selenium打开指定Chrome账号
selenium打开指定Chrome账号
获取User Data路径
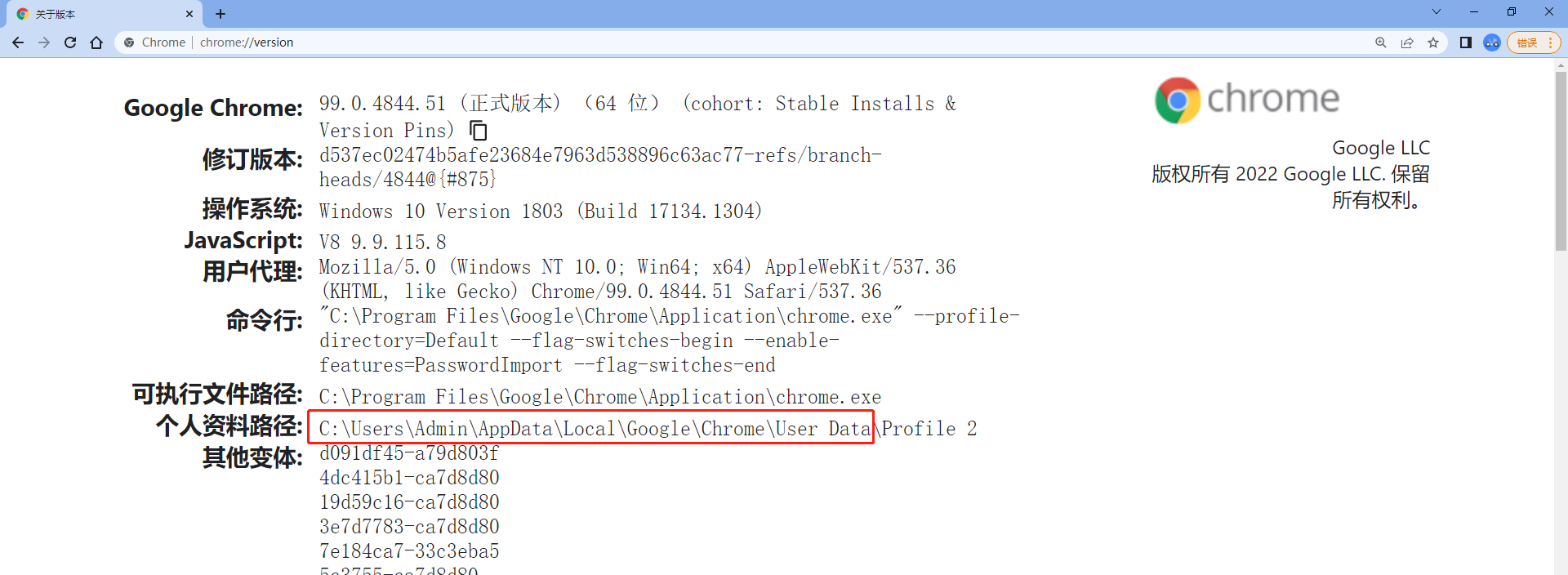
打开目标Chrome,在搜索栏输入chrome://version,找到“个人资料路径”。
这里获取到的路径为:C:\Users\Admin\AppData\Local\Google\Chrome\User Data,去掉后面的\Profile 2。
获取--profile-directory值
方法一:
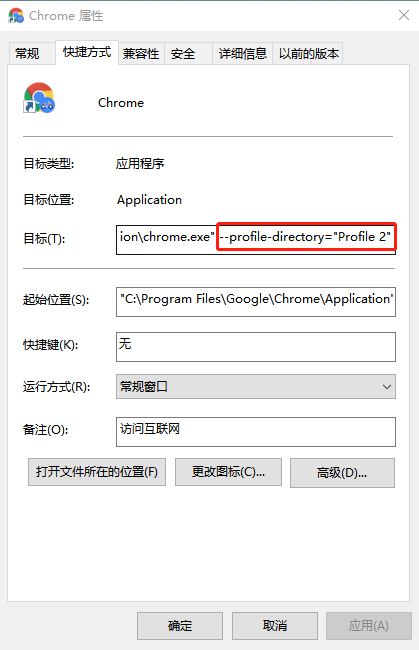
上图User Data路径末尾的“Profile 2”即为--profile-directory值。
方法二:
右键目标Chrome的桌面图标,点击属性可看到--profile-directory值为“Profile 2”。
代码演示
from time import sleep from selenium import webdriver options = webdriver.ChromeOptions()
# 步骤1获取到的User Data路径
options.add_argument(r'--user-data-dir=C:\Users\Admin\AppData\Local\Google\Chrome\User Data')
# 步骤2获取到的--profile-directory值
options.add_argument("--profile-directory=Profile 2")
driver = webdriver.Chrome(options=options) driver.get("https://www.baidu.com/")
sleep(3)
driver.quit()
注意:此时已实现打开目标Chrome,但当电脑已有打开的Chrome浏览器时,运行到第10行时会报错:user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir

