最新 Zookeeper + Flume + Kafka 简易整合教程
在大数据领域有很多耳熟能详的框架,今天要介绍的就是 zookeeper、flume、kafka。因为平时是做数据接入的,所以对这些实时的数据处理系统不是很熟悉。通过官网的简要介绍,搭建了一套简要的平台,主要实现的功能是消费 kafka 中从 flume 传递过来的消息,当让为了方便这里所有的输入输出都在控制台完成。当然注意我所使用的版本,切不可生搬硬套,这是学习技术的大忌,当然这些系统都是在 Linux 或者 macOS 系统下运行的,如果是Windows就不要尝试了。
其实大数据平台上面有很多优秀的系统,很多都是分布式的,这些系统的架构比我们平时写的业务系统要复杂的多。但是时间有限,下面简要说明各个组件作用,至于原理等细节不做讲解,如果以后自己研究透了再分享给大家。
配置 Zookeeper - 3.4.8
Zookeeper 是一个很稳定的系统,我自己没有用过。但是印象中它是很可靠的,几乎是不会宕机的,因为它有一个选举机制,某个主节点挂掉了会从新选举一个主节点,大数据平台有的框架主节点宕机了整个集群就不可用了。因为上述的原因,所以一些可靠性要求高的系统会使用到,例如 Hbase,还有今天用到的 Kafka。
- 下载Zookeeper
下载地址:http://apache.mirrors.lucidnetworks.net/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz 解压Zookeeper
解压也很简单,使用tar命令来完成,你可以解压到自己想要的路径,下面的命令是解压到当前路径下tar -zxvf zookeeper-3.4.8.tar.gz配置Zookeeper
配置也很简单,官网也给出了说明,我这里简要配置一下。
官网配置教程:https://zookeeper.apache.org/doc/trunk/zookeeperStarted.html
其实主要是配置 zoo.cfg 来这个文件,在 conf 文件夹有一个 zoo_sample.cfg,我们只需要拷贝一份,更改一下名字,使用默认配置即可,不需要修改。cp zoo_sample.cfg zoo.cfg默认配置中 Zookeeper 的端口为 2181,这个端口很重要,后面配置 Kafka 会用到。
启动Zookeeper
使用下面的命令启动bin/zkServer.sh start上面的服务是一个后台服务,不会占用当前的控制台。
配置 Flume - 1.7.0
Flume的配置也很简单,需要我们配置两个文件,然后启动即可。
- 下载 Flume
下载地址:http://apache.claz.org/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz 解压 Flume
tar -zxvf apache-flume-1.7.0-bin.tar.gz配置 flume-env.sh
这里我们主要配置 JAVA_HOME 这个变量,因为我的是 macOS ,所以配置如下:export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home配置 source、channel、sink
这里简要讲述下三个术语的概念,source 用来描述我们数据的来源,channel用来描述数据缓存的类型,可以是内存,也可以是文件,sink 用来描述数据目的地。上述三个配置项都在 conf/flume.conf 中,我们可以从 flume-conf.properties.template 复制一份。cp flume-conf.properties.template flume.confflume.conf的配置信息如下:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
agent1.sources = avro-source1
agent1.channels = ch1
agent1.sinks = log-sink1
# For each one of the sources, the type is defined
agent1.sources.avro-source1.type = netcat
agent1.sources.avro-source1.bind=0.0.0.0
agent1.sources.avro-source1.port=41414
# The channel can be defined as follows.
agent1.sources.avro-source1.channels = ch1
# Each sink's type must be defined
agent1.sinks.log-sink1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.log-sink1.kafka.bootstrap.servers=0.0.0.0:9092
