hadoop2.8 ha 集群搭建
简介:
最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群:
搭建步骤:
| 主机 | 别名 | 安装软件 | 现有进程 | 服务地址 |
| 192.168.248.138 | cdh1 | hadoop2.8 jdk1.8 | namenode DFSZKFailoverController | http://cdh1:50070 |
| 192.168.248.139 | cdh2 | hadoop2.8 jdk1.8 | namenode DFSZKFailoverController | http://cdh1:50070 |
| 192.168.248.140 | cdh3 | hadoop2.8 jdk1.8 | ResourceManager | |
| 192.168.248.141 | cdh4 | hadoop2.8 jdk1.8 zookeeper3.4.13 | QuorumPeerMain JournalNode DataNode NodeManager | http://cdh3:8088 |
| 192.168.248.142 | cdh5 | hadoop2.8 jdk1.8 zookeeper3.4.13 | QuorumPeerMain JournalNode DataNode NodeManager | |
| 192.168.248.143 | cdh6 | hadoop2.8 jdk1.8 zookeeper3.4.13 | QuorumPeerMain JournalNode DataNode NodeManager | |
| 192.168.248.144 | cdh7 | hadoop2.8 jdk1.8 | JournalNode DataNode NodeManager |
1> 关闭防火墙,禁止设置开机启动:
(1) //临时关闭 systemctl stop firewalld
(2) //禁止开机启动 systemctl disable firewalld

注意:centos7防火墙默认是:firewalld
centos6 的命令是:
//临时关闭
service iptables stop
//禁止开机启动
chkconfig iptables off
2> 修改selinux 属性为disabled
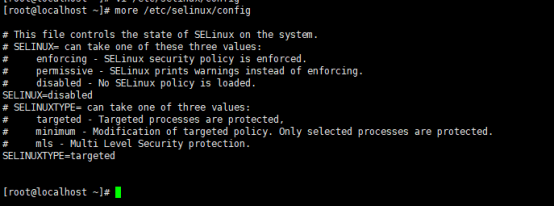
注意:修改了selinux或者修改了hostname需要重启使其生效【在这我没立即启动,下面配置好基础环境后再统一启动】
3> Yum 安装net-tools.x86_64和lrzsz.x86_64
