【爬虫+情感判定+Top10高频词+词云图】"乌克兰"油管热评python舆情分析
一、分析背景
乌克兰局势这两天日益紧张,任何战争到最后伤害的都是无辜平民,所以没有真正的赢家!
祈祷战争早日结束,世界和平!
油管上讨论乌克兰局势的评论声音不断,采用python的文本情感分析技术,挖掘网友舆论导向。
二、整体思路
选取5个近期”乌克兰“相关视频,分析每个视频下的Top300热评:

- 爬虫采集评论(requests)
- 情感分类打分、打标判定结果(积极/中性/消极)(中文用SnowNLP,英文用TextBlob)
- 统计出Top10高频词(jieba.analyse)
- 绘制词云图(wordcloud)
三、代码讲解
3.1 爬虫采集
爬虫程序依然采用上次爬取李子柒油管评论的程序,在此不再赘述。
封装下爬虫程序,达到采集多个视频评论的目的:
video_id_list = ['pYLjb7xIbOk', 'HnFnyNEuCUk', 'F0lYqJmGf-M', 't51ebUWe0Ag', '0RiEMEpKqic']
def download_comments(video_id_list):
"""
下载视频评论
:param video_id_list: 视频id列表
:return: None
"""
cnt = 1
for id in video_id_list:
print('正在爬取第{}个视频的评论'.format(cnt))
cmd = r"python downloader.py -y={} -o={}.json -s 0 -l 300".format(id, id) # 按热门排序,爬取前300条评论
print('开始爬取:{}'.format(id))
a = os.system(cmd) # 执行爬取评论命令
print('结束爬取:{}'.format(id))
cnt += 1
print('爬取完成:{}'.format(id))
这样,就把5个代表性视频的前300条热门评论爬取到了,爬取下来是json文件,转换为excel文件:
# 把json批量转换为excel
for file in os.listdir('./'):
if file.endswith('json'):
print(file)
f_head, f_tail = file.split(".")
print(f_head, " || ", f_tail)
try:
df = pd.read_json(file, lines=True)
df.to_excel('{}.xlsx'.format(f_head), index=False, engine='xlsxwriter', encoding='UTF-8')
except Exception as e:
print('Excepted-》{}: {}'.format(file, str(e)))
查看下评论数据的excel文件: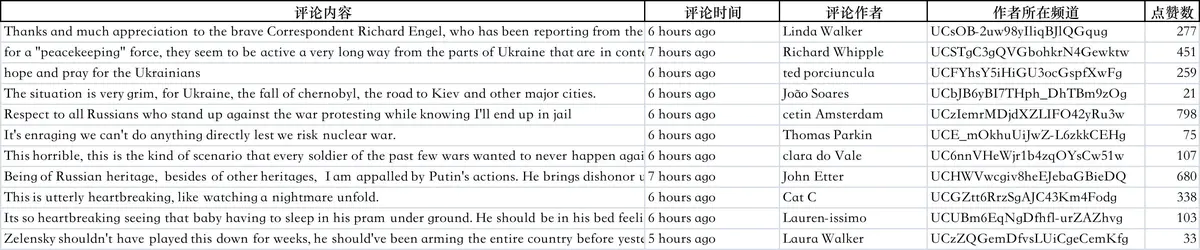
3.2 情感判定
针对每条评论数据,打情感分,判定情感结果,核心逻辑代码:
