大数据处理框架之Strom:Flume+Kafka+Storm整合
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
storm-0.9
apache-flume-1.6.0
一、Flume+Kafka+Storm架构设计
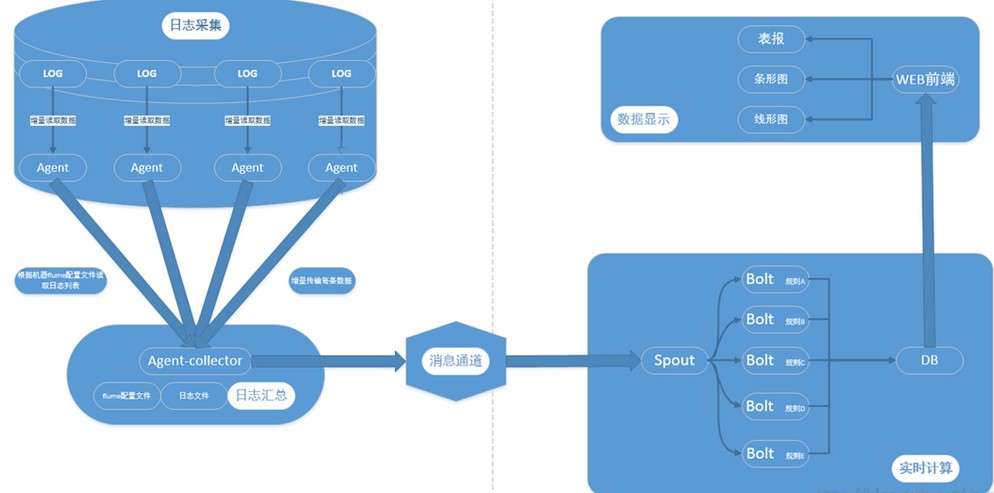
采集层:实现日志收集,使用负载均衡策略
消息队列:作用是解耦及不同速度系统缓冲
实时处理单元:用Storm来进行数据处理,最终数据流入DB中
展示单元:数据可视化,使用WEB框架展示
二、案例:
通过flume客户端向flume采集器发送日志,flume将日志发送到kafka集群主题testflume,storm集群消费kafka主题testflume日志,将经过过滤处理的消息发送给kafka集群主题LOGError,实现数据清理。

Client:
package com.sxt.flume; import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset; /**
* Flume官网案例
* http://flume.apache.org/FlumeDeveloperGuide.html
* @author root
*/
public class RpcClientDemo { public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("node1", 41414); // Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
for (int i = 10; i < 20; i++) {
String sampleData = "Hello Flume!ERROR" + i;
client.sendDataToFlume(sampleData);
System.out.println("发送数据:" + sampleData);
} client.cleanUp();
}
} class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port; public void init(String hostname, int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of the
// above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
} public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data, Charset.forName("UTF-8")); // Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname, port);
// Use the following method to create a thrift client (instead of
// the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname, port);
}
} public void cleanUp() {
// Close the RPC connection
client.close();
}
}
storm处理:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.logfileter; import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import storm.kafka.bolt.KafkaBolt;
import storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import storm.kafka.bolt.selector.DefaultTopicSelector; /**
* This topology demonstrates Storm's stream groupings and multilang
* capabilities.
*/
public class LogFilterTopology { public static class FilterBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String line = tuple.getString(0);
System.err.println("Accept: " + line);
// 包含ERROR的行留下
if (line.contains("ERROR")) {
System.err.println("Filter: " + line);
collector.emit(new Values(line));
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义message提供给后面FieldNameBasedTupleToKafkaMapper使用
declarer.declare(new Fields("message"));
}
} public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder(); // https://github.com/apache/storm/tree/master/external/storm-kafka
// config kafka spout,话题
String topic = "testflume";
ZkHosts zkHosts = new ZkHosts("node1:2181,node2:2181,node3:2181");
// /MyKafka,偏移量offset的根目录,记录队列取到了哪里
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/MyKafka", "MyTrack");// 对应一个应用
List<String> zkServers = new ArrayList<String>();
System.out.println(zkHosts.brokerZkStr);
for (String host : zkHosts.brokerZkStr.split(",")) {
zkServers.add(host.split(":")[0]);
} spoutConfig.zkServers = zkServers;
spoutConfig.zkPort = 2181;
// 是否从头开始消费
spoutConfig.forceFromStart = true;
spoutConfig.socketTimeoutMs = 60 * 1000;
// StringScheme将字节流转解码成某种编码的字符串
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); // set kafka spout
builder.setSpout("kafka_spout", kafkaSpout, 3); // set bolt
builder.setBolt("filter", new FilterBolt(), 8).shuffleGrouping("kafka_spout"); // 数据写出
// set kafka bolt
// withTopicSelector使用缺省的选择器指定写入的topic: LogError
// withTupleToKafkaMapper tuple==>kafka的key和message
KafkaBolt kafka_bolt = new KafkaBolt().withTopicSelector(new DefaultTopicSelector("LogError"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper()); builder.setBolt("kafka_bolt", kafka_bolt, 2).shuffleGrouping("filter"); Config conf = new Config();
// set producer properties.
