4.1:简单python爬虫
简单python爬虫
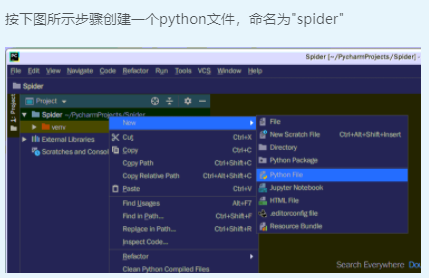
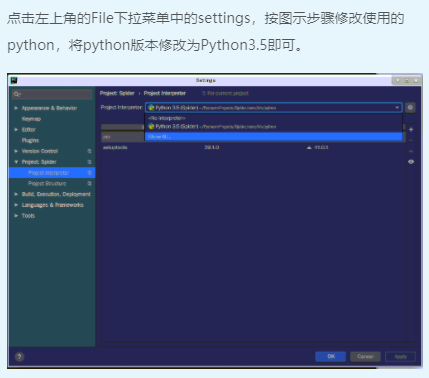
在创建的python文件中输入下列代码:
# coding:utf-8
import requests
from bs4 import BeautifulSoup def spider(url,headers):
with open('renming.txt', 'w', encoding='utf-8') as fp:
r = requests.get(url, headers=headers)
r.encoding = 'gb2312'
# test=re.findall('<li>< a href= >(.*?)</ a></li>',r.text)
# print(test)
soup = BeautifulSoup(r.text, "html.parser")
for news_list in soup.find_all(class_="list14"):
content = news_list.text.strip()
fp.write(content)
fp.close() if __name__=="__main__":
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/55.0.2883.87 Safari/537.36'} url = 'http://www.people.com.cn/'
spider(url, headers)
如果代码中存在报错,请在PyCharm最下边找到Terminal,点击Terminal后Pycharm底部控制台处会出现其自带的命令行窗口,输入下面两条命令即可解决报错:pip install requestspip install bs4解决完报错之后,在代码文件的任意处右击,点击Run,之后就会发现在代码文件目录中出现了renmin.txt,里面是爬取的人民网的数据。

4.1:简单python爬虫的更多相关文章
- 一个简单python爬虫的实现——爬取电影信息
最近在学习网络爬虫,完成了一个比较简单的python网络爬虫.首先为什么要用爬虫爬取信息呢,当然是因为要比人去收集更高效. 网络爬虫,可以理解为自动帮你在网络上收集数据的机器人. 网络爬虫简单可以大致 ...
- 简单python爬虫实例
先放上url,https://music.douban.com/chart 这是豆瓣的一个音乐排行榜,这里爬取了左边部分的歌曲排行榜部分,爬虫很简单,就用到了beautifulsoup和request ...
- 简单python爬虫编写,Python采集妹子图!
疫情期间在家闲来无事,每天打游戏荒废了一段时间.我觉得自己不能在这么颓废下去,就立马起身写了一点python代码(本人只是python新手). 很多人学习python,不知道从何学起.很多人学习pyt ...
- 简单python爬虫案例(爬取慕课网全部实战课程信息)
技术选型 下载器是Requests 解析使用的是正则表达式 效果图: 准备好各个包 # -*- coding: utf-8 -*- import requests #第三方下载器 import re ...
- Selenium + PhantomJS + python 简单实现爬虫的功能
Selenium 一.简介 selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDrive ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 一个简单的多线程Python爬虫(一)
一个简单的多线程Python爬虫 最近想要抓取拉勾网的数据,最开始是使用Scrapy的,但是遇到了下面两个问题: 前端页面是用JS模板引擎生成的 接口主要是用POST提交参数的 目前不会处理使用JS模 ...
- 纯手工打造简单分布式爬虫(Python)
前言 这次分享的文章是我<Python爬虫开发与项目实战>基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容. ...
- python爬虫——写出最简单的网页爬虫
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材.我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
随机推荐
- Django 之视图层
JsonResponse 1 json格式的数据有什么用 前后端数据交互需要使用json作为过渡,实现跨语言传输数据 2 前后端方法对应 JSON.stringify() - json.dumps( ...
- K8S Pod Pending 故障原因及解决方案
文章转载自:https://mp.weixin.qq.com/s/SBpnxLfMq4Ubsvg5WH89lA
- EFK-1:快速指南
转载自:https://mp.weixin.qq.com/s?__biz=MzUyNzk0NTI4MQ==&mid=2247483801&idx=1&sn=11fee5756c ...
- nginx进程所属用户问题讨论
结论 1,在非root账户下启动时,nignx的master和worker进程的用户都将是这个账户, 2,在root账户下启动时 nignx的master进程是用户是root,worker的用户在co ...
- 使用国内镜像源安装kubelet kubeadm kubectl
由于官网未开放同步方式, 可能会有索引gpg检查失败的情况, 这时请用 yum install -y --nogpgcheck kubelet kubeadm kubectl 安装 Debian / ...
- ubuntu开启sshd
SSH分客户端openssh-client和openssh-server 如果你只是想登陆别的机器的SSH只需要安装openssh-client(ubuntu有默认安装,如果没有则sudo apt-g ...
- a除于b
a=eval(input()) b=eval(input()) if b!=0: print("{}".format(round(a/b,2))) else: print(&quo ...
- 把train数据集生成txt(test同理)
import cv2 import numpy as np import os import sys import pickle data_dir = os.path.join("./&qu ...
- spring boot集成redis基础入门
redis 支持持久化数据,不仅支持key-value类型的数据,还拥有list,set,zset,hash等数据结构的存储. 可以进行master-slave模式的数据备份 更多redis相关文档请 ...
- Ubuntu安装错误 server64 busybox-initramfs安装失败
因为想试试在Linux系统上爆破 所以安装了一下Ubuntu.第一次安装包报了个server64 busybox-initramfs.在安装系统那边.我一直还以为是我磁盘分配错了. 后来在网上找了资料 ...