CMU Database Systems - Parallel Execution
并发执行,主要为了增大吞吐,降低延迟,提高数据库的可用性
先区分一组概念,parallel和distributed的区别
总的来说,parallel是指在物理上很近的节点,比如本机的多个线程或进程,不用考虑通信代价
distributed,要充分的考虑通信代价,failover的问题,更为复杂

Process Model
先解释一下概念,
process model,指数据库系统架构设计,用于支持多用户的并发请求
worker,用于执行客户端tasks的DBMS组件

通常的process model有3种,
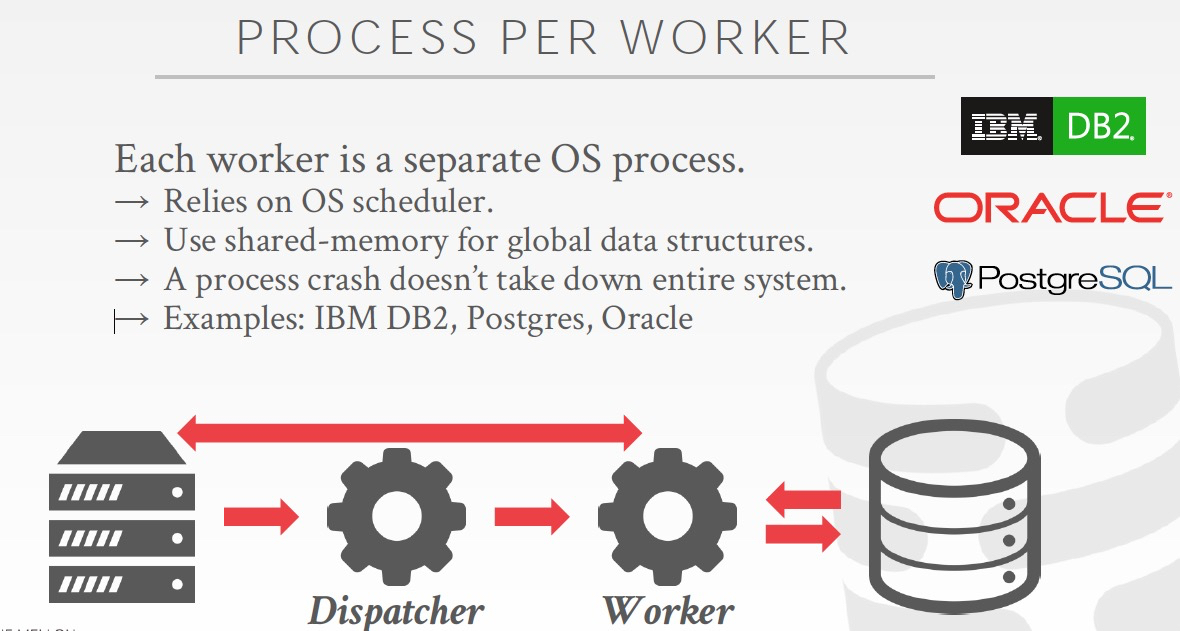
Process Per Worker,每个worker都是一个系统进程,
进程最大优点,隔离好,不会因为一个worker影响整个库,但问题肯定是太重,比较低效,支持不了高并发
