使用CNN生成图像先验,实现更广泛场景的盲图像去模糊
现有的最优方法在文本、人脸以及低光照图像上的盲图像去模糊效果并不佳,主要受限于图像先验的手工设计属性。本文研究者将图像先验表示为二值分类器,训练
CNN 来分类模糊和清晰图像。实验表明,该图像先验比目前最先进的人工设计先验更具区分性,可实现更广泛场景的盲图像去模糊。
论文:Learning a Discriminative Prior for Blind Image Deblurring(学习用于盲图像去模糊的判别先验)
我们提出了一种基于数据驱动的判别先验的盲图像去模糊方法。我们的工作是基于这样一个事实:一个好的图像先验应该有利于清晰的图像而不是模糊的图像。在本文中,我们将图像先验表示为一个二值分类器,它可以通过一个深度卷积神经网络 ( CNN ) 来实现。学习到的先验能够区分输入图像是否清晰。嵌入到最大后验 ( MAP ) 框架中之后,它有助于在各种场景 (包括自然图像、人脸图像、文本图像和低照明图像) 中进行盲去模糊。然而,由于去模糊方法涉及非线性 CNN,因此很难优化具有学习已图像先验的去模糊方法。为此,本文提出了一种基于半二次分裂法和梯度下降法的数值求解方法。此外,该模型易于推广到非均匀去模糊任务中。定性和定量的实验结果表明,与当前最优的图像去模糊算法以及特定领域的图像去模糊方法相比,该方法具备有竞争力的性能。
简介
盲图像去模糊(blind image deblurring)是图像处理和计算机视觉领域中的一个经典问题,它的目标是将模糊输入中隐藏的图像进行恢复。当模糊形状满足空间不变性的时候,模糊过程可以用以下的方式进行建模:
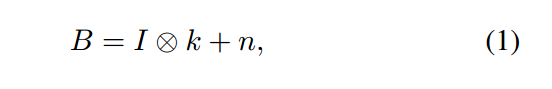
其中代表的是卷积算子,B、I、k 和 n 分别代表模糊图像、隐藏的清晰图像、模糊核以及噪声。式(1)中的问题是不适定性,因为 I 和 k 都是未知的,存在无穷多个解。为了解决这个问题,关于模糊核和图像的额外约束和先验知识都是必需的。

图 1: 一个去模糊的例子。本文提出了一个判别图像先验,它是从用于图像去模糊的深度二分类网络中学习得到的。
最近的去模糊方法的成功主要来自于有效图像先验和边缘检测策略方面的研究进展。然而,基于边缘预测的方法常常会涉及到启发式的边缘选择步骤,当边缘不可预测的时候,这种方法表现不佳。为了避免启发式的边缘选择步骤,人们提出了很多基于自然图像先验的算法,包括稀疏性归一化(normalized sparsity)[16]、L0 梯度 [38] 和暗通道先验(dark channel prior)[27]。这些算法在一般的自然图像上表现良好,但是并不适用于特殊的场景,例如文本 [26]、人脸 [25] 以及低光照图像 [11]。大多数上述的图像先验都有相似的效果,它们更加适用于清晰的图像,而不是模糊的图像,这种属性有助于基于 MAP(最大后验)的盲图像去模糊方法的成功。然而,大多数先验都是手工设计的,它们主要是基于对特定图像统计的有限观察。这些算法不能很好地泛化以处理自然环境中的多种场景。所以,开发能够使用 MAP 框架来处理不同场景的图像先验是很有意义的。
为达到这个目的,研究者将图像先验表示为能够区分清晰图像和模糊图像的二值分类器。具体来说,他们训练深度卷积神经网络来分类模糊图像 (标记为 1 ) 和清晰图像 (标记为 0 )。由于基于 MAP(最大后验)的去模糊方法通常使用 coarse-to-fine(由粗到精)策略,因此在 MAP 框架中插入具有全连接层的 CNN 无法处理不同大小的输入图像。为了解决这个问题,他们在 CNN 中采用了全局平均池化层 [ 21 ],以允许学习的分类器处理不同大小的输入。此外,为了使分类器对不同输入图像尺寸具有更强的鲁棒性,他们还采用多尺度训练策略。然后将学习到的 CNN 分类器作为 MAP(最大后验)框架中潜在图像对应的正则项。如图 1 所示,本文提出的图像先验比目前最先进的人工设计的先验 [ 27 ] 更具区分性。
然而,使用学习到的图像先验去优化这个去模糊方法是很困难的,因为这里涉及到了一个非线性 CNN。因此,本文提出了一种基于半二次方分裂法(half-quadratic splitting method)和梯度下降算法的高效数值算法。这个算法在实际使用中可以快速地收敛,并且可以应用在不同的场景中。此外,它还可以直接应用在非均匀去模糊任务中。
本文的主要贡献如下:
提出了一种高效判别图像先验,它可以通过深度卷积神经网络学习到,用于盲图像去模糊。为了保证这个先验(也就是分类器)能够处理具有不同大小的输入图像,研究者利用全局平均池化和多尺度训练策略来训练这个卷积神经网络。
将学习到的分类器作为 MAP(最大后验)框架中潜在图像对应的正则化项,并且提出了一种能够求解去模糊模型的高效优化算法。
研究者证明,与当前最佳算法相比,这个算法在广泛使用的自然图像去模糊基准测试和特定领域的去模糊任务中都具备有竞争力的性能。
研究者展示了这个方法可以直接泛化到非均匀去模糊任务中。
二分类网络
我们的目标是通过卷积神经网络来训练一个二分类器。这个网络以图像作为输入,并输出一个标量数值,这个数值代表的是输入图像是模糊图像的概率。因为我们的目标是将这个网络作为一种先验嵌入到由粗到精的 MAP(最大后验)框架中,所以这个网络应该具备处理不同大小输入图像的能力。所以,我们将分类其中常用的全连接层用全局平均池化层代替 [21]。全局平均池化层在 sigmoid 层之前将不同大小的特征图转换成一个固定的大小。此外,全局平均池化层中没有额外的参数,这样就消除了过拟合问题。图 2 展示了整个网络架构和二分类网络的细节参数。