解决1:在运行脚本之前关闭所有Chrome实例。即关闭所有Chrome浏览器
解决2(推荐):复制一份“Profile 2”文件夹到自己的目录,专门用于自动化。
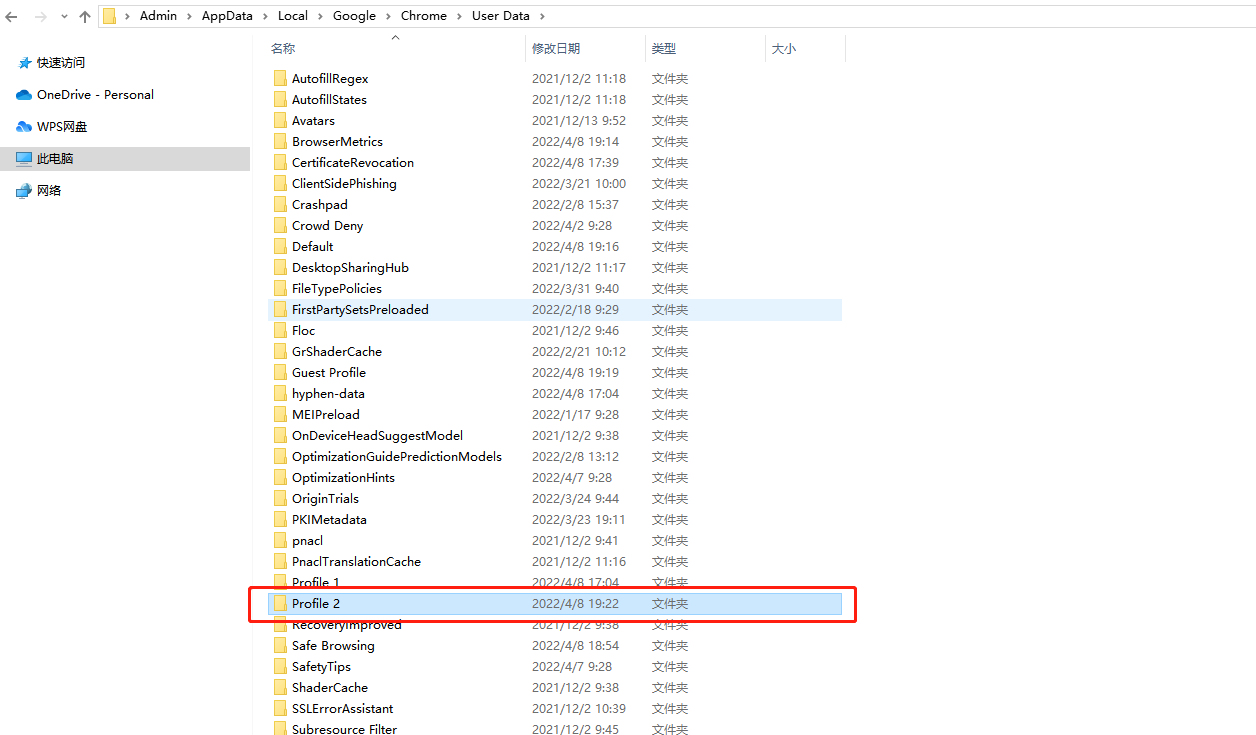
复制到自己的目录下:C:\Users\Admin\Desktop\AutoTest\ChromeData

修改代码
from time import sleep from selenium import webdriver options = webdriver.ChromeOptions()
# 修改路径为自己的目录
options.add_argument(r'--user-data-dir=C:\Users\Admin\Desktop\AutoTest\ChromeData')
options.add_argument("--profile-directory=Profile 2")
driver = webdriver.Chrome(options=options) driver.get("https://www.baidu.com/")
sleep(3)
driver.quit()
至此,解决了多开Chrome时运行脚本报错的问题~
selenium打开指定Chrome账号的更多相关文章
- Selenium及Headless Chrome抓取动态HTML页面
一般的的静态HTML页面可以使用requests等库直接抓取,但还有一部分比较复杂的动态页面,这些页面的DOM是动态生成的,有些还需要用户与其点击互动,这些页面只能使用真实的浏览器引擎动态解析,Sel ...
- python selenium 模拟登陆百度账号
代码: from selenium import webdriver url = 'https://passport.baidu.com/v2/?login' username = 'your_use ...