agent1.sinks.log-sink1.kafka.topic=test
#Specify the channel the sink should use
agent1.sinks.log-sink1.channel = ch1
# Each channel's type is defined.
agent1.channels.ch1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
agent1.channels.memoryChannel.capacity = 100如果对上述配置文件中的参数有不理解的可以自行百度了解,这里简要介绍下
几个配置项。
配置控制台为数据源
agent1.sources.avro-source1.type = netcat agent1.sources.avro-source1.bind=0.0.0.0 agent1.sources.avro-source1.port=41414这样配置我们 flume 就可以搜集到我们控制台输入的信息。
配置 Kafka 为数据源的目标端
agent1.sinks.log-sink1.type = org.apache.flume.sink.kafka.KafkaSink agent1.sinks.log-sink1.kafka.bootstrap.servers=0.0.0.0:9092 agent1.sinks.log-sink1.kafka.topic=test上面配置 flume 会将控制输入的信息写入到 kafka 中的 test 中,这里的主题 'test' 在后面中 kafka 需要创建。
- 启动 flume
执行下面的命令:
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n agent1最后的 agent1 是我们上面 flume.cfg 中配置过的,要与配置相配置。
启动后的输出:
Info: Sourcing environment configuration script /Users/chenxl/Documents/soft/apache-flume-1.7.0-bin/conf/flume-env.sh
+ exec /Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/bin/java -Xmx20m -Dflume.root.logger=DEBUG,console -cp '/Users/chenxl/Documents/soft/apache-flume-1.7.0-bin/conf:/Users/chenxl/Documents/soft/apache-flume-1.7.0-bin/lib/*' -Djava.library.path= org.apache.flume.node.Application -f conf/flume.conf -n agent1
2017-05-11 23:11:35,429 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2017-05-11 23:11:35,433 (lifecycleSupervisor-1-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:79)] Configuration provider started
2017-05-11 23:11:35,436 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:127)] Checking file:conf/flume.conf for changes
2017-05-11 23:11:35,437 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:134)] Reloading configuration file:conf/flume.conf
2017-05-11 23:11:35,442 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:log-sink1
2017-05-11 23:11:35,442 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1020)] Created context for log-sink1: channel
2017-05-11 23:11:35,442 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:930)] Added sinks: log-sink1 Agent: agent1
2017-05-11 23:11:35,442 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:log-sink1
2017-05-11 23:11:35,443 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:log-sink1
2017-05-11 23:11:35,443 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:log-sink1
2017-05-11 23:11:35,443 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.isValid(FlumeConfiguration.java:313)] Starting validation of configuration for agent: agent1
2017-05-11 23:11:35,444 (conf-file-poller-0) [INFO - org.apache.flume.conf.LogPrivacyUtil.<clinit>(LogPrivacyUtil.java:51)] Logging of configuration details is disabled. To see configuration details in the log run the agent with -Dorg.apache.flume.log.printconfig=true JVM argument. Please note that this is not recommended in production systems as it may leak private information to the logfile.
2017-05-11 23:11:35,448 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateChannels(FlumeConfiguration.java:467)] Created channel ch1
2017-05-11 23:11:35,454 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateSinks(FlumeConfiguration.java:674)] Creating sink: log-sink1 using OTHER
2017-05-11 23:11:35,455 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:135)] Channels:ch1
2017-05-11 23:11:35,455 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:136)] Sinks log-sink1
2017-05-11 23:11:35,457 (conf-file-poller-0) [DEBUG - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:137)] Sources avro-source1
2017-05-11 23:11:35,457 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:140)] Post-validation flume configuration contains configuration for agents: [agent1]
2017-05-11 23:11:35,457 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:147)] Creating channels
2017-05-11 23:11:35,463 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel ch1 type memory
2017-05-11 23:11:35,468 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:201)] Created channel ch1
2017-05-11 23:11:35,469 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source avro-source1, type netcat
2017-05-11 23:11:35,480 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: log-sink1, type: org.apache.flume.sink.kafka.KafkaSink
2017-05-11 23:11:35,480 (conf-file-poller-0) [DEBUG - org.apache.flume.sink.DefaultSinkFactory.getClass(DefaultSinkFactory.java:62)] Sink type org.apache.flume.sink.kafka.KafkaSink is a custom type
2017-05-11 23:11:35,487 (conf-file-poller-0) [INFO - org.apache.flume.sink.kafka.KafkaSink.configure(KafkaSink.java:302)] Using the static topic test. This may be overridden by event headers
2017-05-11 23:11:35,487 (conf-file-poller-0) [DEBUG - org.apache.flume.sink.kafka.KafkaSink.configure(KafkaSink.java:310)] Using batch size: 100
2017-05-11 23:11:35,487 (conf-file-poller-0) [DEBUG - org.apache.flume.sink.kafka.KafkaSink.configure(KafkaSink.java:320)] useFlumeEventFormat set to: false
2017-05-11 23:11:35,513 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:116)] Channel ch1 connected to [avro-source1, log-sink1]
2017-05-11 23:11:35,526 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:137)] Starting new configuration:{ sourceRunners:{avro-source1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:avro-source1,state:IDLE} }} sinkRunners:{log-sink1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@33583d6 counterGroup:{ name:null counters:{} } }} channels:{ch1=org.apache.flume.channel.MemoryChannel{name: ch1}} }
2017-05-11 23:11:35,527 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:144)] Starting Channel ch1
2017-05-11 23:11:35,594 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: ch1: Successfully registered new MBean.