if not is_chinese(comment): # 不是中文,是英文评论
judge = TextBlob(comment)
sentiments_score = judge.sentiment.polarity
if sentiments_score < 0:
tag = '消极'
elif sentiments_score == 0:
tag = '中性'
else:
tag = '积极'
else: # 是中文评论
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.5:
tag = '消极'
else:
tag = '积极'
情感得分、判定结果: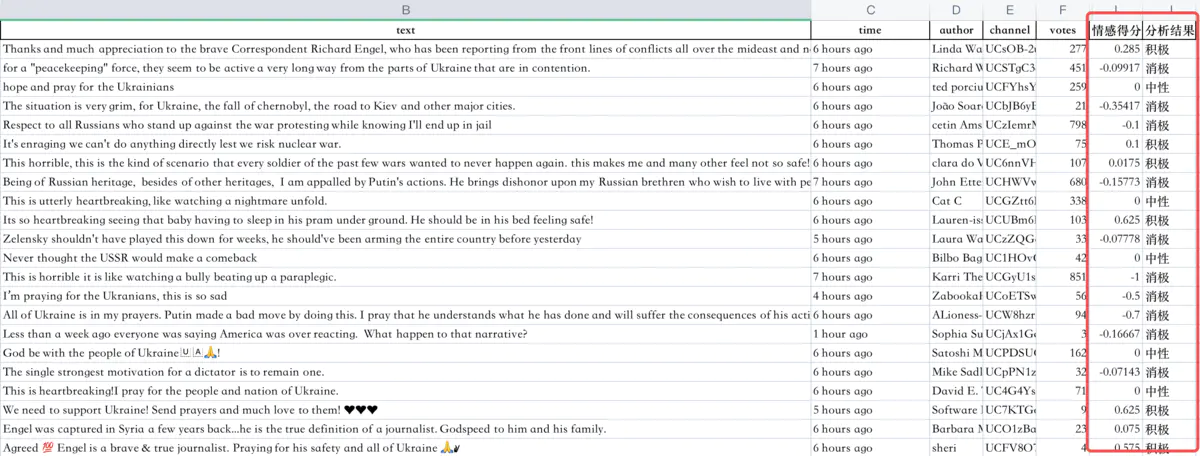
当然,还可以统计出积极、中性、消极各占多少百分比,画出饼图,对分析结果更具有说服力。
3.3 Top10高频词
用jieba自带的统计功能,直接获取到高频词和权重,就不要自己造轮子了!
# 用jieba分词统计评论内容的前10关键词
keywords_top10 = jieba.analyse.extract_tags(v_cmt_str, withWeight=True, topK=10)
topK参数传入几,就是统计前几名。
以topK=10为例,统计结果: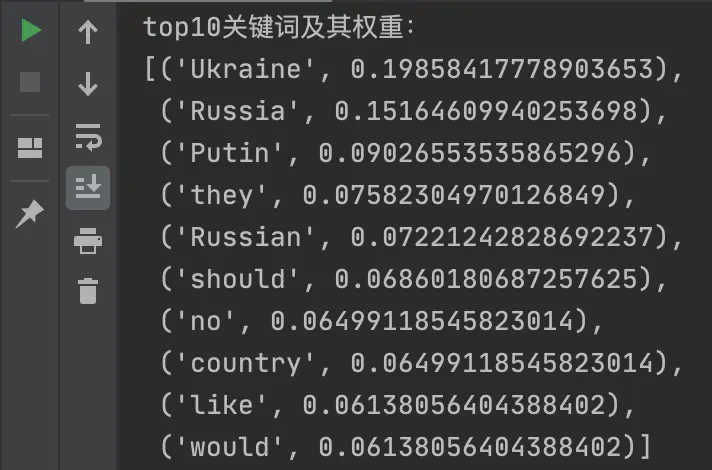
3.4 词云图
采用wordcloud库绘制词云图,词云图也是一种体现高频词的统计方式。
def make_wordcloud(v_str, v_stopwords, v_outfile):
"""
绘制词云图
:param v_str: 输入字符串
:param v_stopwords: 停用词
:param v_outfile: 输出文件
:return: None
"""
print('开始生成词云图:{}'.format(v_outfile))
try:
stopwords = v_stopwords # 停用词
backgroud_Image = plt.imread('乌克兰地图.jpg') # 读取背景图片
wc = WordCloud(
scale=4, # 清晰度
background_color="white", # 背景颜色
max_words=1500, # 最大词数
width=1500, # 图宽
height=1200, # 图高
font_path='/System/Library/Fonts/SimHei.ttf', # 字体文件路径,根据实际情况(Mac)替换
# font_path="C:\Windows\Fonts\simhei.ttf", # 字体文件路径,根据实际情况(Windows)替换
stopwords=stopwords, # 停用词
mask=backgroud_Image, # 背景图片
)
wc.generate(v_str) # 生成词云图
wc.to_file(v_outfile) # 保存图片文件
print('词云文件保存成功:{}'.format(v_outfile))
