机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明
1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题
参数说明:n_topics 表示分为多少个主题, max_iters表示最大的迭代次数, random_state 表示随机种子
2. LDA.components_ 打印输入特征的权重参数,
LDA主题模型:可以用于做分类,好比如果是两个主题的话,那就相当于是分成了两类,同时我们也可以找出根据主题词的权重值,来找出一些主题的关键词
使用sklearn导入库
from sklearn.decomposition import LatentDirichletAllocation, 使用方法还是fit_transform
LDA.components_ 打印出各个参数的权重值,这个权重值是根据数据特征的标签来进行排列的
代码:
第一步:Dataframe化数据
第二步:进行分词和停用词的去除,使用' '.join 为了词袋模型做准备
第三步:使用np.vectorizer对函数进行向量化处理,调用定义的函数进行分词和停用词的去除
第四步:使用Tf-idf 函数构建词袋模型
第五步:使用LatentDirichletAllocation构建LDA模型,并进行0,1标签的数字映射
第六步:使用LDA.components_打印输入特征标签的权重得分,去除得分小于0.6的得分,我们可以看出哪些词是主要的关键字
import pandas as pd
import numpy as np
import re
import nltk #pip install nltk corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
] labels = ['weather', 'weather', 'animals', 'animals', 'weather', 'animals'] # 第一步:构建DataFrame格式数据
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'categoray': labels}) # 第二步:构建函数进行分词和停用词的去除
# 载入英文的停用词表
stopwords = nltk.corpus.stopwords.words('english')
# 建立词分割模型
cut_model = nltk.WordPunctTokenizer()
# 定义分词和停用词去除的函数
def Normalize_corpus(doc):
# 去除字符串中结尾的标点符号
doc = re.sub(r'[^a-zA-Z0-9\s]', '', string=doc)
# 是字符串变小写格式
doc = doc.lower()
# 去除字符串两边的空格
doc = doc.strip()
# 进行分词操作
tokens = cut_model.tokenize(doc)
# 使用停止用词表去除停用词
doc = [token for token in tokens if token not in stopwords]
# 将去除停用词后的字符串使用' '连接,为了接下来的词袋模型做准备
doc = ' '.join(doc) return doc # 第三步:向量化函数和调用函数
# 向量化函数,当输入一个列表时,列表里的数将被一个一个输入,最后返回也是一个个列表的输出
Normalize_corpus = np.vectorize(Normalize_corpus)
# 调用函数进行分词和去除停用词
corpus_norm = Normalize_corpus(corpus) # 第四步:使用TfidVectorizer进行TF-idf词袋模型的构建
from sklearn.feature_extraction.text import TfidfVectorizer Tf = TfidfVectorizer(use_idf=True)
Tf.fit(corpus_norm)
vocs = Tf.get_feature_names()
corpus_array = Tf.transform(corpus_norm).toarray()
corpus_norm_df = pd.DataFrame(corpus_array, columns=vocs)
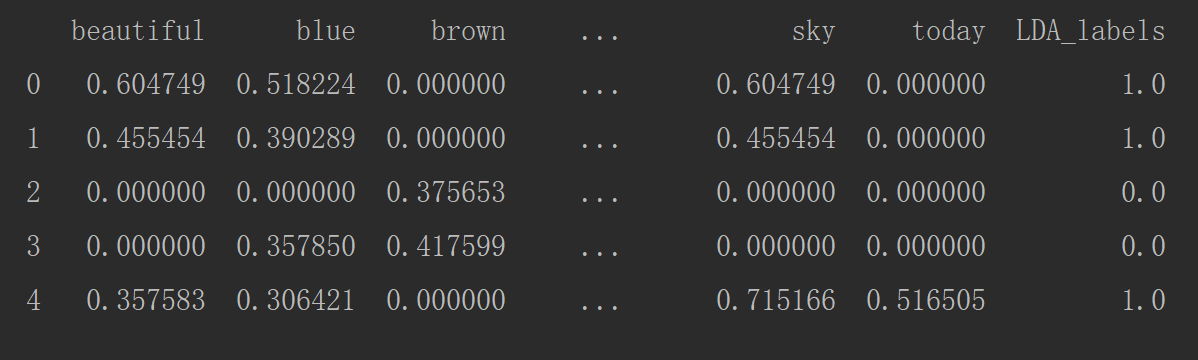
print(corpus_norm_df.head()) # 第五步:构建LDA主题模型
from sklearn.decomposition import LatentDirichletAllocation LDA = LatentDirichletAllocation(n_topics=2, max_iter=100, random_state=42)
LDA_corpus = np.array(LDA.fit_transform(corpus_array))
LDA_corpus_one = np.zeros([LDA_corpus.shape[0]])
LDA_corpus_one[LDA_corpus[:, 0] < LDA_corpus[:, 1]] = 1
corpus_norm_df['LDA_labels'] = LDA_corpus_one
print(corpus_norm_df.head())
# 第六步:打印每个单词的主题的权重值
tt_matrix = LDA.components_
for tt_m in tt_matrix:
tt_dict = [(name, tt) for name, tt in zip(vocs, tt_m)]
tt_dict = sorted(tt_dict, key=lambda x: x[1], reverse=True)
# 打印权重值大于0.6的主题词
tt_dict = [tt_threshold for tt_threshold in tt_dict if tt_threshold[1] > 0.6]
print(tt_dict)

大于0.6权重得分的部分特征
机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)的更多相关文章
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- 机器学习入门-文本数据-构造Ngram词袋模型 1.CountVectorizer(ngram_range) 构建Ngram词袋模型
函数说明: 1 CountVectorizer(ngram_range=(2, 2)) 进行字符串的前后组合,构造出新的词袋标签 参数说明:ngram_range=(2, 2) 表示选用2个词进行前后 ...