2017-05-11 23:11:35,594 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: ch1 started
2017-05-11 23:11:35,595 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:171)] Starting Sink log-sink1
2017-05-11 23:11:35,595 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:182)] Starting Source avro-source1
2017-05-11 23:11:35,597 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting
2017-05-11 23:11:35,619 (lifecycleSupervisor-1-1) [INFO - org.apache.kafka.common.config.AbstractConfig.logAll(AbstractConfig.java:165)] ProducerConfig values:
compression.type = none
metric.reporters = []
metadata.max.age.ms = 300000
metadata.fetch.timeout.ms = 60000
reconnect.backoff.ms = 50
sasl.kerberos.ticket.renew.window.factor = 0.8
bootstrap.servers = [0.0.0.0:9092]
retry.backoff.ms = 100
sasl.kerberos.kinit.cmd = /usr/bin/kinit
buffer.memory = 33554432
timeout.ms = 30000
key.serializer = class org.apache.kafka.common.serialization.StringSerializer
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
ssl.keystore.type = JKS
ssl.trustmanager.algorithm = PKIX
block.on.buffer.full = false
ssl.key.password = null
max.block.ms = 60000
sasl.kerberos.min.time.before.relogin = 60000
connections.max.idle.ms = 540000
ssl.truststore.password = null
max.in.flight.requests.per.connection = 5
metrics.num.samples = 2
client.id =
ssl.endpoint.identification.algorithm = null
ssl.protocol = TLS
request.timeout.ms = 30000
ssl.provider = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
acks = 1
batch.size = 16384
ssl.keystore.location = null
receive.buffer.bytes = 32768
ssl.cipher.suites = null
ssl.truststore.type = JKS
security.protocol = PLAINTEXT
retries = 0
max.request.size = 1048576
value.serializer = class org.apache.kafka.common.serialization.ByteArraySerializer
ssl.truststore.location = null
ssl.keystore.password = null