except Exception as e:
print('make_wordcloud except: {}'.format(str(e)))
wordcloud的核心参数说明,我已经加到注释上了↑,请查阅。
采用乌克兰地图作为背景图,最终效果如下:(左:背景图,右:词云图)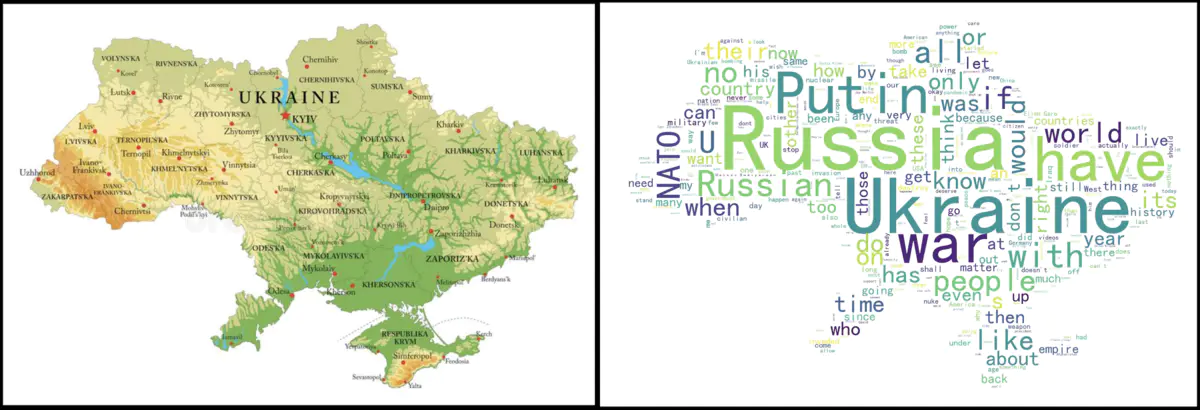
四、得出结论
从情感判定、高频词统计还有词云图体现,网友对此次事件消极和中性的情绪占据了一大部分。
而且仔细查看积极面的评论里,很多评论都是为乌克兰等人民祈福保佑的内容,所以也不是针对战争的积极评价。
所以,整体而言,是负面评价较多。
五、同步视频演示
代码演示:https://www.bilibili.com/video/BV1TU4y1f7fK
六、附完整源码
附完整源码:公众号"老男孩的平凡之路"后台回复"乌克兰"即可获取。
更多源码案例 -> 马哥python说
【爬虫+情感判定+Top10高频词+词云图】"乌克兰"油管热评python舆情分析的更多相关文章
- 【爬虫+情感判定+Top10高频词+词云图】“谷爱凌”热门弹幕python舆情分析
一.背景介绍 最近几天,谷爱凌在冬奥会赛场上夺得一枚宝贵的金牌,为中国队贡献了自己的荣誉! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众网友弹幕的舆论导向,下面 ...
- 【爬虫+情感判定+Top10高频词+词云图】“刘畊宏“热门弹幕python舆情分析
一.背景介绍 最近一段时间,刘畊宏真是火出了天际,引起一股全民健身的热潮,毕竟锻炼身体,是个好事! 针对此热门事件,我用Python的爬虫和情感分析技术,针对小破站的弹幕数据,分析了众多网友弹幕的舆论 ...
- 【爬虫+情感判定+Top10高频词+词云图】"王心凌"热门弹幕python舆情分析
目录 一.背景介绍 二.代码讲解-爬虫部分 2.1 分析弹幕接口 2.2 讲解爬虫代码 三.代码讲解-情感分析部分 3.1 整体思路 3.2 情感分析打标 3.3 统计top10高频词 3.4 绘制词 ...
- python爬虫之採集——360联想词W2版本号
http://blog.csdn.net/recsysml/article/details/30541197,我的这个博文介绍了对应的简单的方法做一个联想词的爬虫,并且还承诺了下面优化: 下一版本号的 ...
- 【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论
目录 一.背景介绍 二.爬虫代码 2.1 展示爬取结果 2.2 爬虫代码讲解 三.可视化代码 3.1 读取数据 3.2 数据清洗 3.3 可视化 3.3.1 IP属地分析-柱形图 3.3.2 评论时间 ...
- 特朗普退出《巴黎协定》:python词云图舆情分析
1 前言 2017年6月1日,美国特朗普总统正式宣布美国退出<巴黎协定>.宣布退出<巴黎协定>后,特朗普似乎成了“全球公敌”. 特斯拉总裁马斯克宣布退出总统顾问团队 迪士尼董事 ...
