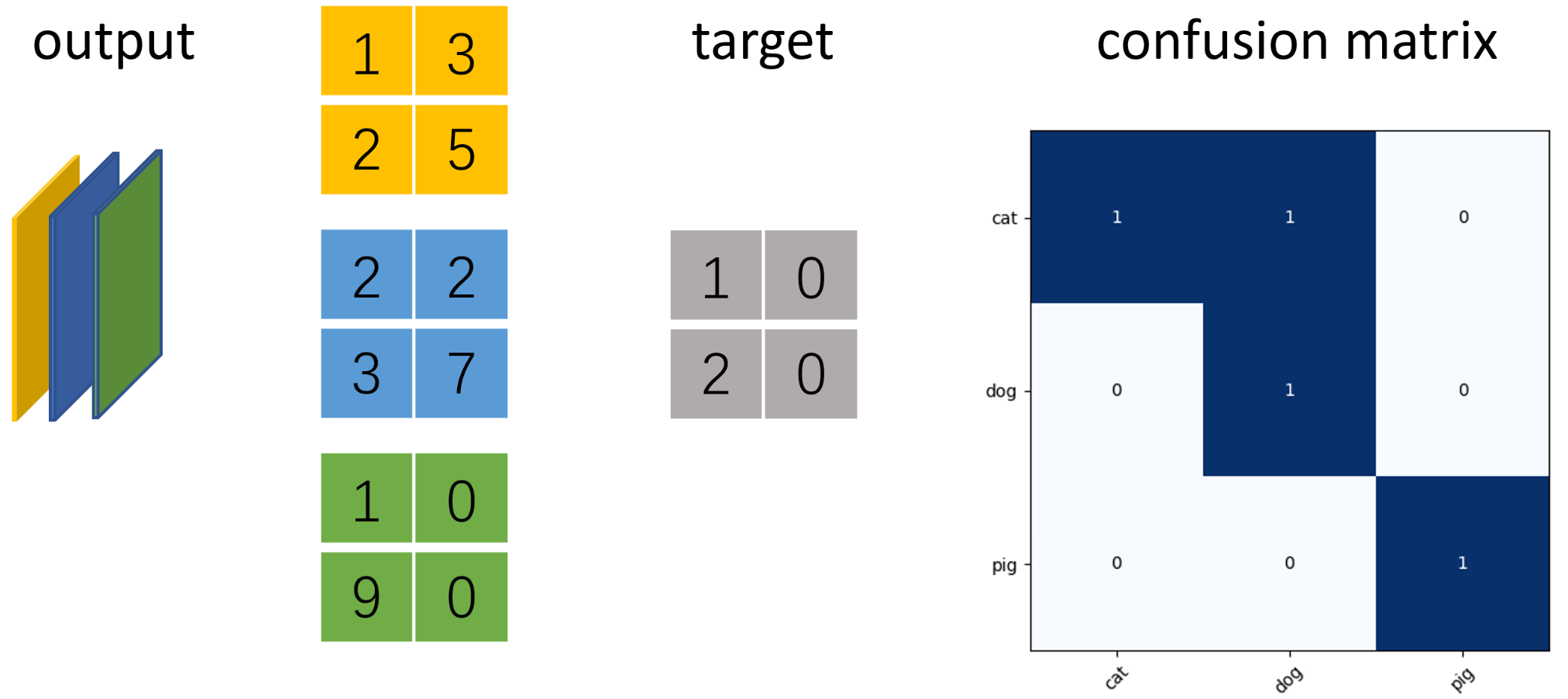
当分类问题是二分问题时,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。以下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,左边是结果。当分析每个类别时,可以将多分类问题看作是每个类别的二分问题:
2 语义分割的评价指标
语义分割的本质任务是分类任务,常规分类任务的对象是图像中的物体,而语义分割的对象是图像中像素点。
Pixel Accuracy(像素准确率)
预测正确的像素值占总像素值的百分比(对应于分类中的准确率)
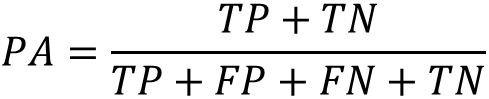
class Pixel Accuracy(类别像素准确率)
预测正确的像素值占总像素值的百分比(对应于分类中的准确率)
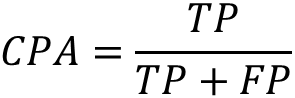
MPA(类别平均像素准确率)
所有类别像素准确率之和的平均。首先求得每个类别的像素准确率,然后对它们求和再平均。
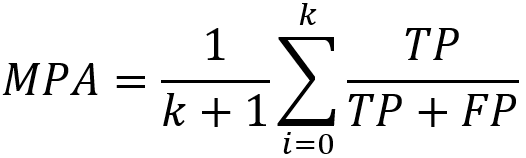
IoU(交并比)
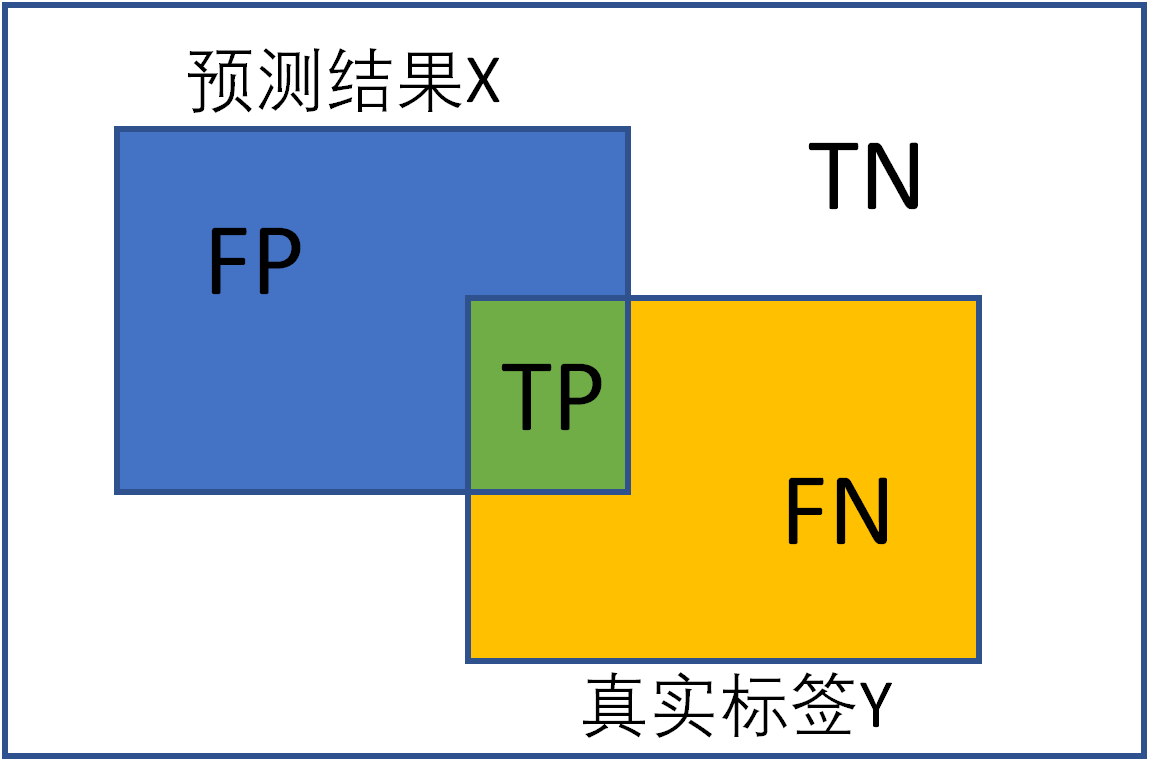
IoU(Intersection-over-Union)即是预测样本和实际样本的交并比,表达式如下:
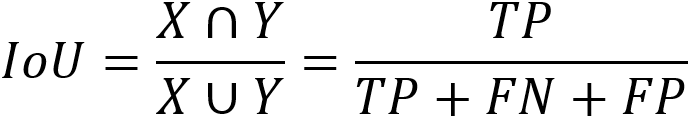
MIoU(平均交并比)
Mean IoU是在所有类别的IoU上取平均值。

示例 以三分类语义分割为例,使用ConfusionMeter计算混淆矩阵并绘制
假设图片大小为2x2像素,模型输出num_classes=3通道的矩阵,利用torchnet.meter中的ConfusionMeter计算多分类模型的混淆矩阵,acc和iu。
import numpy as np
import torch
from matplotlib import pyplot as plt