早期的数据库往往采用这个方案,是因为那个时候线程的方案还不成熟
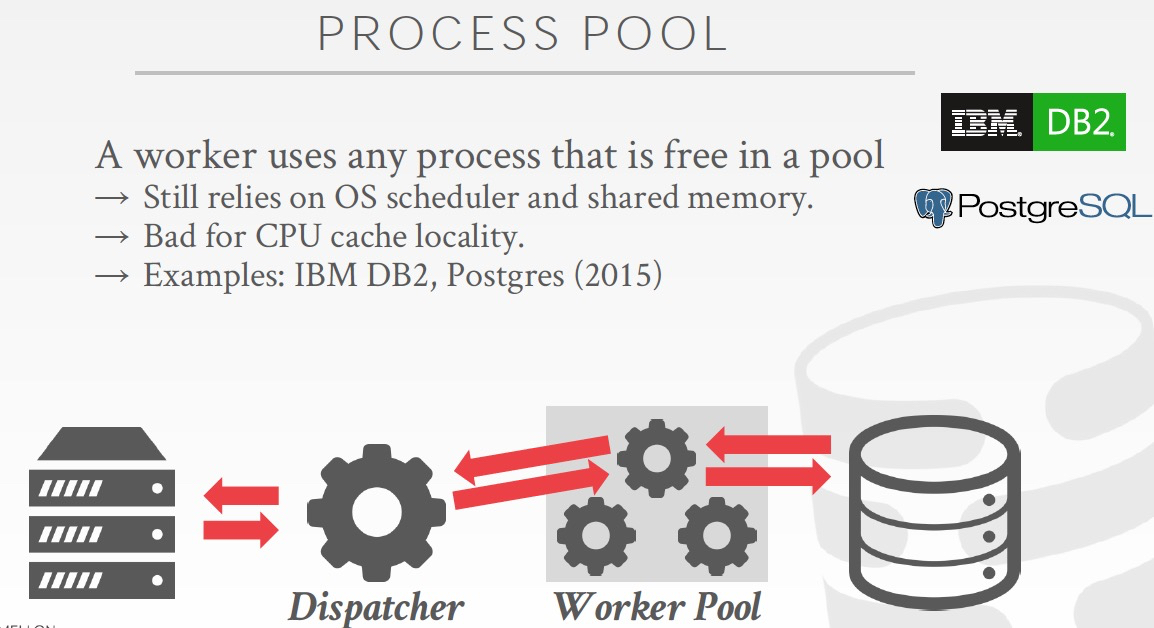
Process Pool,这个方案和上面的没有本质不同,只是worker从只用一个进程,到使用一个进程pool
Pool的好处,一个worker可以同时相应多个请求,而且一个进程hang住了,不会影响worker工作
坏处,一个client的连续的请求会分配到不同的进程,那么CPU cache locality上就不是很好
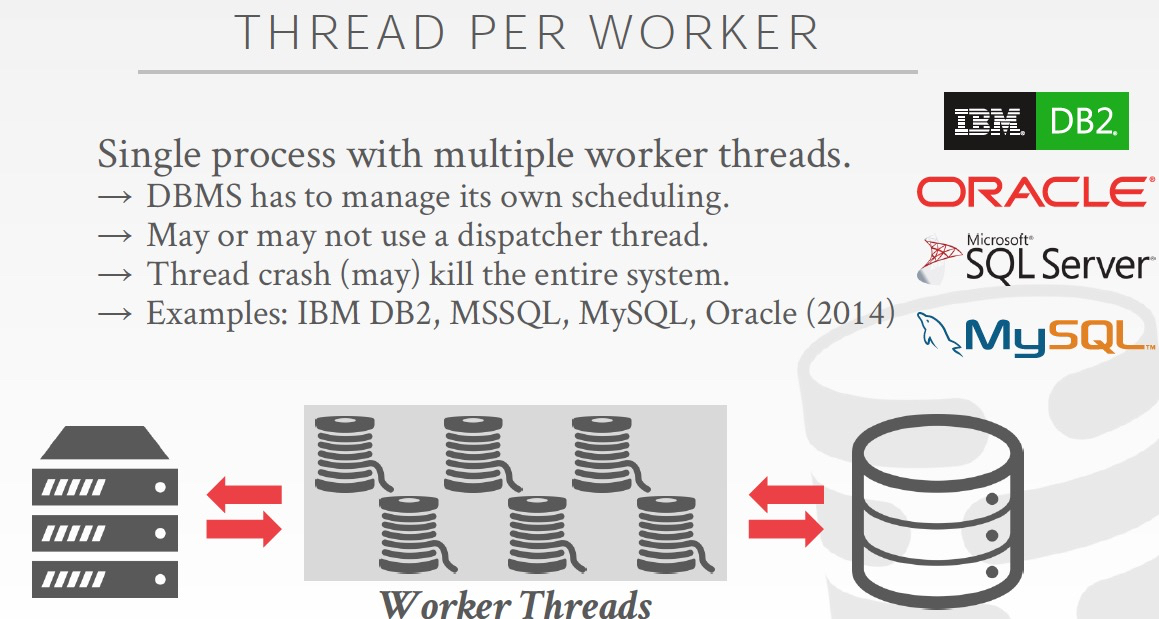
Thread Per Worker
这个是当前主流的process model,
一个数据库实例是一个进程,worker通过线程实现,这样由DBMS自己进行线程调度
线程模型明显更加轻量,更容易应对高并发的场景,而且线程间通信的成本很低
最大的问题是隔离性不好,一个线程可能把整个库搞挂

