分类模型的评价指标Fscore
分类方法常用的评估模型好坏的方法.
0.预设问题
假设我现在有一个二分类任务,是分析100封邮件是否是垃圾邮件,其中不是垃圾邮件有65封,是垃圾邮件有35封.模型最终给邮件的结论只有两个:是垃圾邮件与 不是垃圾邮件.
经过自己的努力,自己设计了模型,得到了结果,分类结果如下:
- 不是垃圾邮件70封(其中真实不是垃圾邮件60封,是垃圾邮件有10封)
- 是垃圾邮件30封(其中真实是垃圾邮件25封,不是垃圾邮件5封)
现在我们设置,不是垃圾邮件.为正样本,是垃圾邮件为负样本
我们一般使用四个符号表示预测的所有情况:
- TP(真阳性):正样本被正确预测为正样本,例子中的60
- FP(假阳性):负样本被错误预测为正样本,例子中的10
- TN(真阴性):负样本被正确预测为负样本,例子中的25
- FN(假阴性):正样本被错误预测为负样本,例子中的5
1.评价方法介绍
先看最终的计算公式:

1.Precision(精确率)
关注预测为正样本的数据(可能包含负样本)中,真实正样本的比例
计算公式

例子解释:对上前面例子,关注的部分就是预测结果的70封不是垃圾邮件中真实不是垃圾邮件占该预测结果的比率,现在Precision=60/(600+10)=85.71%
2.Recall(召回率)
关注真实正样本的数据(不包含任何负样本)中,正确预测的比例
计算公式
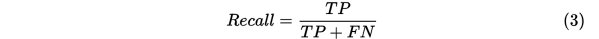
例子解释:对上前面例子,关注的部分就是真实有65封不是垃圾邮件,这其中你的预测结果中有多少预测正确了,Recall=60/(60+5)=92.31%
3.F-score中β值的介绍
β是用来平衡Precision,Recall在F-score计算中的权重,取值情况有以下三种:
- 如果取1,表示Precision与Recall一样重要
- 如果取小于1,表示Precision比Recall重要
- 如果取大于1,表示Recall比Precision重要
一般情况下,β取1,认为两个指标一样重要.此时F-score的计算公式为:
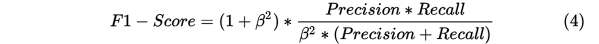
前面计算的结果,得到Fscore=(2*0.8571*0.9231)/(0.8571+0.9231)=88.89%
3.其他考虑
预测模型无非就是两个结果
- 准确预测(不管是正样子预测为正样本,还是负样本预测为负样本)
- 错误预测
那我就可以直接按照下面的公式求预测准确率,用这个值来评估模型准确率不就行了

那为什么还要那么复杂算各种值.理由是一般而言:负样本远大于正样本。
可以想象,两个模型的TN变化不大的情况下,但是TP在两个模型上有不同的值,TN>>TP是不是可以推断出:两个模型的(TN+TP)近似相等.这不就意味着两个模型按照以上公式计算的Accuracy近似相等了.那用这个指标有什么用!!!
所以说,对于这种情况的二分类问题,一般使用Fscore去评估模型.
需要注意的是:Fscore只用来评估二分类的模型,Accuracy没有这限制
参考
1.机器学习中的 precision、recall、accuracy、F1 Score
2.分类模型的评估方法-F分数(F-Score)
分类模型的评价指标Fscore的更多相关文章
- 【AUC】二分类模型的评价指标ROC Curve
AUC是指:从一堆样本中随机抽一个,抽到正样本的概率比抽到负样本的概率大的可能性! AUC是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如logloss,acc ...
- 分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0): TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1) FP(False Positive):预测为正类,但预测错 ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- MXNET:分类模型
线性回归模型适用于输出为连续值的情景,例如输出为房价.在其他情景中,模型输出还可以是一个离散值,例如图片类别.对于这样的分类问题,我们可以使用分类模型,例如softmax回归. 为了便于讨论,让我们假 ...
- Spark学习笔记——构建分类模型
Spark中常见的三种分类模型:线性模型.决策树和朴素贝叶斯模型. 线性模型,简单而且相对容易扩展到非常大的数据集:线性模型又可以分成:1.逻辑回归:2.线性支持向量机 决策树是一个强大的非线性技术, ...
- 利用libsvm-mat建立分类模型model参数解密[zz from faruto]
本帖子主要就是讲解利用libsvm-mat工具箱建立分类(回归模型)后,得到的模型model里面参数的意义都是神马?以及如果通过model得到相应模型的表达式,这里主要以分类问题为例子. 测试数据使用 ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
随机推荐
- 让div在body中任意拖动
HTML代码 <div id="idOuterDiv" class="CsOuterDiv"> </div> CSS代码 body { ...
- 递归-求n和n以前的自然数
#include <iostream> using namespace std; void zrs(int n)//用递归求自然数(n和它之前) { ) { cout<<< ...
- python --- Socketserver N部曲(1)
曲一 socketserver 是为了简化服务器端开发而产生的,是一个高级的标准库.(背景介绍完毕,开始干) 一些概念 来自源码的一张图片,简洁又FengSao +------------+ | Ba ...
- 【开发笔记】-MySQL数据库5.7+版本,编码格式设置
原因 昨天不小心把数据库搞崩了,重装了5.7.27版本得mysql数据库,在安装过程中并没有设置数据库默认编码格式等操作.在把项目启动后,jpa自动创建表结构,会把数据库,表,字段的编码自动设置为IS ...
- 如何使用Python的Django框架创建自己的网站
如何使用Python的Django框架创建自己的网站 Django建站主要分四步:1.创建Django项目,2.将网页模板移植到Django项目中,3.数据交互,4.数据库 1创建Django项目 本 ...
- 排序算法的c++实现——插入排序
插入排序的思想是:给定一个待排序的数组,我们从中选择第一个元素作为有序的基态(单个元素肯定是有序的), 然后从剩余的元素中选择一个插入到有序的基态中,使插入之后的序列也是有序状态,重复此过程,直到全部 ...
- 【故障处理】imp-00051,imp-00008
[故障处理]imp-00051,imp-00008 1.1 BLOG文档结构图 1.2 故障分析及解决过程 imp导入报错: IMP-00051: Direct path exported dum ...
- 解决Android studio导航tools下没有android怎么打开DDMS工具
因为这个功能用的人少, 新版本就去掉菜单入口了, 但这个功能并没有删除,打开方式:点开terminal ,也就是AS自带的命令行工具, 输入monitor 回车就启动了, 1.点开terminal 2 ...
- K8S概念理解参考
- 实例讲解ip地址、子网掩码、可用地址范围的计算
关于ip以及相关的掩码.网络号等概念可以查看相关的博客.资料,这些东西很容易找着,一搜一大片.本文主要记录通过实例进行ip相关的计算. 我自己使用的在线网络计算器地址:https://www.sojs ...