(1) Net-tools是为了ifconfig yum install -y net-tools.x86_64
(2) Lrzsz是方便拖文件上传 yum install -y lrzsz.x86_64
因为我的镜像是,mini版的centos,除了基础命令和yum其他命令都需要自己安装。如果用完整版centos这些命令都已经集成进去了。
4> 准备集群所需要的相应软件安装包
(1) Jdk1.8
(2) Hadoop2.8
(3) Zookeeper3.4.13
暂时准备这这些基本软件,在cdh家目录下创建一个hadoop目录,把上述基本软件上传到该家目录下的hadoop文件夹下。
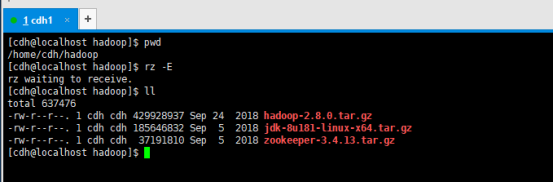
(4) 安装jdk【用root权限去安装】
① [cdh@localhost hadoop]$ tar -zxvf jdk-8u181-linux-x64.tar.gz
② 修改环境变量 vi ~/.bash_profile | vi /etc/profile
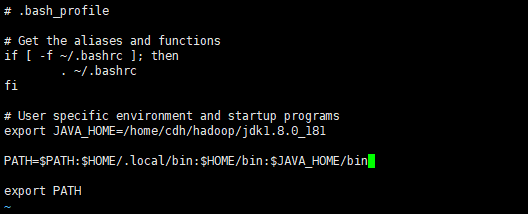
source ~/.bash_profile 使其生效
Java -version 验证安装是否成功
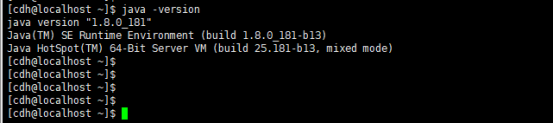
到这cdh1号机器基本软件安装完成:下面我来关闭cdh1来克隆几份服务器,这样cdh1安装配置那些软件和配置都会同步过去。克隆步骤如下
(1) 首先关闭cdh1服务器,因为在启动和挂起的状态下无法克隆机器。

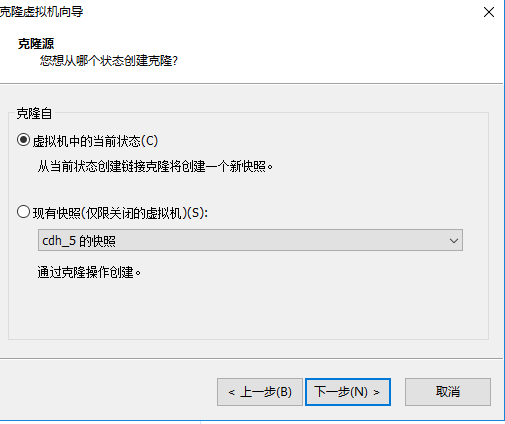
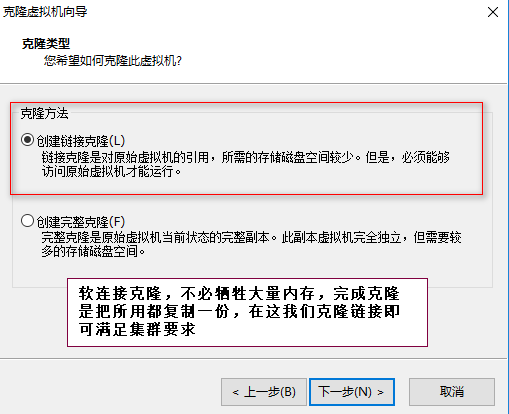
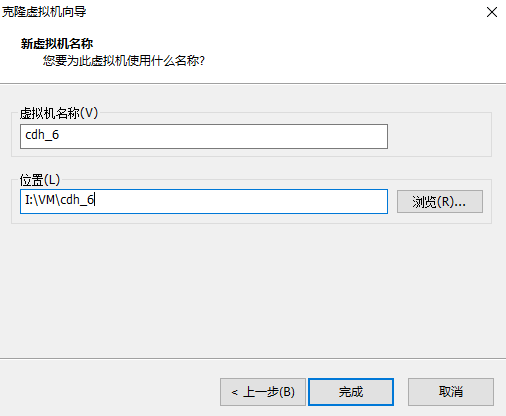


启动cdh1-cdh7 在xshell中建立对七个虚机的连接
注意,在这我使用的不是root用户,都是普通用户cdh
5> 安装hadoop集群的准备工作:
(1) 修改主机名:
root用户登录
vi /etc/hostname
自定义主机名
重启 reboot
(2) ssh免密登录问题。
分别在每个节点上生成公钥私钥:
cd /root/.ssh
ssh-keygen -t rsa三次回车
cp id_rsa.pub authorized_keys
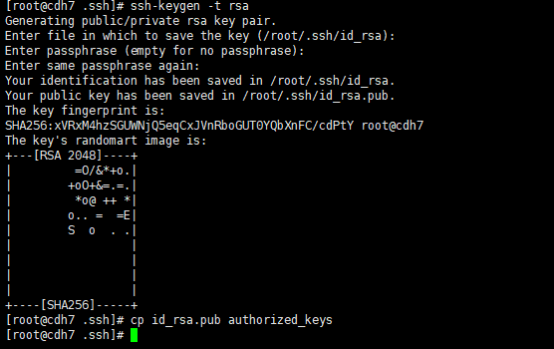
复制秘钥报错,是因为解析主机报错。配置/etc/hosts即可

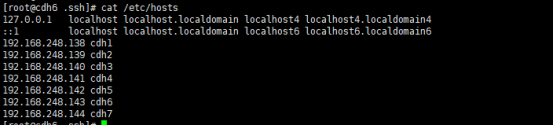