图 2. 本文中使用的二分类网络的架构和参数,其中使用了全局平均池化层取代全连接层来应对不同大小的输入。CR 代表的是后面跟着一个 ReLU 非线性函数的卷积层,M 代表的是最大池化层,C 代表的是卷积层,G 指的是全局平均池化层,S 代表的是 Sigmoid 非线性函数。

图 4. 数据集 [15] 中的一个很具挑战性的例子。本文提出的方法以更少的边缘振荡效应和更好的视觉愉悦度恢复了模糊图像。

图 5. 在实际的模糊图像中的去模糊结果。本文的结果更加清晰,失真较少。

图 6. 文本图像上的去模糊结果。与目前最先进的去模糊算法 [26] 相比,本文的方法生成了更加尖锐的去模糊图像,其中的字符更加清晰。

图 12. 去模糊结果和中间结果。作者在图 (a)-(d) 中与目前最先进的方法 [40, 27] 比较了去模糊结果,并在 (e)-(h) 中展示了迭代中的(从左至右)中间隐藏图像。本文的判别先验恢复了用于核估计的具有更强边缘的中间结果。
使用CNN生成图像先验,实现更广泛场景的盲图像去模糊的更多相关文章
- 为什么使用CNN作为降噪先验?
图像恢复的MAP推理公式: $\hat{x}\text{}=\text{}$arg min$_{x}\frac{1}{2}||\textbf{y}\text{}-\text{}\textbf{H}x| ...
- 捕获海康威视IPCamera图像,转成OpenCV能够处理的图像(二)
海康威视IPCamera图像捕获 捕获海康威视IPCamera图像.转成OpenCV能够处理的IplImage图像(一) 捕获海康威视IPCamera图像.转成OpenCV能够处理的IplImage图 ...
- 机器学习进阶-案例实战-图像全景拼接-图像全景拼接(RANSCA) 1.sift.detectAndComputer(获得sift图像关键点) 2.cv2.findHomography(计算单应性矩阵H) 3.cv2.warpPerspective(获得单应性变化后的图像) 4.cv2.line(对关键点位置进行连线画图)
1. sift.detectAndComputer(gray, None) # 计算出图像的关键点和sift特征向量 参数说明:gray表示输入的图片 2.cv2.findHomography(kp ...
- opencv 3 core组件进阶(2 ROI区域图像叠加&图像混合;分离颜色通道、多通道图像混合;图像对比度,亮度值调整)
ROI区域图像叠加&图像混合 #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp&g ...
- arcmap坐标点生成线和面(更正版)
一:本博客的脉络 (1 )做了例如以下更正:之前在网上搜到的结果是:arcmap坐标点生成线和面 ------ 注意该功能在ArcGIS10中没有了,当时自己也没有多想就转载了,再此做一下更正或者叫做 ...
- Catlike学习笔记(1.3)-使用Unity画更复杂的3D函数图像
第三篇来了-今天去参加了 Unite 2018 Berlin,感觉就是....非常困...回来以后稍微睡了下清醒了觉得是时候认真学习下了,不过讲的很多东西都是还没有发布或者只有 Preview 的版本 ...
- JPEG图像密写研究(一) JPEG图像文件结构
[转载]转载自http://www.cnblogs.com/leaven/archive/2010/04/06/1705846.html JPEG压缩编码算法的主要计算步骤如下: (0) 8*8分块. ...