- Java程序打开指定地址网页
1.今天遇到了需要手动输入http地址打开指定网页的需求,试着做一个用程序打开指定网页的功能,搜了一下,还真有一个现成的例子,稍加改造,实现自己的需求: 2.代码不多,两个文件:如下: package ...
- selenium:chromedriver与chrome版本的对应关系
转自:http://blog.csdn.NET/huilan_same/article/details/51896672 再使用selenium打开chrome浏览器的时候,需要用chromedriv ...
- selenium 定制启动chrome的参数
selenium 定制启动chrome的参数 设置代理. 禁止图片加载 修改ua https://blog.csdn.net/vinson0526/article/details/51850929 1 ...
- 获取打开指定Action的所有应用包名
获取打开指定功能的所有应用:发消息,分享等等. 如打开网页,下面代码即可查看所有的浏览器 //查找所有浏览器 private void queryPackage() { PackageManager ...
- 浅入浅出EmguCv(三)EmguCv打开指定视频
打开视频的思路跟打开图片的思路是一样的,只不过视频是由一帧帧图片组成,因此,打开视频的处理程序有一个连续的获取图片并逐帧显示的处理过程.GUI同<浅入浅出EmguCv(二)EmguCv打开指定图 ...
- 浅入浅出EmguCv(二)EmguCv打开指定图片
从这篇文章开始,会介绍一些通过EmguCv实现的一些简单的功能,这个内容的更新会跟我学习OpenCv的进度有关,最近在看一本关于OpenCv的书——<学习OpenCv>,主要例子还是通过这 ...
- [转]C#中调用资源管理器(Explorer.exe)打开指定文件夹 + 并选中指定文件 + 调用(系统默认的播放类)软件(如WMP)打开(播放歌曲等)文件
原文:http://www.crifan.com/csharp_call_explorer_to_open_destinate_folder_and_select_specific_file/ C#中 ...
随机推荐
- Fiddler抓包常用功能
通过上一篇文章Fiddler移动端抓包,我们知道了Fiddler抓包原理以及怎样进行移动端抓包,接下来介绍Fiddler中常用的功能. Fiddler中常用的功能如下: 停止抓包 清空会话窗内容 过滤 ...
- 『现学现忘』Docker基础 — 27、Docker镜像的commit操作
目录 1.commit命令作用 2.commit命令说明 3.示例演示 1.commit命令作用 在运行的容器中,并在镜像的基础上做了一些修改,我们希望保存起来,封装成一个新的镜像,方便我们以后使用, ...
- Docker——基本组成
Docker架构图 客户端(client):执行命令 服务器(docker_host): 镜像(image):类似于一个模板,通过这个模板来创建容器中 容器(container):利用容器技术,独立运 ...
- 4月18日 python学习总结 异常处理、网络编程
一. 异常 1.什么是异常 异常是错误发生的信号,程序一旦出错,如果程序中还没有相应的处理机制 那么该错误就会产生一个异常抛出来,程序的运行也随之终止 2.一个异常分为三部分: 1.异常的追踪信息 2 ...
- javaweb项目对https的配置01
1.准备证书生成 a.进入到jdk下的bin目录(如果配置了Java的环境,可以直接在cmd命令窗口中直接输入如下命令) keytool -v -genkey -alias tomcat -keyal ...
- S2-045(RCE远程代码执行)
环境搭建: https://blog.csdn.net/qq_36374896/article/details/84145020 漏洞复现 进入漏洞环境 (048和045一样) cd vulhub-m ...
- [XCTF嘉年华体验赛](web)web2 assert函数
0x00 题目分析 浏览一遍页面,在about页面,获得如下信息 访问 .git/ ,页面存在. 使用githack扒下来.得到源码,进行代码审计. 分析得到: 1.flag在flag页面,要看源码才 ...
- 什么是B+树??
上一篇中,我们了解了B树,辣么..B+树又是什么呢?? 一:定义:B+树是基于B树的,是B树的变形,也是一种多路搜索树.查询性能更加出色. 1.每个父节点元素出现在子节点中,是子节点的最大或最小元素. ...
- python 基础数据类型汇总
数据类型小结(各数据类型常用操作) 一.数字/整型int int()强行转化数字 二.bool类型False&True bool()强行转化布尔类型. 0,None,及各个空的字符类型为Fal ...
- 遇到的错误之“Cannot find module 'XXX’的错误”
一.问题: 在进行webpack打包的时候,会出现Cannot find module 'XXX'的错误,找不到某个模块的错误 二.解决方法: (1)方法1: 直接进行npm install重新打包: ...