NDArray自动求导
NDArray可以很方便的求解导数,比如下面的例子:(代码主要参考自https://zh.gluon.ai/chapter_crashcourse/autograd.html)
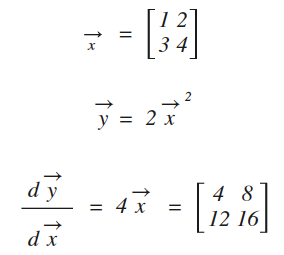
用代码实现如下:
import mxnet.ndarray as nd
import mxnet.autograd as ag
x = nd.array([[1,2],[3,4]])
print(x)
x.attach_grad() #附加导数存放的空间
with ag.record():
y = 2*x**2
y.backward() #求导
z = x.grad #将导数结果(也是一个矩阵)赋值给z
print(z) #打印结果
[[ 1. 2.]
[ 3. 4.]]
<NDArray 2x2 @cpu(0)> [[ 4. 8.]
[ 12. 16.]]
<NDArray 2x2 @cpu(0)>
对控制流求导
NDArray还能对诸如if的控制分支进行求导,比如下面这段代码:
def f(a):
if nd.sum(a).asscalar()<15: #如果矩阵a的元数和<15
b = a*2 #则所有元素*2
else:
b = a
return b
数学公式等价于:
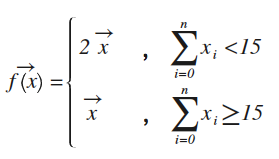
这样就转换成本文最开头示例一样,变成单一函数求导,显然导数值就是x前的常数项,验证一下:
import mxnet.ndarray as nd
import mxnet.autograd as ag def f(a):
if nd.sum(a).asscalar()<15: #如果矩阵a的元数和<15
b = a*2 #则所有元素平方
else:
b = a
return b #注:1+2+3+4<15,所以进入b=a*2的分支
x = nd.array([[1,2],[3,4]])
print("x1=")
print(x)
x.attach_grad()
with ag.record():
y = f(x)
print("y1=")
print(y)
y.backward() #dy/dx = y/x 即:2
print("x1.grad=")
print(x.grad) x = x*2
print("x2=")
print(x)
x.attach_grad()
with ag.record():
y = f(x)
print("y2=")
print(y)
y.backward()
print("x2.grad=")
print(x.grad)
x1=
[[ 1. 2.]
[ 3. 4.]]
<NDArray 2x2 @cpu(0)>
y1=
[[ 2. 4.]
[ 6. 8.]]
<NDArray 2x2 @cpu(0)>
x1.grad=
[[ 2. 2.]
[ 2. 2.]]
<NDArray 2x2 @cpu(0)>
x2=
[[ 2. 4.]
[ 6. 8.]]
<NDArray 2x2 @cpu(0)>
y2=
[[ 2. 4.]
[ 6. 8.]]
<NDArray 2x2 @cpu(0)>
x2.grad=
[[ 1. 1.]
[ 1. 1.]]
<NDArray 2x2 @cpu(0)>
头梯度
原文上讲得很含糊,其实所谓头梯度,就是一个求导结果前的乘法系数,见下面代码:
import mxnet.ndarray as nd
import mxnet.autograd as ag x = nd.array([[1,2],[3,4]])
print("x=")
print(x) x.attach_grad()
with ag.record():
y = 2*x*x head = nd.array([[10, 1.], [.1, .01]]) #所谓的"头梯度"
print("head=")
print(head)
y.backward(head_gradient) #用头梯度求导 print("x.grad=")
print(x.grad) #打印结果
x=
[[ 1. 2.]
[ 3. 4.]]
<NDArray 2x2 @cpu(0)>
head=
[[ 10. 1. ]
[ 0.1 0.01]]
<NDArray 2x2 @cpu(0)>
x.grad=
[[ 40. 8. ]
[ 1.20000005 0.16 ]]
<NDArray 2x2 @cpu(0)>
对比本文最开头的求导结果,上面的代码仅仅多了一个head矩阵,最终的结果,其实就是在常规求导结果的基础上,再乘上head矩阵(指:数乘而非叉乘)
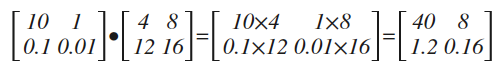
链式法则
先复习下数学
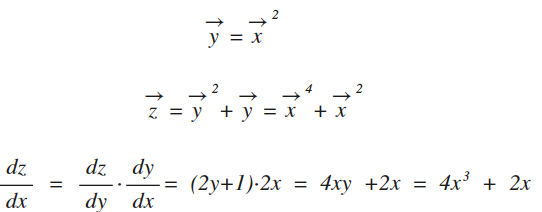
注:最后一行中所有变量x,y,z都是向量(即:矩形),为了不让公式看上去很凌乱,就统一省掉了变量上的箭头。NDArray对复合函数求导时,已经自动应用了链式法则,见下面的示例代码:
import mxnet.ndarray as nd
import mxnet.autograd as ag x = nd.array([[1,2],[3,4]])
print("x=")
print(x) x.attach_grad()
with ag.record():
y = x**2
z = y**2 + y z.backward() print("x.grad=")
print(x.grad) #打印结果 print("w=")
w = 4*x**3 + 2*x
print(w) # 验证结果
x=
[[ 1. 2.]
[ 3. 4.]]