将cdh2、cdh3、cdh4、cdh5、cdh6,cdh7的私钥复制到cdh1节点上:
在cdh2节点上执行:ssh-copy-id -i cdh1
在cdh3节点上执行:ssh-copy-id -i cdh1
在cdh4节点上执行:ssh-copy-id -i cdh1
在cdh5节点上执行:ssh-copy-id -i cdh1
在cdh6节点上执行:ssh-copy-id -i cdh1
在cdh7节点上执行:ssh-copy-id -i cdh1
将cdh1节点上的authorized_keys复制给cdh2、cdh3、cdh4、cdh5、cdh6,cdh7节点:
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh2:/root/.ssh/
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh3:/root/.ssh/
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh4:/root/.ssh/
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh5:/root/.ssh/
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh6:/root/.ssh/
在cdh1节点上执行:scp /root/.ssh/authorized_keys cdh7:/root/.ssh/
验证ssh免密码登录(包括登录自己):
在cdh1节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh2节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh3节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh4节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh5节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh6节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
在cdh7节点上执行:ssh cdh1、ssh cdh2、ssh cdh3、ssh cdh4、ssh cdh5、ssh cdh6,ssh cdh7
6> 在cdh1节点上配置hadoop2.8
(1) 配置hadoop环境变量
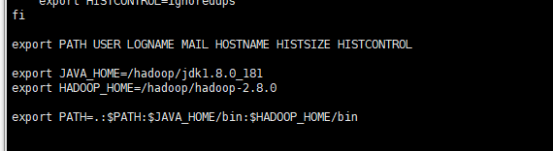