ssl.keymanager.algorithm = SunX509
metrics.sample.window.ms = 30000
partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner
send.buffer.bytes = 131072
linger.ms = 0
2017-05-11 23:11:35,625 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:169)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:41414]
2017-05-11 23:11:35,626 (lifecycleSupervisor-1-0) [DEBUG - org.apache.flume.source.NetcatSource.start(NetcatSource.java:190)] Source started
2017-05-11 23:11:35,626 (Thread-1) [DEBUG - org.apache.flume.source.NetcatSource$AcceptHandler.run(NetcatSource.java:270)] Starting accept handler配置 Kafka -2.11-0.10.2.0
终于要到了最后一步了,到这一步已经完成 80% 的任务了。
- 下载 Kafka
下载地址:http://www.gtlib.gatech.edu/pub/apache/kafka/0.10.2.1/kafka_2.11-0.10.2.1.tgz 解压 Kafka
tar -zxvf kafka_2.11-0.10.2.1.tgz- 配置 Kafka
官方教程:http://kafka.apache.org/quickstart
因为 Kafka 的默认配置满足我们的需求,所以无需修改,如果你的其它组件的配置与我的不一样可以参考官方教程做修改。 启动 Kafka
bin/kafka-server-start.sh config/server.properties创建 topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test查看 topic
```
bin/kafka-topics.sh --list --zookeeper localhost:2181
* 创建 Kafka 消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
上面的命令执行之后不要退出 shell,因为这里会打印我们输入的信息。 ## 测试 * 在另外一个控制台执行下面的命令:
telnet localhost 41414
```
上面的命令我第一敲错了,主机和写成了'localhost:41414',导致无法连接到 flume,还好测试了几遍,最后对照官网发现了不同之处。可能是因为最近一直使用 Presto,这种写法敲顺手了,所以各位敲命令时要仔细,如果发现与预期不符要排查原因。
- 输入字符串
如果你在这里的控制台上面输入字符串,Kafka中的消费者会打印当前输入的字符串,下图展示下我的实验结果。
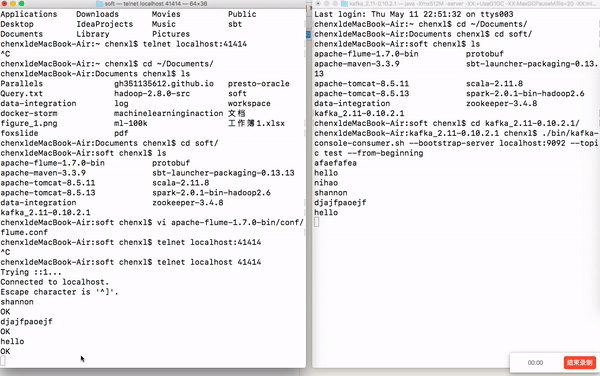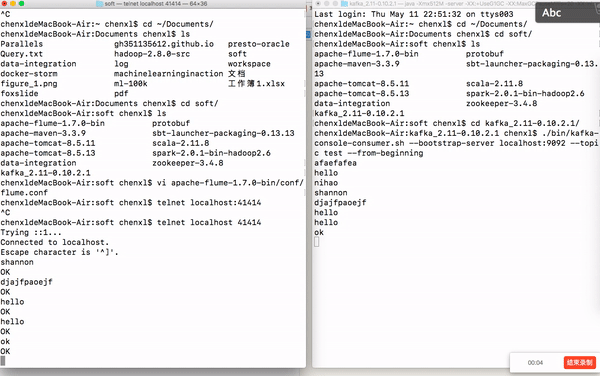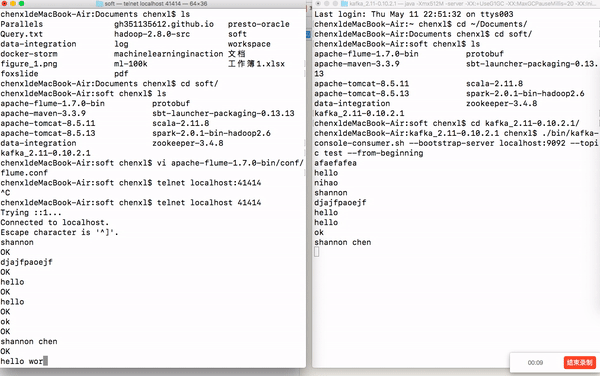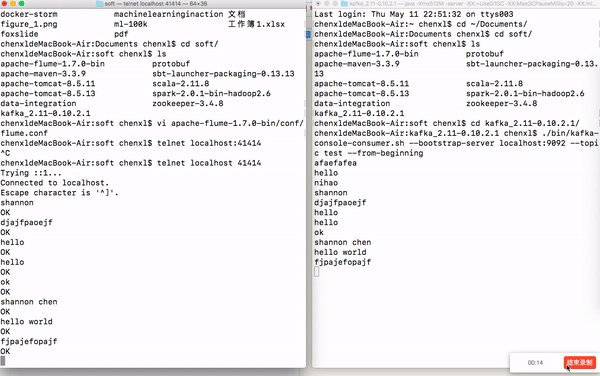
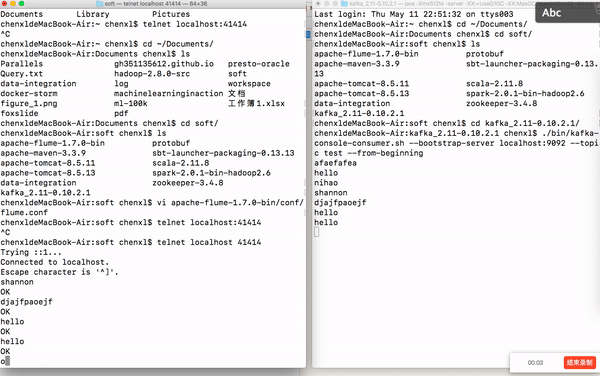
最新 Zookeeper + Flume + Kafka 简易整合教程的更多相关文章
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- 大数据处理框架之Strom:Flume+Kafka+Storm整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 apache-flume-1.6.0 ...