Parallel Execution
并行有两种,
不同的query,并行的执行
一条query中不同的operation并行的执行

Inter-query,很容易理解,要解决的也就是并发控制问题,这个后面会讲
这里重点说下Intra-query,它也是包含两种类型,Intra-operator和Inter-operator
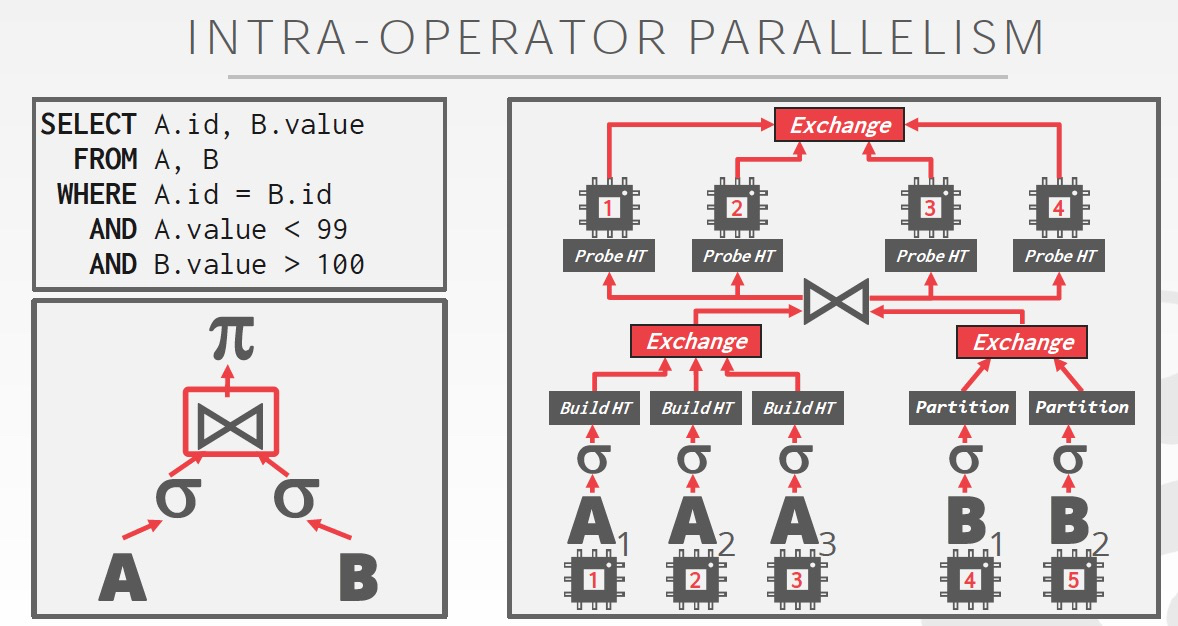
首先是Intra-operator,水平并行,MPP
把数据水平分成多份,分别执行,有个Exchange,类似latch,等待所有分片都执行完,做相应的merge然后再往上发送