from torchnet import meter n_classes = 3 # 分类数
confusion_matrix = meter.ConfusionMeter(3)
score = torch.Tensor([[[[1, 3], [2, 5]], [[2, 2], [3, 7]], [[0, 1], [9, 0]]]]) # torch.Size([1, 3, 2, 2])
target = torch.tensor([[[1, 0], [2, 0]]]) # torch.Size([1, 2, 2]) # 注意2D时,cross_entropy的输入是(N,C,W,H), target是(N,W,H)
loss = torch.nn.functional.cross_entropy(score, target) # tensor(0.7366) # confusion_matrix要求predicted和target维度相同,且num_classes>=predicted,target>=0
predicted = score.argmax(dim=1).reshape(-1) # torch.Size([4])
target = target.reshape(-1) # torch.Size([4])
confusion_matrix.add(predicted, target)
cm_value = confusion_matrix.value()
# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
mpa = np.diag(cm_value).sum() / cm_value.sum()
# 计算每个类别的准确率
cpa = np.diag(cm_value) / cm_value.sum(1)
# 计算每个类别预测与真实目标的iou
iu = np.diag(cm_value) / (cm_value.sum(1) + cm_value.sum(0) - np.diag(cm_value)) # 绘制混淆矩阵
labels = ['cat', 'dog', 'pig'] # 每种类别的标签