Properties props = new Properties();
props.put("metadata.broker.list", "node1:9092,node2:9092,node3:9092");
/**
* Kafka生产者ACK机制 0 : 生产者不等待Kafka broker完成确认,继续发送下一条数据 1 :
* 生产者等待消息在leader接收成功确认之后,继续发送下一条数据 -1 :
* 生产者等待消息在follower副本接收到数据确认之后,继续发送下一条数据
*/
props.put("request.required.acks", "1");
props.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", props); conf.put(Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList(new String[] { "node1", "node2", "node3" })); // 本地方式运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology()); }
}
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.sxt.storm.logfileter; import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import storm.kafka.bolt.KafkaBolt;
import storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import storm.kafka.bolt.selector.DefaultTopicSelector; /**
* This topology demonstrates Storm's stream groupings and multilang
* capabilities.
*/
public class LogFilterTopology { public static class FilterBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String line = tuple.getString(0);
System.err.println("Accept: " + line);
// 包含ERROR的行留下
if (line.contains("ERROR")) {
System.err.println("Filter: " + line);
collector.emit(new Values(line));
}
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 定义message提供给后面FieldNameBasedTupleToKafkaMapper使用
declarer.declare(new Fields("message"));
}
} public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder(); // https://github.com/apache/storm/tree/master/external/storm-kafka
// config kafka spout,话题
String topic = "testflume";
ZkHosts zkHosts = new ZkHosts("node1:2181,node2:2181,node3:2181");
// /MyKafka,偏移量offset的根目录,记录队列取到了哪里
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/MyKafka", "MyTrack");// 对应一个应用
List<String> zkServers = new ArrayList<String>();
System.out.println(zkHosts.brokerZkStr);
for (String host : zkHosts.brokerZkStr.split(",")) {
zkServers.add(host.split(":")[0]);
} spoutConfig.zkServers = zkServers;
spoutConfig.zkPort = 2181;
// 是否从头开始消费
spoutConfig.forceFromStart = true;
spoutConfig.socketTimeoutMs = 60 * 1000;
// StringScheme将字节流转解码成某种编码的字符串
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); // set kafka spout
builder.setSpout("kafka_spout", kafkaSpout, 3); // set bolt
builder.setBolt("filter", new FilterBolt(), 8).shuffleGrouping("kafka_spout"); // 数据写出
// set kafka bolt
// withTopicSelector使用缺省的选择器指定写入的topic: LogError
// withTupleToKafkaMapper tuple==>kafka的key和message
KafkaBolt kafka_bolt = new KafkaBolt().withTopicSelector(new DefaultTopicSelector("LogError"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper()); builder.setBolt("kafka_bolt", kafka_bolt, 2).shuffleGrouping("filter"); Config conf = new Config();
// set producer properties.
Properties props = new Properties();
props.put("metadata.broker.list", "node1:9092,node2:9092,node3:9092");
/**
* Kafka生产者ACK机制 0 : 生产者不等待Kafka broker完成确认,继续发送下一条数据 1 :
* 生产者等待消息在leader接收成功确认之后,继续发送下一条数据 -1 :
* 生产者等待消息在follower副本接收到数据确认之后,继续发送下一条数据
*/
props.put("request.required.acks", "1");
props.put("serializer.class", "kafka.serializer.StringEncoder");
conf.put("kafka.broker.properties", props); conf.put(Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList(new String[] { "node1", "node2", "node3" })); // 本地方式运行
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("mytopology", conf, builder.createTopology()); }
}
参考:
美团日志收集系统
Apache Flume
Apache Flume负载均衡
大数据处理框架之Strom:Flume+Kafka+Storm整合的更多相关文章
- 大数据处理框架之Strom:kafka storm 整合
storm 使用kafka做数据源,还可以使用文件.redis.jdbc.hive.HDFS.hbase.netty做数据源. 新建一个maven 工程: pom.xml <project xm ...