然后是,Inter-operator,DAG方式,pipeline,streaming process

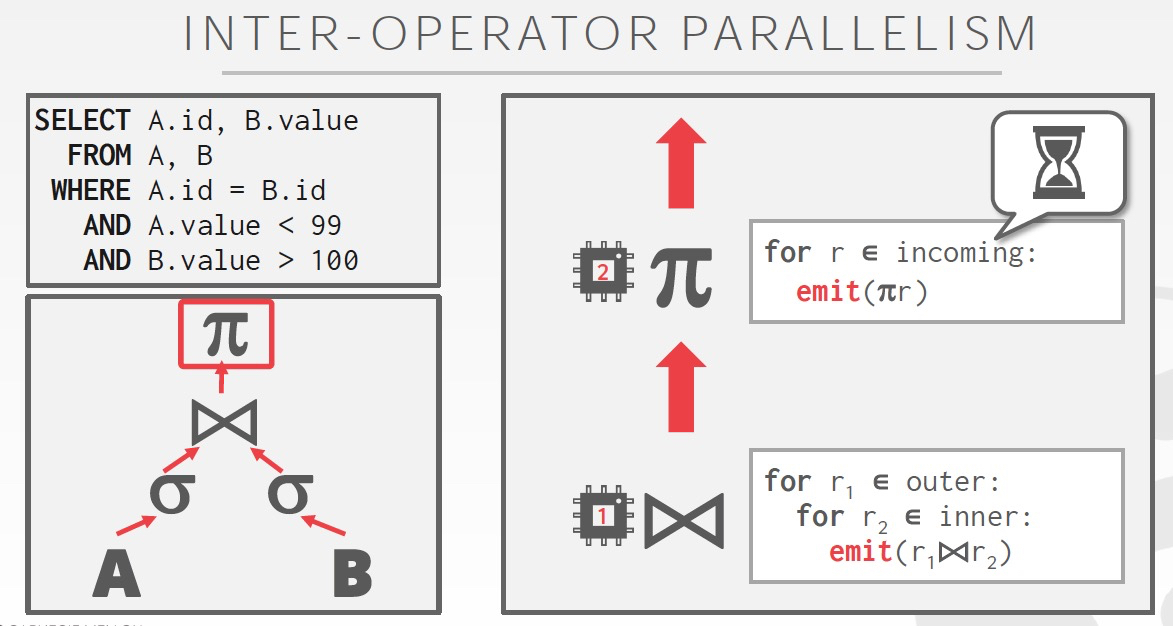
I/O PARALLELISM
前面光说了,平行处理,但是数据库的瓶颈大部分在磁盘IO
所以如果要并行计算,关键是数据要能划分开,并行的读取
一些比较简单的方法如下,
人为的分多块盘,或是用raid0,raid1