# 显示数据
plt.imshow(cm_value, cmap=plt.cm.Blues)
# 在图中标注数量/概率信息
thresh = cm_value.max() / 2 # 数值颜色阈值,如果数值超过这个,就颜色加深。
for x in range(n_classes):
for y in range(n_classes):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(cm_value[y, x])
plt.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
plt.tight_layout() # 保证图不重叠
plt.yticks(range(n_classes), labels)
plt.xticks(range(n_classes), labels, rotation=45) # X轴字体倾斜45°
plt.show()
plt.close()
Dice Coefficient
Dice coefficient是医学影像分割中最常用的指标,是用于评估两个样本的相似性的度量函数,取值范围在0到1之间,取值越大表示越相似。假设ground true为X,预测结果为Y,dice coefficient定义如下:
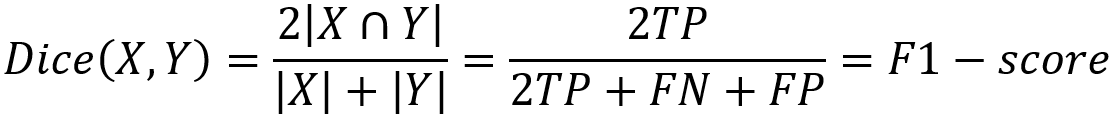
其中|x|和|y|分别表示X和Y的元素的个数,分子乘2为了保证分母重复计算后取值范围在[0,1]之间。可见dice coefficient等同于F1-score。
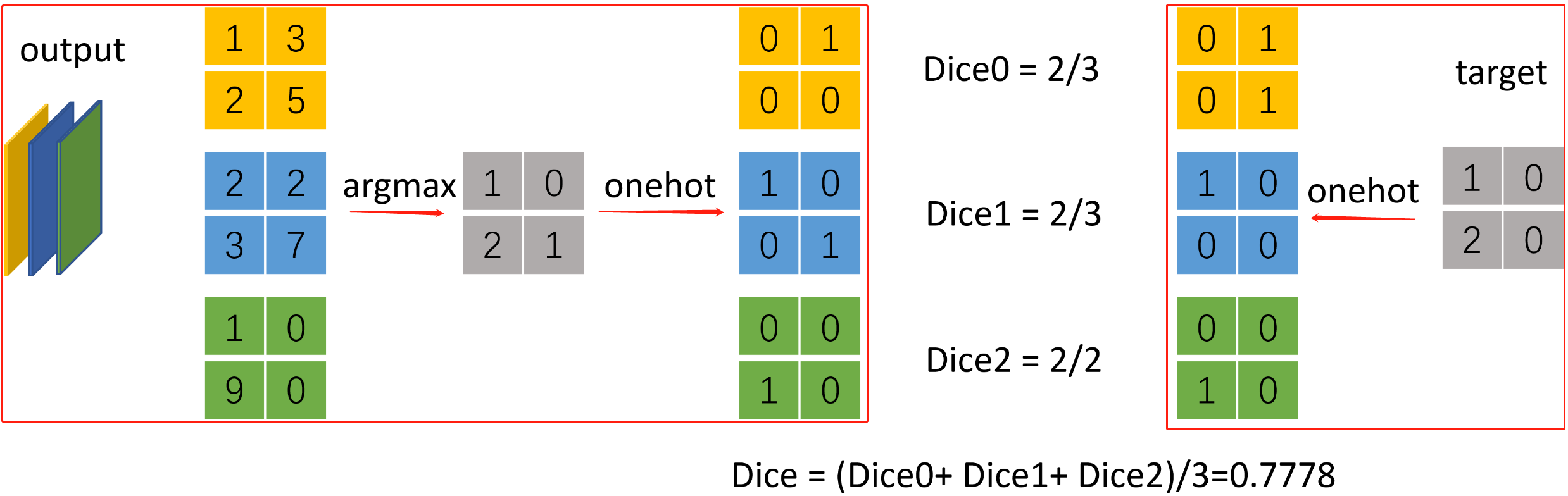
示例 三分类语义分割计算dice
import torch
from torchnet import meter def dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6):
# Average of Dice coefficient for all batches, or for a single mask
# 计算一个batch中所有图片某个类别的dice_coefficient
d = 0.