- 机器学习入门-数值特征-数字映射和one-hot编码 1.LabelEncoder(进行数据自编码) 2.map(进行字典的数字编码映射) 3.OnehotEncoder(进行one-hot编码) 4.pd.get_dummies(直接对特征进行one-hot编码)
1.LabelEncoder() # 用于构建数字编码 2 .map(dict_map) 根据dict_map字典进行数字编码的映射 3.OnehotEncoder() # 进行one-hot编码 ...
- 机器学习入门09 - 特征组合 (Feature Crosses)
原文链接:https://developers.google.com/machine-learning/crash-course/feature-crosses/ 特征组合是指两个或多个特征相乘形成的 ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- 机器学习入门-文本数据-构造Tf-idf词袋模型(词频和逆文档频率) 1.TfidfVectorizer(构造tf-idf词袋模型)
TF-idf模型:TF表示的是词频:即这个词在一篇文档中出现的频率 idf表示的是逆文档频率, 即log(文档的个数/1+出现该词的文档个数) 可以看出出现该词的文档个数越小,表示这个词越稀有,在这 ...
- 机器学习入门-数值特征-对数据进行log变化
对于一些标签和特征来说,分布不一定符合正态分布,而在实际的运算过程中则需要数据能够符合正态分布 因此我们需要对特征进行log变化,使得数据在一定程度上可以符合正态分布 进行log变化,就是对数据使用n ...
- 机器学习入门-数值特征-数据四分位特征 1.quantile(用于求给定分数位的数值) 2.plt.axvline(用于画出竖线) 3.pd.pcut(对特征进行分位数切分,生成新的特征)
函数说明: 1. .quantile(cut_list) 对DataFrame类型直接使用,用于求出给定列表中分数的数值,这里用来求出4分位出的数值 2. plt.axvline() # 用于画 ...
- 机器学习入门-数值特征-连续数据离散化(进行分段标记处理) 1.hist(Dataframe格式直接画直方图)
函数说明: 1. .hist 对于Dataframe格式的数据,我们可以使用.hist直接画出直方图 对于一些像年龄和工资一样的连续数据,我们可以对其进行分段标记处理,使得这些连续的数据变成离散化 就 ...
随机推荐
- Javascript中的对象(八)
一.如何编写可以计算的对象的属性名 我们都知道对象的属性访问分两种,键访问(["属性名"])和属性访问(.属性名,遵循标识符的命名规范) 对于动态属性名可以这样 var prefi ...
- Foxmail Gmail Outlook
三个邮件客户端都比较好,但是作为用户精力是非常有限地,必须优中选优. 我选outlook,非常值得拥有. 理由如下: (1)和office完美契合 (2)和生产环境完美契合 (3)免费 (4)良好地任 ...
- PAT 乙级 1008 数组元素循环右移问题 (20) C++版
1008. 数组元素循环右移问题 (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 一个数组A中存有N(N>0)个整数,在不允 ...
- selectedIndex 属性
selectedIndex 属性可设置或返回下拉列表中被选选项的索引号. 注释:若允许多重选择,则仅会返回第一个被选选项的索引号. 语法 selectObject.selectedIndex=numb ...
- [转][html]设置IIS 默认页
<?xml version="1.0" encoding="UTF-8"?> <configuration> <system.we ...
- 廖雪峰Java6IO编程-2input和output-1inputStream
1.InputStream 1.1InputStream是所有输入流的超类: int read() * 读取下一个字节,并返回字节(0-255) * 如果已读到末尾,返回-1 * read()方法是阻 ...
- 通过编写PHP代码并运用“正则表达式”来实现对试题文档进行去重复、排序
通过编写PHP代码并运用“正则表达式”来实现对试题文档进行去重复.排序 <?php $subject = file_get_contents('test.txt'); $pattern = '/ ...
- MySQL学习----索引的使用
一.什么是索引?为什么要建立索引? 索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的 ...
- win10使用4G 模块RNDIS模式上网
Windons使用RNDIS模式上网步骤 Chapter 1 模块端配置 1模块设置为RNDIS模式 1. 以EC20CEFAG模块为例 2. 命令如下: 1) ...
- TensorFlow安装教程(ubuntu 18.04)
此教程的硬件条件: 1.Nvidia GPU Geforce390及以上 2.Ubuntu 18.04操作系统 3.Anaconda工具包 如果python版本为3.7及以上,使用如下命令降级到3.6 ...