- 白盒-CNN纹理深度可视化: 使用MIT Place 场景预训练模型
MIT发文:深度视觉的量化表示................ Places2 是一个场景图像数据集,包含 1千万张 图片,400多个不同类型的场景环境,可用于以场景和环境为应用内容的视觉认知任务. ...
- OpenCV计算机视觉学习(2)——图像算术运算 & 掩膜mask操作(数值计算,图像融合,边界填充)
在OpenCV中我们经常会遇到一个名字:Mask(掩膜).很多函数都使用到它,那么这个Mask到底是什么呢,下面我们从图像基本运算开始,一步一步学习掩膜. 1,图像算术运算 图像的算术运算有很多种,比 ...
随机推荐
- Spring声明式事务配置详解
Spring支持编程式事务管理和声明式的事务管理. 编程式事务管理 将事务管理代码嵌到业务方法中来控制事务的提交和回滚 缺点:必须在每个事务操作业务逻辑中包含额外的事务管理代码 声明式事务管理 一般情 ...
- docker 下安装gitlab
1.找到docker镜像 docker search gitlab 2.下载gitlab镜像 docker pull gitlab/gitlab-ce/ 3.通常会将 GitLab 的配置 (etc ...
- 使用Python统计函数绘制复杂图形matplotlib
一.堆积图 1.堆积柱状图 如果将函数bar()中的参数bottom的取值设定为列表y.列表y1代表另一个数,函数bar(x,y1,bottom=y,color="r")就会输出堆 ...
- R语言的精度和时间效率比较(简单版)
R语言的最大数值 在R语言里面,所能计算的最大数值可以用下面的方法获得: ###R可计算最大数值 .Machine 在编程的时候注意不要超过这个数值.当然,普通情况下也不可能超过的. R语言的最大精度 ...
- yumiot的发展历程。
yumiot,大家可能没有听说过,不过作为物联网行业一颗冉冉升起的新星,大家有必要加深这一方面的了解.我先简单介绍一下这个企业.物联网,作为国家大力扶持的行业,相信大家身边也有很多这样的物联网企业.不 ...
- No space left on device Linux系统磁盘空间已满
1. 删除系统日志等 删除生成 core,mbox等文件 #find / -name core|xargs rm –rf 删除日志 2.重起机器
- 004dayPython学习输入并输出用户名和密码
在python 2.7中,捕获用户输入用raw_input 一.捕获并打印用户名和密码 要求: 输入用户名和密码都可见 # -*- coding:utf-8 -*-userName = raw_inp ...
- JS--------文件操作基本方法:上传/下载
/** * 上传文件 * @param {any} files 文件 * @param {any} data 数据 * @returns [true,文件路径] * @returns [false,异 ...
- 20175224 2018-2019-2 《Java程序设计》第七周学习总结
教材学习内容总结 第八章 常用实用类 String类 构造String对象:常量对象:String对象:引用String常量. 字符串的并置:String对象使用“+”进行并置运算,即首尾相接. 字符 ...
- python基础14_文件操作
文件操作,通常是打开,读,写,追加等.主要涉及 编码 的问题. #!/usr/bin/env python # coding:utf-8 ## open实际上是从OS请求,得到文件句柄 f = ope ...