batch_size = x.shape[0]
for i in range(batch_size):
x_i = x[i].reshape(-1)
t_i = target[i].reshape(-1)
if ignore_index >= 0:
# 找出mask中不为ignore_index的区域
roi_mask = torch.ne(t_i, ignore_index)
x_i = x_i[roi_mask]
t_i = t_i[roi_mask]
inter = torch.dot(x_i, t_i)
sets_sum = torch.sum(x_i) + torch.sum(t_i)
if sets_sum == 0:
sets_sum = 2 * inter d += (2 * inter + epsilon) / (sets_sum + epsilon)
return d / batch_size def multiclass_dice_coeff(x: torch.Tensor, target: torch.Tensor, ignore_index: int = -100, epsilon=1e-6):
"""Average of Dice coefficient for all classes"""
dice = 0.
for channel in range(x.shape[1]):
dice += dice_coeff(x[:, channel, ...], target[:, channel, ...], ignore_index, epsilon) return dice / x.shape[1] if __name__ == '__main__':
n_classes = 3 # 分类数
confusion_matrix = meter.ConfusionMeter(3)
output = torch.Tensor([[[[1, 3], [2, 5]], [[2, 2], [3, 7]], [[0, 1], [9, 0]]]]) # torch.Size([1, 3, 2, 2])
target = torch.tensor([[[1, 0], [2, 0]]]) # torch.Size([1, 2, 2])
# [1, 3, 2, 2] -> [1, 2, 2] -> [1, 2, 2, 3] -> [1, 3, 2, 2]
pred = torch.nn.functional.one_hot(output.argmax(dim=1), n_classes).permute(0, 3, 1, 2).float()
# [1, 2, 2] -> [1, 2, 2, 3] -> [1, 3, 2, 2]
dice_target = torch.nn.functional.one_hot(target, n_classes).permute(0, 3, 1, 2).float()
dice = multiclass_dice_coeff(pred, dice_target)
print(dice) # tensor(0.7778)
参考
2. 语义分割的评价指标
语义分割评价指标(Dice coefficient, IoU)的更多相关文章
- 语义分割丨PSPNet源码解析「测试阶段」
引言 本文接着上一篇语义分割丨PSPNet源码解析「网络训练」,继续介绍语义分割的测试阶段. 模型训练完成后,以什么样的策略来进行测试也非常重要. 一般来说模型测试分为单尺度single scale和 ...
- 使用Keras基于RCNN类模型的卫星/遥感地图图像语义分割
遥感数据集 1. UC Merced Land-Use Data Set 图像像素大小为256*256,总包含21类场景图像,每一类有100张,共2100张. http://weegee.vision ...
- 语义分割的简单指南 A Simple Guide to Semantic Segmentation
语义分割是将标签分配给图像中的每个像素的过程.这与分类形成鲜明对比,其中单个标签被分配给整个图片.语义分段将同一类的多个对象视为单个实体.另一方面,实例分段将同一类的多个对象视为不同的单个对象(或实例 ...
- TensorFlow中的语义分割套件
TensorFlow中的语义分割套件 描述 该存储库用作语义细分套件.目标是轻松实现,训练和测试新的语义细分模型!完成以下内容: 训练和测试方式 资料扩充 几种最先进的模型.轻松随插即用 能够使用任何 ...
- PyTorch中的MIT ADE20K数据集的语义分割
PyTorch中的MIT ADE20K数据集的语义分割 代码地址:https://github.com/CSAILVision/semantic-segmentation-pytorch Semant ...