- python利用爬虫获取百度翻译,爱词霸翻译结果,制作翻译小工具
先看效果展示(仅作学习使用,非商业) 效果图是采用的 爱词霸 翻译,百度翻译 也实现了,只不过被注释了. 学计算机很多时候碰到生词,每次打开手机/浏览器翻译总觉得很麻烦,就想着自己写一个软件,自己去实 ...
- python爬虫实践--求职Top10城市
前言 从智联招聘爬取相关信息后,我们关心的是如何对内容进行分析,获取用用的信息.本次以上篇文章“5分钟掌握智联招聘网站爬取并保存到MongoDB数据库”中爬取的数据为基础,分析关键词为“python” ...
- 纯前端实现词云展示+附微博热搜词云Demo代码
前言 最近工作中做了几个数据可视化大屏项目,其中也有用到了词云展示,以前做词云都是用python库来生成图片显示的,这次用了纯前端的实现(Ctrl+V真好用),同时顺手做个微博热搜的词云然后记录一下~ ...
- Python爬虫——Python 岗位分析报告
前两篇我们分别爬取了糗事百科和妹子图网站,学习了 Requests, Beautiful Soup 的基本使用.不过前两篇都是从静态 HTML 页面中来筛选出我们需要的信息.这一篇我们来学习下如何来获 ...
随机推荐
- GID:旷视提出全方位的检测模型知识蒸馏 | CVPR 2021
论文提出的GID框架能够自动选择可辨别目标用于知识蒸馏,而且综合了feature-based.relation-based和response-based知识,全方位蒸馏,适用于不同的检测框架中.从实验 ...
- Chrome浏览器使用小技巧
前言 Notes made by IT-Pupil-Poo-Poo-Cai(IT小学生蔡坨坨). The notes are for reference only. Personal blog:www ...
- ABC327 A-F
vp on 2023.11.12 A: 使用 string 的 find,find 在找不到时会返回string::npos. B.C:略. D 发现原题相当于二分图判定. E 线性DP. F 原题相 ...
- 我们正在被 DDoS 攻击,但是我们啥也不干,随便攻击...
最近,一场激烈的攻防大战在网络世界悄然上演. 主角不是什么国家安全局或者黑客组织,而是一家名不见经传的创业公司--TablePlus. DDoS 攻击者们摩拳擦掌,跃跃欲试.他们从四面八方蜂拥而至,誓 ...
- 测试开发之系统篇-安装KVM虚拟机
虚拟机(Virtual Machine)和容器(Container)是两种流行的虚拟化技术. 虚拟机模拟机器的硬件,包括了完整的操作系统和应用,它一旦被开启,预分配给它的资源将全部被占用.容器是运行在 ...
- #Tarjan,树的直径#CF1000E We Need More Bosses
题目 给定一个\(n\)个点\(m\)条边的无向图,找到两个点\(s,t\),使得\(s\)到\(t\)必须经过的边最多 分析 桥就是必须经过的边,考虑给无向图缩点, 按照桥建一棵树,那么就转换成了求 ...
- OpenHarmony社区运营报告(2023年5月)
本月快讯 ● 2023年6月11-13日,2023开放原子全球开源峰会即将在北京北人亦创国际会展中心盛大开幕.2023开放原子全球开源峰会上,OpenAtom OpenHarmony(以下简称&q ...
- Kafka原理剖析之「位点提交」
一.背景 Kafka的位点提交一直是Consumer端非常重要的一部分,业务上我们经常遇到的消息丢失.消息重复也与其息息相关.位点提交说简单也简单,说复杂也确实复杂,没有人能用一段简短的话将其说清楚, ...
- DOM 节点遍历:掌握遍历 XML文档结构和内容的技巧
遍历是指通过或遍历节点树 遍历节点树 通常,您想要循环一个 XML 文档,例如:当您想要提取每个元素的值时. 这被称为"遍历节点树". 下面的示例循环遍历所有 <book&g ...
- web 报表工具如何自适应
现在的报表用户已经不再将报表作为一个单纯的报表工具看待了,有时候也会当作页面工具来使用,这时为了页面显示工整美观,就需要报表能够自适应宽度.下面我们就基于润乾报表来讲一下是如何做到自适应展现报表. 产 ...