<NDArray 2x2 @cpu(0)>
x.grad=
[[ 6. 36.]
[ 114. 264.]]
<NDArray 2x2 @cpu(0)>
w=
[[ 6. 36.]
[ 114. 264.]]
<NDArray 2x2 @cpu(0)>
NDArray自动求导的更多相关文章
- [深度学习] pytorch学习笔记(1)(数据类型、基础使用、自动求导、矩阵操作、维度变换、广播、拼接拆分、基本运算、范数、argmax、矩阵比较、where、gather)
一.Pytorch安装 安装cuda和cudnn,例如cuda10,cudnn7.5 官网下载torch:https://pytorch.org/ 选择下载相应版本的torch 和torchvisio ...
- PyTorch官方中文文档:自动求导机制
自动求导机制 本说明将概述Autograd如何工作并记录操作.了解这些并不是绝对必要的,但我们建议您熟悉它,因为它将帮助您编写更高效,更简洁的程序,并可帮助您进行调试. 从后向中排除子图 每个变量都有 ...
- 『PyTorch x TensorFlow』第六弹_从最小二乘法看自动求导
TensoFlow自动求导机制 『TensorFlow』第二弹_线性拟合&神经网络拟合_恰是故人归 下面做了三个简单尝试, 利用包含gradients.assign等tf函数直接构建图进行自动 ...
- 什么是pytorch(2Autograd:自动求导)(翻译)
Autograd: 自动求导 pyTorch里神经网络能够训练就是靠autograd包.我们来看下这个包,然后我们使用它来训练我们的第一个神经网络. autograd 包提供了对张量的所有运算自动求导 ...
- 『PyTorch』第三弹_自动求导
torch.autograd 包提供Tensor所有操作的自动求导方法. 数据结构介绍 autograd.Variable 这是这个包中最核心的类. 它包装了一个Tensor,并且几乎支持所有的定义在 ...
- PytorchZerotoAll学习笔记(三)--自动求导
Pytorch给我们提供了自动求导的函数,不用再自己再推导计算梯度的公式了 虽然有了自动求导的函数,但是这里我想给大家浅析一下:深度学习中的一个很重要的反向传播 references:https:// ...
- 从零开始学习MXnet(四)计算图和粗细粒度以及自动求导
这篇其实跟使用MXnet的关系不大,但对于我们理解深度学习的框架设计还是很有帮助的. 首先还是对promgramming models的一个简单介绍,这个东西实际上是在编译里面经常出现的东西,我们在编 ...
- Pytorch学习(一)—— 自动求导机制
现在对 CNN 有了一定的了解,同时在 GitHub 上找了几个 examples 来学习,对网络的搭建有了笼统地认识,但是发现有好多基础 pytorch 的知识需要补习,所以慢慢从官网 API进行学 ...
- Pytorch Tensor, Variable, 自动求导
2018.4.25,Facebook 推出了 PyTorch 0.4.0 版本,在该版本及之后的版本中,torch.autograd.Variable 和 torch.Tensor 同属一类.更确切地 ...
随机推荐
- 为cobbler自动化安装系统工具添加epel源
关于cobbler的安装及部署,参考:CentOS 6.5自动化运维之基于cobbler服务的自动化安装操作系统详解http://blog.csdn.net/reblue520/article/det ...
- idea开发swing(二)
闲话少说,书接idea开发swing(一). 程序编译完成后,需要打包发布,如果有fat_jar的同学可以通过该插件打包,这里是使用ant来打包,步骤如下: 一.编写build.xml <?xm ...
- TestNG测试方法
@Test(enabled = false)有助于禁用此测试用例. 分组测试是TestNG中的一个新的创新功能,使用<groups>标记在testng.xml文件中指定分组. 它可以在&l ...
- python 全栈开发,Day75(Django与Ajax,文件上传,ajax发送json数据,基于Ajax的文件上传,SweetAlert插件)
昨日内容回顾 基于对象的跨表查询 正向查询:关联属性在A表中,所以A对象找关联B表数据,正向查询 反向查询:关联属性在A表中,所以B对象找A对象,反向查询 一对多: 按字段:xx book ----- ...
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- POJ 2752 Seek the Name, Seek the Fame(next数组运用)
Seek the Name, Seek the Fame Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 24000 ...
- POJ 2456 3258 3273 3104 3045(二分搜索-最大化最小值)
POJ 2456 题意 农夫约翰有N间牛舍排在一条直线上,第i号牛舍在xi的位置,其中有C头牛对牛舍不满意,因此经常相互攻击.需要将这C头牛放在离其他牛尽可能远的牛舍,也就是求最大化最近两头牛之间的距 ...
- vtiger二次开发
搞了快两个星期的vtiger,慢慢的摸索到了一些东西 数据库相当的复杂,已有的模块我只是分析了下页面的加载,方法的调用 大部分时间在研究怎么添加新的功能模块,今天才知道模块可以通过输入命令的方式来添加 ...
- springboot+thymeleaf简单使用
关于springboot想必很多人都在使用,由于公司项目一直使用的是SpringMVC,所以自己抽空体验了一下springboot的简单使用. 环境搭建 springbooot的环境搭建可以说很灵活, ...
- BZOJ1819 [JSOI]Word Query电子字典 Trie
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1819 题意概括 字符串a与字符串b的编辑距离是指:允许对a或b串进行下列“编辑”操作,将a变为b或 ...