- caffe初步实践---------使用训练好的模型完成语义分割任务
caffe刚刚安装配置结束,乘热打铁! (一)环境准备 前面我有两篇文章写到caffe的搭建,第一篇cpu only ,第二篇是在服务器上搭建的,其中第二篇因为硬件环境更佳我们的步骤稍显复杂.其实,第 ...
- R-CNN论文翻译——用于精确物体定位和语义分割的丰富特征层次结构
原文地址 我对深度学习应用于物体检测的开山之作R-CNN的论文进行了主要部分的翻译工作,R-CNN通过引入CNN让物体检测的性能水平上升了一个档次,但该文的想法比较自然原始,估计作者在写作的过程中已经 ...
- 【Keras】基于SegNet和U-Net的遥感图像语义分割
上两个月参加了个比赛,做的是对遥感高清图像做语义分割,美其名曰"天空之眼".这两周数据挖掘课期末project我们组选的课题也是遥感图像的语义分割,所以刚好又把前段时间做的成果重新 ...
- 笔记︱图像语义分割(FCN、CRF、MRF)、论文延伸(Pixel Objectness、)
图像语义分割的意思就是机器自动分割并识别出图像中的内容,我的理解是抠图- 之前在Faster R-CNN中借用了RPN(region proposal network)选择候选框,但是仅仅是候选框,那 ...
- 笔记:基于DCNN的图像语义分割综述
写在前面:一篇魏云超博士的综述论文,完整题目为<基于DCNN的图像语义分割综述>,在这里选择性摘抄和理解,以加深自己印象,同时达到对近年来图像语义分割历史学习和了解的目的,博古才能通今!感 ...
随机推荐
- React的理解以及特性
一.是什么 React,用于构建用户界面的 JavaScript 库,提供了 UI 层面的解决方案 遵循组件设计模式.声明式编程范式和函数式编程概念,以使前端应用程序更高效 使用虚拟DOM来有效地操作 ...
- C++ 类方法解析:内外定义、参数、访问控制与静态方法详解
C++ 类方法 类方法,也称为成员函数,是属于类的函数.它们用于操作或查询类数据,并封装在类定义中.类方法可以分为两种类型: 类内定义方法: 直接在类定义内部声明和定义方法. 类外定义方法: 在类定义 ...
- Oracle常用的创建表语句
Oracle常用的创建表语句 Oracle常用的创建表语句 指定字段的创建 --指定字段的创建 create table table_name( test_1(字段名1) varchar2(50),( ...
- KubeVela 1.5:灵活框选 CNCF 原子能力打造独特的企业应用发布平台
简介: KubeVela 1.5 于近日正式发布.在该版本中为社区带来了更多的开箱即用的应用交付能力,包括新增系统可观测:新增 Cloud Shell 终端,将 Vela CLI 搬到了浏览器:增强的 ...
- [FAQ] dyld: Library not loaded: /usr/local/opt/icu4c/lib/libicui18n.64.dylib
通过 ls -al /usr/local/opt 可以看到 icu4c 链接的不是 libicui18n.64.dylib. 一般是 node 版本问题会出现该提示,通过观察版本大小,决定是升级还是使 ...
- GtkSharp 设置窗口背景透明
本文告诉大家如何在 GTK Sharp 里面设置窗口背景透明 在 GTK 里面设置窗口背景透明十分简单,只需使用如下代码即可 this.AppPaintable = true; var screen ...
- dotnet 6 使用 DependentHandle 关联对象生命周期
本文将告诉大家在 dotnet 6 新加入的 System.Runtime.DependentHandle 的类型的使用方法,通过 DependentHandle 可以实现将某个对象的引用生命周期和另 ...
- [python] 基于PyWaffle库绘制华夫饼图
华夫饼图Waffle chart是一种独特而直观的图表,用于表示分类数据.它采用网格状排列的等大小方格或矩形,每个方格或矩形分配不同的颜色或阴影来表示不同的类别.这种可视化方法有效地传达了每个类别在整 ...
- Spring6 当中的 Bean 循环依赖的详细处理方案+源码解析
1. Spring6 当中的 Bean 循环依赖的详细处理方案+源码解析 @ 目录 1. Spring6 当中的 Bean 循环依赖的详细处理方案+源码解析 每博一文案 1.1 Bean的循环依赖 1 ...
- 一:大数据架构回顾-Lambda架构
"我们正在从IT时代走向DT时代(数据时代).IT和DT之间,不仅仅是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让别人活得比你好&q ...