【C++ Primer | 10】泛型算法
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
#include<fstream>
using namespace std; void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto unique_end = unique(words.begin(), words.end());
words.erase(unique_end, words.end());
} void display(vector<string> &words)
{
for (auto c : words)
cout << c << " ";
cout << endl;
} int main()
{
ifstream in("test.txt");
if (!in)
{
cout << "打开文件失败" << endl;
exit();
} vector<string> words;
string str;
while (in >> str)
words.push_back(str);
elimDups(words);
display(words);
return ;
}

输出结果:

定制操作
示例代码:
#include<iostream>
#include<algorithm>
#include<vector>
#include<string>
#include<fstream>
using namespace std; void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto unique_end = unique(words.begin(), words.end());
words.erase(unique_end, words.end());
} void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words); //将单词按字典排序,删除重复单词
stable_sort(words.begin(), words.end(), [](const string &a, const string &b) { return a.size() < b.size(); });
auto wc = find_if(words.begin(), words.end(), [sz](const string &a) { return a.size() >= sz; });
auto count = words.end() - wc;
for_each(wc, words.end(), [](const string &s) { cout << s << " "; });
cout << endl;
} int main()
{
ifstream in("test.txt");
if (!in)
{
cout << "打开文件失败" << endl;
exit();
} vector<string> words;
string str;
while (in >> str)
words.push_back(str);
auto sz = ;
biggies(words, sz);
return ;
}
输出结果:

再探迭代器
3. 反向迭代器
#include<iostream>
#include<vector>
#include<iterator>
using namespace std; int main()
{
vector<int> vec = { , , , , , , , , , };
for (auto r_iter = vec.crbegin(); r_iter != vec.crend(); ++r_iter)
cout << *r_iter << " ";
cout << endl;
return ;
}
输出结果:

#include <iostream>
#include <deque>
#include <algorithm>
#include <iterator>
using namespace std; void print(int elem)
{
cout << elem << ' ';
} int main()
{
deque<int> coll;
for (int i = ; i <= ; ++i)
coll.push_back(i); deque<int>::iterator pos1;
pos1 = find(coll.begin(), coll.end(), ); deque<int>::iterator pos2;
pos2 = find(coll.begin(), coll.end(), );
for_each(pos1, pos2, print);
cout << endl; deque<int>::reverse_iterator rpos1(pos1);
deque<int>::reverse_iterator rpos2(pos2);
for_each(rpos2, rpos1, print);
cout << endl;
return ;
}
输出结果:

【分析】
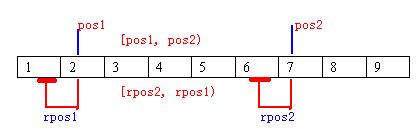
代码首先在一个deque中插入1到9,然后查找元素值为2和7的位置,分别赋值给迭代器pos1和pos2,然后输出,由于STL中的操作总是左开右闭的区间,即[2,7),所以输出2 3 4 5 6,7不会输出。
接下来将迭代器转换成逆向迭代器,再次输出,对于反向迭代器,由于是反向,所以按逻辑来说它是左开右闭的(这里我尝试了rpos2为iterator.end(),rpos1为iterator.begin(),此时输出全部),即(7,2](事实上还是左闭右开,只不过此时的左和iterator顺序一样)。所以输出6 5 4 3 2,下面的图片解释的很清楚。
【C++ Primer | 10】泛型算法的更多相关文章
- c++ primer 11 泛型算法
使用泛型算法必须包含头文件#inlucde <algorithm> 标准库还定义一组泛化的算术算法,其命名习惯与泛型算法相同,包含头文件#include <numeric> f ...
- C++ Primer 5th 第10章 泛型算法
练习10.1:头文件algorithm中定义了一个名为count的函数,它类似find,接受一对迭代器和一个值作为参数.count返回给定值在序列中出现的次数.编写程序,读取int序列存入vector ...
- [C++ Primer] : 第10章: 泛型算法
概述 泛型算法: 称它们为"算法", 是因为它们实现了一些经典算法的公共接口, 如搜索和排序; 称它们是"泛型的", 是因为它们可以用于不同类型的元素和多种容器 ...
- C++ Primer : 第十章 : 泛型算法 之 只读、写和排序算法
大多数算法都定义在<algorithm>头文件里,而标准库还在头文件<numeric>里定义了一组数值泛型算法,比如accumulate. ● find算法,算法接受一对迭代 ...
- 【足迹C++primer】30、概要(泛型算法)
概要(泛型算法) 大多数算法的头文件中定义algorithm在. 标准库也是第一个文件numeric它定义了一套通用算法. #include<iostream> #include<n ...
- C++ Primer笔记6_STL之泛型算法
1.泛型算法: 大多数算法定义在头文件algorithm中.标准库还在头文件numeric中定义了一组数值泛型算法 仅仅读算法: 举例: find函数用于找出容器中一个特定的值,有三个參数 int v ...
- 【c++ Prime 学习笔记】第10章 泛型算法
标准库未给容器添加大量功能,而是提供一组独立于容器的泛型算法 算法:它们实现了一些经典算法的公共接口 泛型:它们可用于不同类型的容器和不同类型的元素 利用这些算法可实现容器基本操作很难做到的事,例如查 ...
- C++ Primer 读书笔记:第11章 泛型算法
第11章 泛型算法 1.概述 泛型算法依赖于迭代器,而不是依赖容器,需要指定作用的区间,即[开始,结束),表示的区间,如上所示 此外还需要元素是可比的,如果元素本身是不可比的,那么可以自己定义比较函数 ...
- C++ Primer 学习笔记_45_STL实践与分析(19)--泛型算法的结构
STL实践与分析 --泛型算法的结构 引言: 正如全部的容器都建立在一致的设计模式上一样,算法也具有共同的设计基础. 算法最主要的性质是须要使用的迭代器种类.全部算法都指定了它的每一个迭代器形參可使用 ...
- C++ 泛型算法
<C++ Primer 4th>读书笔记 标准容器(the standard container)定义了很少的操作.标准库并没有为每种容器类型都定义实现这些操作的成员函数,而是定义了一组泛 ...
随机推荐
- 应急响应-GHO提取注册表快照
前言 备份文件.gho中找到机器的注册表 文件夹位置 在 C:\WINDOWS\SYSTEM32\CONFIG 下就是系统的注册表,一般情况下,这里面会有以下几个文件: default 默认注册表文件 ...
- windows下安装MySql + navicat(图形化界面)
MySQL安装过程参考:https://www.cnblogs.com/ayyl/p/5978418.html navicat图形化界面安装过程参考:https://www.cnblogs.com/l ...
- nginx的linux服务器内核参数调整【转】
概述 由于默认的linux内核参数考虑的是最通用场景,这明显不符合用于支持高并发访问的Web服务器的定义,所以需要修改Linux内核参数,让Nginx可以拥有更高的性能: 在优化内核时,可以做的事情很 ...
- HTTP协议06-报文首部
HTTP报文格式 HTTP协议的请求和响应报文中必定包含HTTP首部.首部内容为客户端和服务器分别处理请求和响应提供所需要的信息. 1)HTTP请求报文 在请求中,HTTP报文由方法.URI.HT ...
- PHP操作redis详细讲解(转)
PHP中redis的使用 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合)和z ...
- 【转】关于Log4j
转自:http://www.open-open.com/lib/view/open1337754346355.html 原帖:http://blog.csdn.net/neareast/article ...
- Linux Free命令每个数字的含义 和 cache 、buffer的区别
Linux Free命令每个数字的含义 和 cache .buffer的区别 我们按照图中来一细细研读(数字编号和图对应)1,total:物理内存实际总量2,used:这块千万注意,这里可不是实际已经 ...
- UML建模图
UML 2.0规范 迅速成为建立软件系统可视化.规范.文档的标准.统一建模语言(UML) 也被用于非软件系统的建模,并在很多领域,诸如金融,军事,工程方面应用广泛. UML 2 定义了13种基本的图, ...
- Java实现三大简单排序算法
一.选择排序 public static void main(String[] args) { int[] nums = {1,2,8,4,6,7,3,6,4,9}; for (int i=0; i& ...
- 幂的运算:X的n次幂
计算X的n次幂,有多种算法 例子:计算2的62次方. method 1 :time = 1527 纳秒. 常规思路,进行61次的乘法! private static long mi(long X, l ...