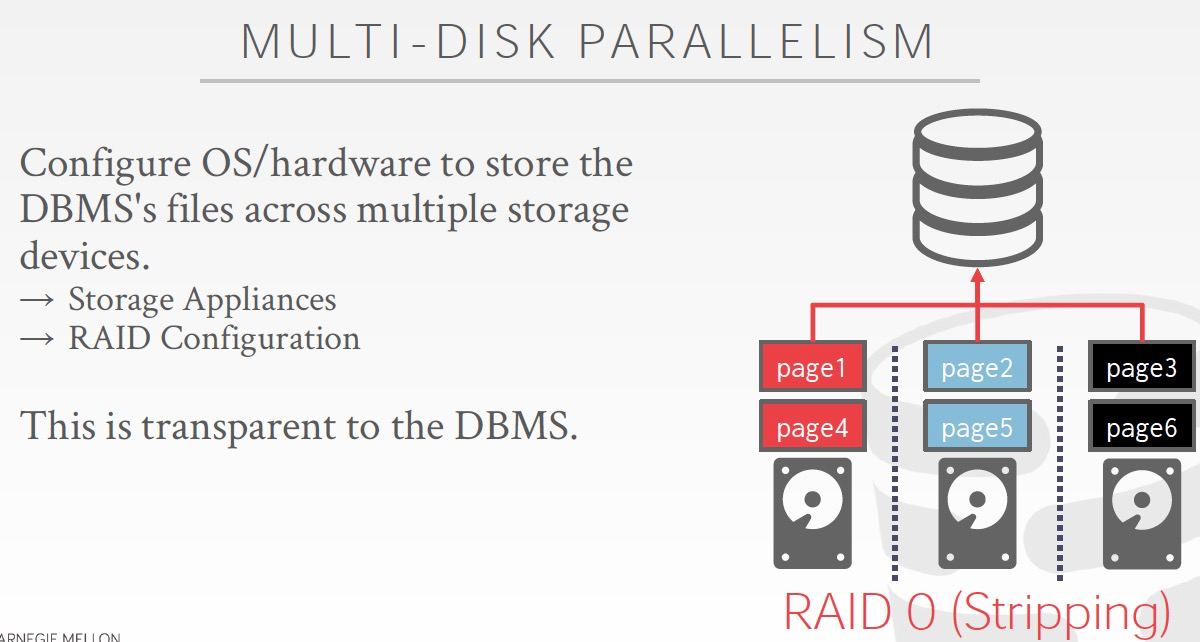
但是如果要在表级别做划分,就需要更为复杂的方法,对数据做partition

划分又分为两种,
垂直划分,列存
水平划分,sharding


CMU Database Systems - Parallel Execution的更多相关文章
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
- CMU Database Systems - Embedded Database Logic
正常应用和数据库交互的过程是这样的, 其实我们也可以把部分应用逻辑放到DB端去执行,来提升效率 User-defined Function Stored Procedures Triggers Cha ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
随机推荐
- ssh无密码连接
1. 生成密钥对文件 [root@centos2 ~]# -t 指定加密类型 -b 指定密钥对加密长度 询问1:执行过程中会询问保存位置,一般默认保存在当前用户家目录下的.ssh/目录下 询问2:是否 ...
- Linux中rpm命令用法
rpm -ivh 软件包名 安装软件包并显示安装进度.这个是用得最多的了. rpm -qa 查询已经安装哪些软件包. rpm -q 软件包名 查询指定软件包是否已经安装. rpm -Uvh 软件包名 ...
- 生成1~n的排列(模板),生成可重集的排列(对应紫书P184, P185)
生成1~n的排列: #include<iostream> using namespace std; void print_permutation(int n, int *A, int cu ...
- Linux postfix配置方法
第七题 配置邮件服务器 postfix学习网站:https://blog.csdn.net/mycms5/article/details/78773308 system1和systemc2分别执行 ...
- linux系统编程之进程(五)
今天继续学习系统编程,学习的主题还是进程,今天主要讨论的是守护进程相关的概念,开始进入正题: 什么是守护进程: 守护进程的创建步骤: 在描述它之前,首先得先了解两个概念:进程组.会话期: ...
- Multiple declaration for 'fd_set'
如果程序编译时报 [C++ Error] winsock2.h(109): E2238 Multiple declaration for 'fd_set' 这样的错误,可以尝试在,winsock2.h ...
- P1341 无序字母对[欧拉路]
题目描述 给定n个各不相同的无序字母对(区分大小写,无序即字母对中的两个字母可以位置颠倒).请构造一个有n+1个字母的字符串使得每个字母对都在这个字符串中出现. 解析 毒瘤字符串读入 我就是不喜欢邻接 ...
- used to do 与be used to doing /n.
1.used to do:表示过去的习惯性动作,过去如此,现在不再这样了.常译作“过去常常”.(过去时+动词不定式) He used to play basketball when he was yo ...
- webpack起服务器报JavaScript heap out of memory
配置如下: { "scripts": { "start": "node --max_old_space_size=4096 node_modules/ ...
- ServletContext对象应用——三天免登录
1.用到的知识点: (1)Cookie (2)Session (3)ServletContext 其中Cookie和Session是会话技术的组成部分,一次会话从打开浏览器的某个站点开始,到浏览器关闭 ...