source /etc/profile 保存生效
(2) 修改位于hadoop/etc/hadoop下的配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves)
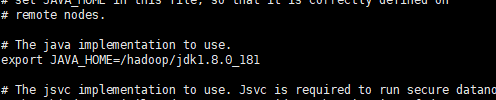
修改hadoop-env.sh:
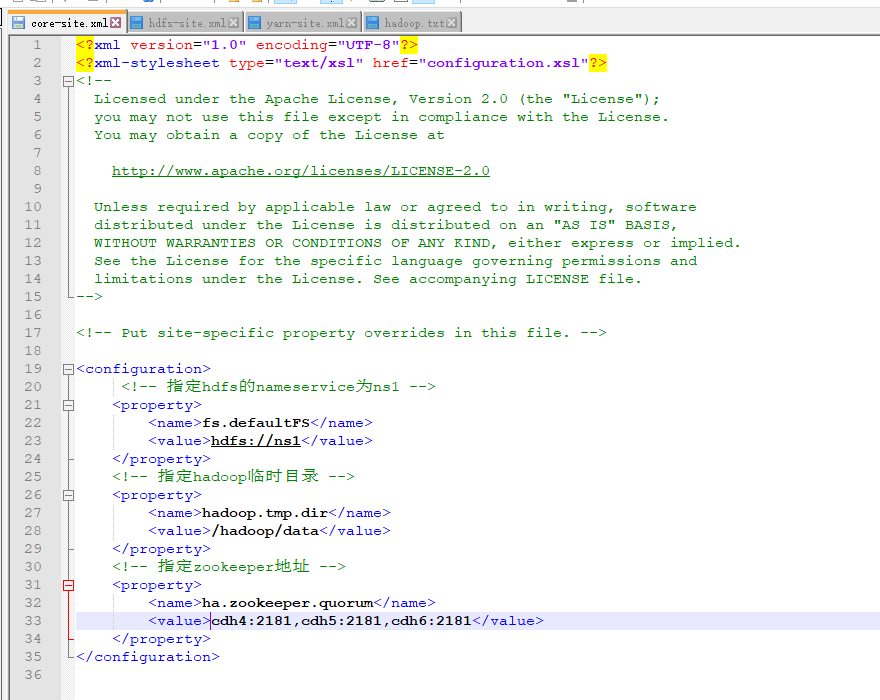
修改core-site.xml
修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>cdh1:</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>cdh1:</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>cdh2:</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>cdh2:</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cdh4:8485;cdh5:8485;cdh6:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/cloud/hadoop/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
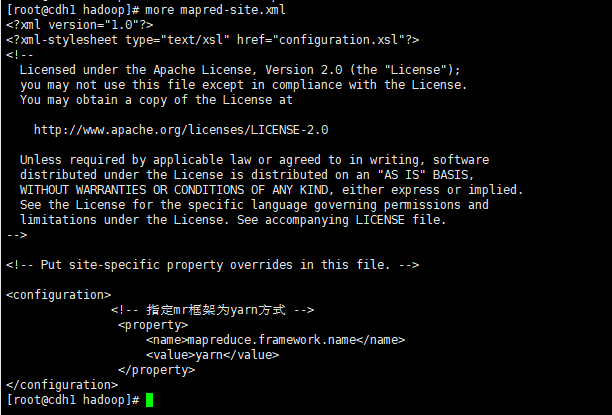
修改mapred-site.xml
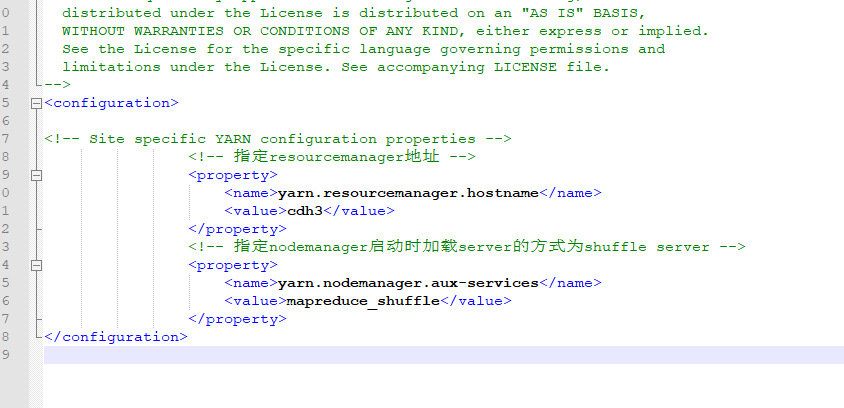
修改yarn-site.xml
修改slaves:(datanode节点设置,cdh7是我预留的机器,装ozzie或者pig的暂时不放入datanode节点中)【如果需要把其他机器作为datanode节点。只需要在这配置,然后同步到其他机器上,然后namenode重新格式化即可】
cdh4
cdh5
cdh6
注意:core-site.xml中指定了hadoop数据存放的本地磁盘路径是/hadoop/data,而这个/hadoop/下data文件夹是不存在需要创建;
hdfs-site.xml中指定了JournalNode在本地磁盘存放数据的位置是/hadoop/journal,而/hadoop/下的journal文件夹是不存在的需要创建。
此上6个配置文件都是hdp1节点上的,修改完成后将配置好的环境变量/etc/profile文件、/cloud/jdk文件夹和/cloud/hadoop文件夹复制到其他节点:
在hdp1节点上执行: scp -r /hadoop/ cdh2:/
在hdp1节点上执行: scp -r /hadoop/ cdh3:/
在hdp1节点上执行: scp -r /hadoop/ cdh4:/
在hdp1节点上执行: scp -r /hadoop/ cdh5:/
在hdp1节点上执行: scp -r /hadoop/ cdh6:/
在hdp1节点上执行: scp -r /hadoop/ cdh7:/
将环境变量/etc/profile文件复制到其他节点(在其他节点上要执行source /etc/profile使其修改立即生效):
scp /etc/profile cdh2:/etc/
scp /etc/profile cdh3:/etc/
scp /etc/profile cdh4:/etc/
scp /etc/profile cdh5:/etc/
scp /etc/profile cdh6:/etc/
scp /etc/profile cdh7:/etc/
7> 在cdh4,cdh5,cdh6配置zk集群
cd /hadoop/目录下
解压zookeeper-3.4.13.tar.gz:tar -zxvf zookeeper-3.4.13.tar.gz(当前目录下多了一个zookeeper-3.4.13文件夹)
重命名zookeeper-3.4.13:mv zookeeper-3.4.13 zookeeper
cd到/hadoop/zookeeper/conf/目录下:cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改:dataDir=/hadoop/zookeeper/data
在最后面添加:
server.1=cdh4:2888:3888
server.2=cdh5:2888:3888
server.3=cdh6:2888:3888
在/hadoop/zookeeper/创建data文件夹,进入/hadoop/zookeeper/data下创建myid文件,内容为1
将/hadoop/zookeeper文件夹复制到cdh5和cdh6下:
在cdh4节点上执行:scp -r /hadoop/zookeeper cdh5:/hadoop/
在cdh4节点上执行:scp -r /hadoop/zookeeper cdh6:/hadoop/
在cdh5节点上修改/hadoop/zookeeper/data/myid为2
在cdh6节点上修改/hadoop/zookeeper/data/myid为3
启动zk集群:
启动cdh4、cdh5和cdh6节点上的zk
分别在每个节点上执行:
cd /hadoop/zookeeper/bin目录下