- Scala + Thrift+ Zookeeper+Flume+Kafka配置笔记
1. 开发环境 1.1. 软件包下载 1.1.1. JDK下载地址 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- Flume+Kafka+storm的连接整合
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- hadoop 之 kafka 安装与 flume -> kafka 整合
62-kafka 安装 : flume 整合 kafka 一.kafka 安装 1.下载 http://kafka.apache.org/downloads.html 2. 解压 tar -zxvf ...
- Flume+Kafka+Storm+Hbase+HDSF+Poi整合
Flume+Kafka+Storm+Hbase+HDSF+Poi整合 需求: 针对一个网站,我们需要根据用户的行为记录日志信息,分析对我们有用的数据. 举例:这个网站www.hongten.com(当 ...
- Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据 日志文件使用log4j生成,滚动生成! 当前正在写入的文件在满足一定的数 ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
随机推荐
- Itunes制作手机铃声,图文版
一.下载歌曲,选择歌曲用itunes打开,打开出现下面界面 二.设置歌曲 右键点击歌曲,找到显示简介,点击选项,截取音乐,出现下图: 截取你喜欢的部分,点击确定 点击确定后,选中该歌曲,找到左上方 文 ...
- Linux下配置tomcat+apr+native应对高并发
摘要:在慢速网络上Tomcat线程数开到300以上的水平,不配APR,基本上300个线程狠快就会用满,以后的请求就只好等待.但是配上APR之后,Tomcat将以JNI的形式调用Apache HTTP服 ...
- Python系列教程(一):简介
Python发展历史 起源 Python的作者,Guido von Rossum,荷兰人.1982年,Guido从阿姆斯特丹大学获得了数学和计算机硕士学位.然而,尽管他算得上是一位数学家,但他更加享受 ...
- 霍尔开关MH253ESO在减压神器指尖手指陀螺中的作用
手指陀螺首先在欧美国家流行起来,现如今又在国外掀起一帆狂潮,它是一款排遣无聊的小玩具,又被称为减压神器. 其工作原理:是由一个双向的对称体作为主体,在主体中间嵌入一个轴承的设计组合,整体构成一个可平面 ...
- 关于STM32单片机的IAP实现
基于STM32F103单片机的IAP实现(虽然该篇文章不会详细写出实现细节,但是会从一个全局的角度讲述,实际的实现细节只需根据datasheet即可完成). 一.基础概念 什么是IAP?IAP即在应用 ...
- Servlet 中为多项选择题判分---String类的indexOf()方法妙用
首先来看一下String类的indexOf()方法的用法: public class FirstDemo1 { /** *API中String的常用方法 */ // 查找指定字符串是否存在 publi ...
- 中文里带半角空格导致的Text换行问题[Unity]
0x01 问题 最近策划反映了个问题,游戏里的多行文本会出现提前换行的问题,如下图所示: 文本错误地提前换行,导致第一行文本后面有大块空白区域 通过观察可以发现,当字符串中带有半角空格,且半角空格后面 ...
- cookie的存取
cookie的存取 /写cookies 一路径为标准,Path – 路径 function setCookie(name, value, time) { var strsec = getsec(tim ...
- MongoDB数据库基础操作
前面的话 为了保存网站的用户数据和业务数据,通常需要一个数据库.MongoDB和Node.js特别般配,因为Mongodb是基于文档的非关系型数据库,文档是按BSON(JSON的轻量化二进制格式)存储 ...
- Java虚拟机:JVM内存分代策略
版权声明:本文为博主原创文章,转载请注明出处,欢迎交流学习! Java虚拟机根据对象存活的周期不同,把堆内存划分为几块,一般分为新生代.老年代和永久代(对HotSpot虚拟机而言),这就是JVM的内存 ...