- 大数据处理框架之Strom:redis storm 整合
storm 引入redis ,主要是使用redis缓存库暂存storm的计算结果,然后redis供其他应用调用取出数据. 新建maven工程 pom.xml <project xmlns=&qu ...
- 大数据处理框架之Strom:认识storm
Storm是分布式实时计算系统,用于数据的实时分析.持续计算,分布式RPC等. (备注:5种常见的大数据处理框架:· 仅批处理框架:Apache Hadoop:· 仅流处理框架:Apache Stor ...
- 大数据处理框架之Strom: Storm----helloword
大数据处理框架之Strom: Storm----helloword Storm按照设计好的拓扑流程运转,所以写代码之前要先设计好拓扑图.这里写一个简单的拓扑: 第一步:创建一个拓扑类含有main方法的 ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- 大数据处理框架之Strom: Storm拓扑的并行机制和通信机制
一.并行机制 Storm的并行度 ,通过提高并行度可以提高storm程序的计算能力. 1.组件关系:Supervisor node物理节点,可以运行1到多个worker,不能超过supervisor. ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- 大数据处理框架之Strom:DRPC
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 storm-0.9 一.DRPC DRPC:Distri ...
- 大数据处理框架之Strom:容错机制
1.集群节点宕机Nimbus服务器 单点故障,大部分时间是闲置的,在supervisor挂掉时会影响,所以宕机影响不大,重启即可非Nimbus服务器 故障时,该节点上所有Task任务都会超时,Nimb ...
随机推荐
- python:pip命令使用
pip命令安装库 pip install 库名 使用pip命令更新库 pip install --upgrade 库名 比如更新scikit-learn包 pip install --upgrade ...
- 决策树 Decision Tree
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布.树的最顶层是根结点.  决策树的构建 想要构建一个决策树,那么咱们 ...
- 安装wamp环境 最新完整版
Apache 下载地址:https://www.apachehaus.com/cgi-bin/download.plx 下载后 解压目录 放到C:/Program Files下面目录重命名为Apach ...
- Java开发知识之Java中的泛型
Java开发知识之Java中的泛型 一丶简介什么是泛型. 泛型就是指泛指任何数据类型. 就是把数据类型用泛型替代了. 这样是可以的. 二丶Java中的泛型 Java中,所有类的父类都是Object类. ...
- Lily_music 网页音乐播放器 -可搜索(附歌词联动播放效果解说)
博客地址:https://ainyi.com/59 写在前面 这是我今年(2018)年初的小项目,当时也是手贱,不想用别的播放器,想着做一个自己的网页播放器,有个歌曲列表.可关键词搜索.歌词滚动播放的 ...
- 菜鸟学ASP.NET MVC4入门笔记
ASP.NET MVC 是微软官方提供的以MVC模式为基础的ASP.NET Web应用程序(Web Application)框架,它由Castle的MonoRail而来. MVC 编程模式 MVC 是 ...
- mybatis报错:Caused by: java.lang.IllegalArgumentException: Caches collection already contains value for com.crm.dao.PaperUserMapper
一.问题 eclipse启动时报下面的错误: Caused by: java.lang.IllegalArgumentException: Caches collection already cont ...
- JQuery autocomplete获得焦点触发弹出下拉框
需求:autocomplete控件,当点击获得焦点的时候也要弹出下拉列表(autocomplete默认是输入之后才会跟随出下拉列表),下面直接贴代码. js代码: $("#customerN ...
- 【设计原则和编程技巧】单一职责原则 (Single Responsibility Principle, SRP)
单一职责原则 (Single Responsibility Principle, SRP) 单一职责原则在设计模式中常被定义为“一个类应该只有一个发生变化的原因”,若我们有两个动机去改写一个方法,那这 ...
- Android 解析标准的点击第三方文件管理器中的视频的intent
解析标准的第三方视频intent private List<String> mCurPlayList = new ArrayList<String>(); private in ...