启动zk:./zkServer.sh start
查看状态:
zkServer.sh status(leader或follower)
jps后多出来个quorumpeerMain
8> 8在cdh1节点上启动journalnode(会启动所有journalnode)
cd /hadoop/hadoop-2.8.0/sbin目录下
启动journalnode:hadoop-daemons.sh start journalnode(在cdh4、cdh5和cdh6节点上运行jps命令检验,多了JournalNode进程)
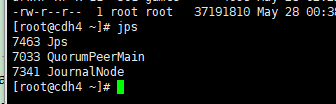
9> 在hdp1节点上格式化HDFS
格式化HDFS:hadoop namenode -format
将格式化后生成的hadoop的数据文件都在hdp1节点上,需要将hdp1节点上的数据同步到hdp2节点上,因为hdp1节点和hdp2节点是ha,这里我直接复制:
scp -r /hadoop/data hdp2:/hadoop
10> 在cdh1节点上格式化ZK
格式化ZK:hdfs zkfc -formatZK
11> 在cdh1节点上启动HDFS
cd /cloud/hadoop/sbin目录下
启动HDFS:start-dfs.sh
12> 在cdh3节点上启动YARN
cd /hadoop/hadoop2.8.0/sbin目录下
启动YARN:start-yarn.sh
13> 验证namenode
验证cdh1节点上的NameNode:jps或者http://cdh1:50070
验证cdh2节点上的NameNode:jps或者http://cdh2:50070
验证cdh3节点上的YARN:jps或者http://cdh3:8088/
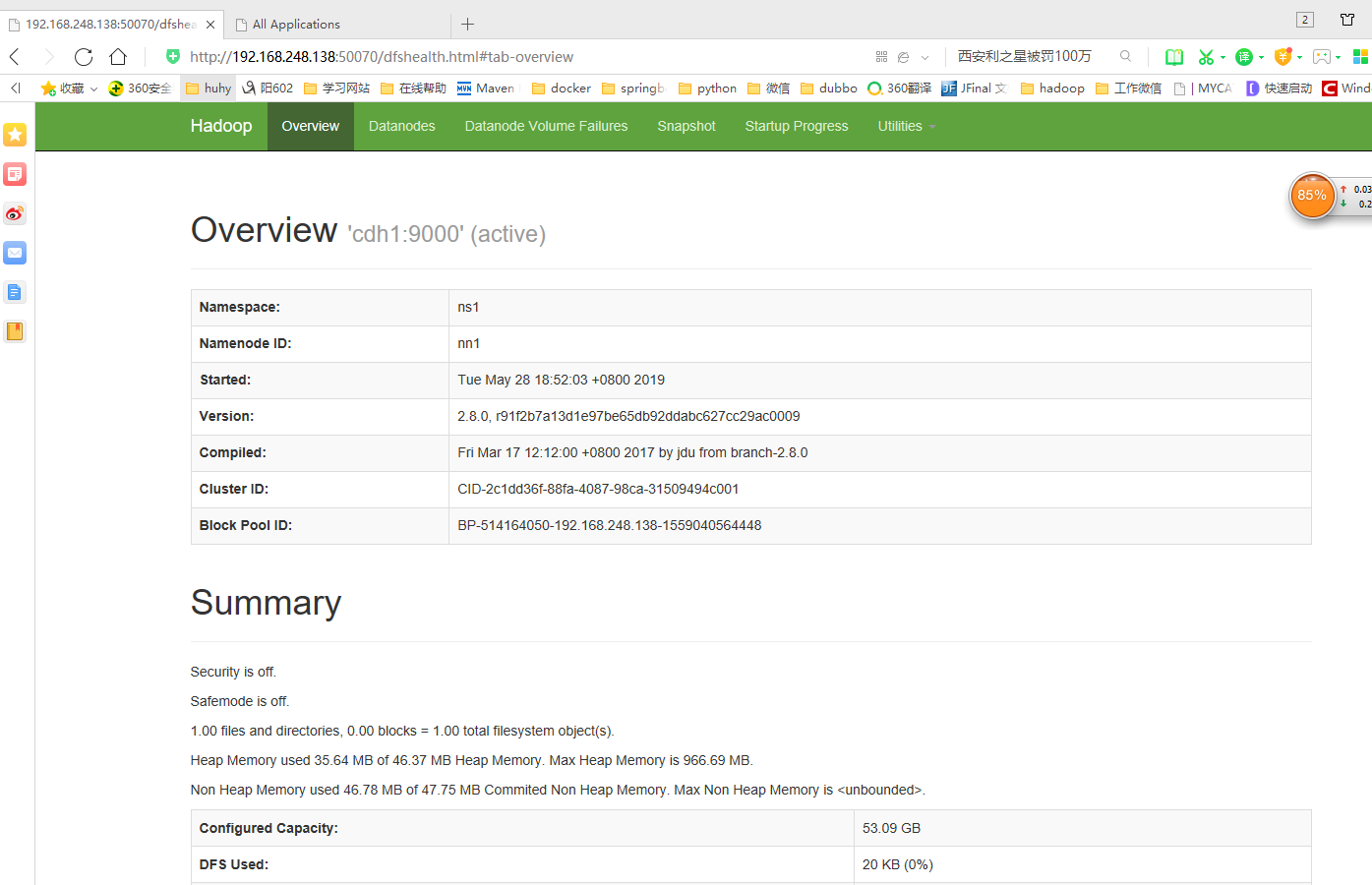

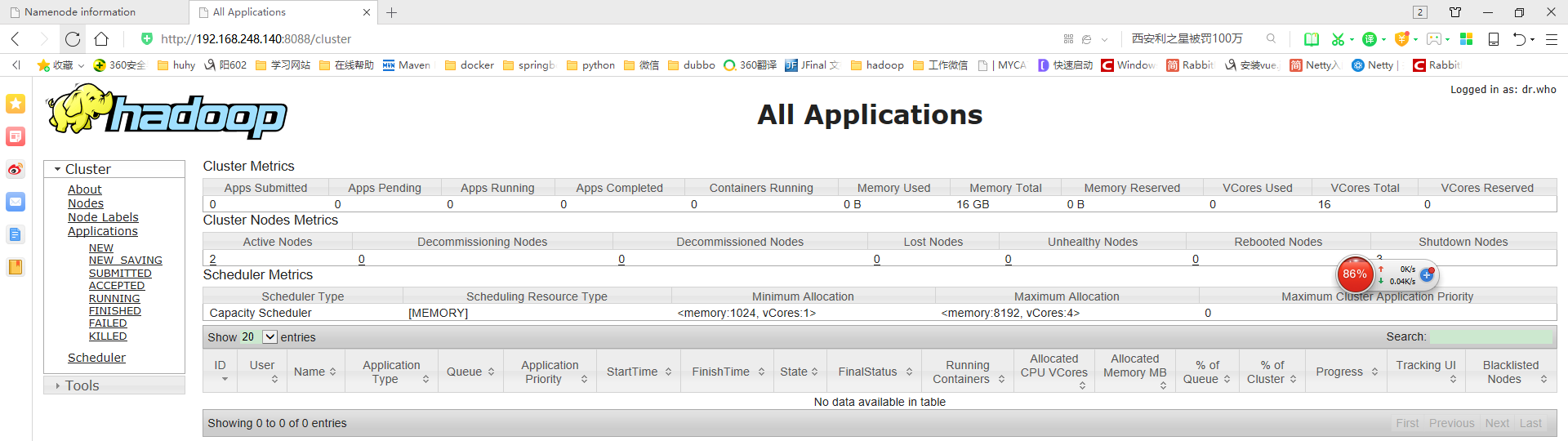
到这,hadoop的高可用集群已经搭建好了,有兴趣的可以仔细看看搭建过程
补充:各节点的启动进程 (jps看)
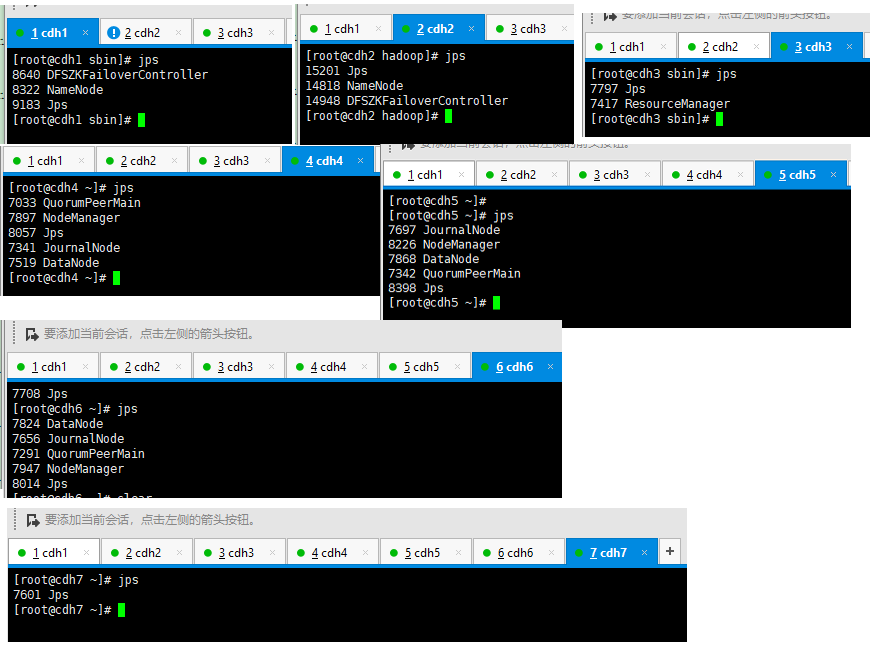
hadoop2.8 ha 集群搭建的更多相关文章
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- hadoop2.7.2集群搭建
hadoop2.7.2集群搭建 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.7.2/etc/hadoop目录,修改hadoop-env.sh,core-sit ...
- hadoop2.6.0集群搭建
p.MsoNormal { margin: 0pt; margin-bottom: .0001pt; text-align: justify; font-family: Calibri; font-s ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- centos下hadoop2.6.0集群搭建详细过程
一 .centos集群环境配置 1.创建一个namenode节点,5个datanode节点 主机名 IP namenodezsw 192.168.129.158 datanode1zsw 192.16 ...
- Hadoop2.6.5集群搭建
一. Hadoop的分布式模型 Hadoop通常有三种运行模式:本地(独立)模式.伪分布式(Pseudo-distributed)模式和完全分布式(Fully distributed)模式.安装完成后 ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
随机推荐
- spring的multipartResolver和java后端获取的MultipartHttpServletRequest方法对比
这两天在用spring进行上传上遇到问题,今天进行了问题的排查,这个过程也增加了我看spring源码的兴趣!还是很有收获的! 首先先给A组提供了上传接口,并没有在spring的配置文件进行multip ...
- Java基础 awt Graphics2D 生成矩形图片并向其中画一条直线
JDK :OpenJDK-11 OS :CentOS 7.6.1810 IDE :Eclipse 2019‑03 typesetting :Markdown code ...
- Logstash动态模板映射收集Nginx的Json格式日志
Logstash传输给ES的数据会自动映射为5索引,5备份,字段都为text的的索引.这样基本上无法进行数据分析.所以必须将Logstash的数据按照既定的格式存储在ES中,这时候就要使用到ES模板技 ...
- ES6 - 数组扩展(扩展运算符)
扩展运算符 扩展运算符(spread)是三个点(...).它好比 rest 参数的逆运算(函数),将一个数组转为用逗号分隔的参数序列. rest: 变量将多余的参数放入数组中. spread(扩展): ...
- Vue 自定义按键修饰符
如点击F2 触发某个事件 <input type="button" name="" id="" value="添加" ...
- Redis (error) NOAUTH Authentication required.
首先查看redis设置密码没 127.0.0.1:6379> config get requirepass 1) "requirepass" 2) "" ...
- 【APM】Pinpoint 监控告警(三)
本例介绍Pinpoint告警的相关内容,Pinpoint参考[APM]Pinpoint 安装部署(一) Pinpoint Web会定期检查应用程序的状态,并在满足某些预配置条件(规则)的情况下触发警报 ...
- MySQL 使用 ON UPDATE CURRENT_TIMESTAMP 自动更新 timestamp (转)
原文地址: https://blog.csdn.net/heatdeath/article/details/79833492 `create_time` timestamp not null defa ...
- TransactionScope处理分布式事物时提示"事务已被隐式或显式提交,或已终止"
在连接字符串中加入"Enlist=false",问题就这样解决了. ConnectionString = "Data Source=.;Initial Catalog=c ...
- (三)Java数据结构和算法——冒泡、选择、插入排序算法
一.冒泡排序 冒泡算法的运作规律如下: ①.比较相邻的元素.如果第一个比第二个大,就交换他们两个. ②.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.这步做完后,最后的元素会是最大的数( ...