HDFS 读写数据流程
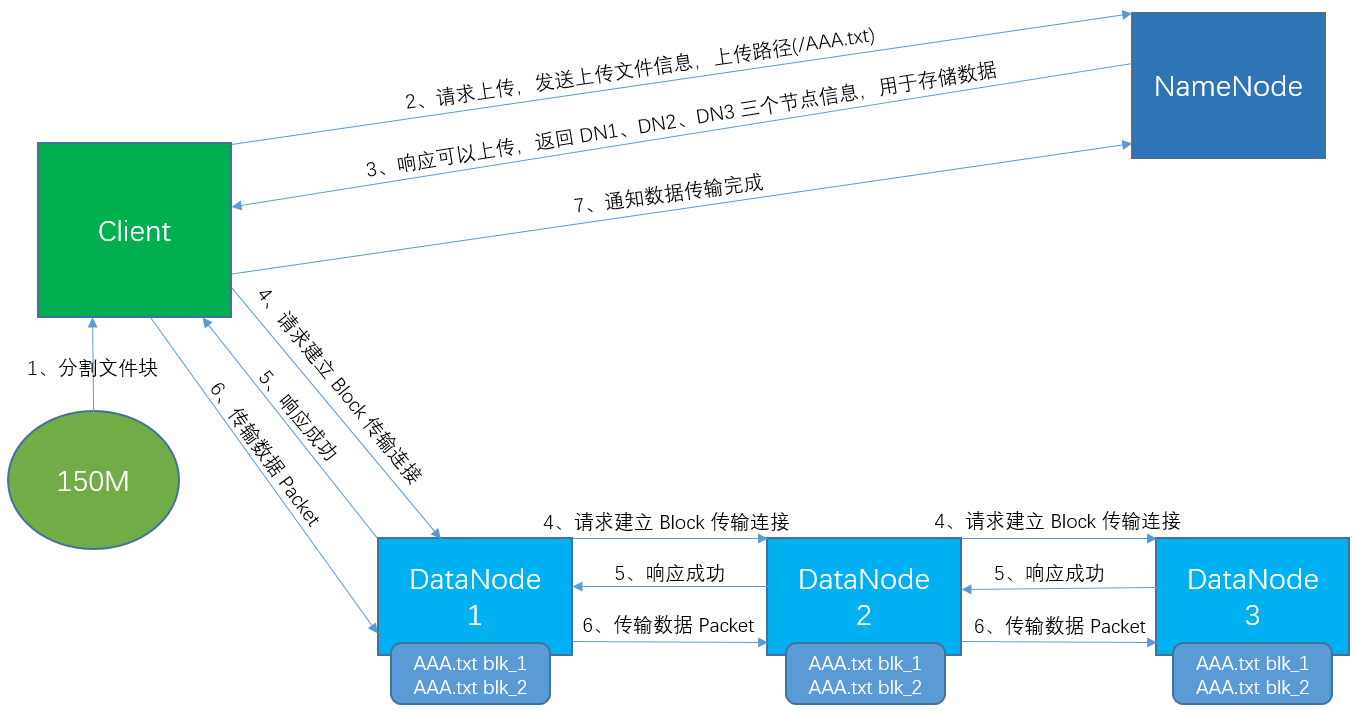
一、上传数据
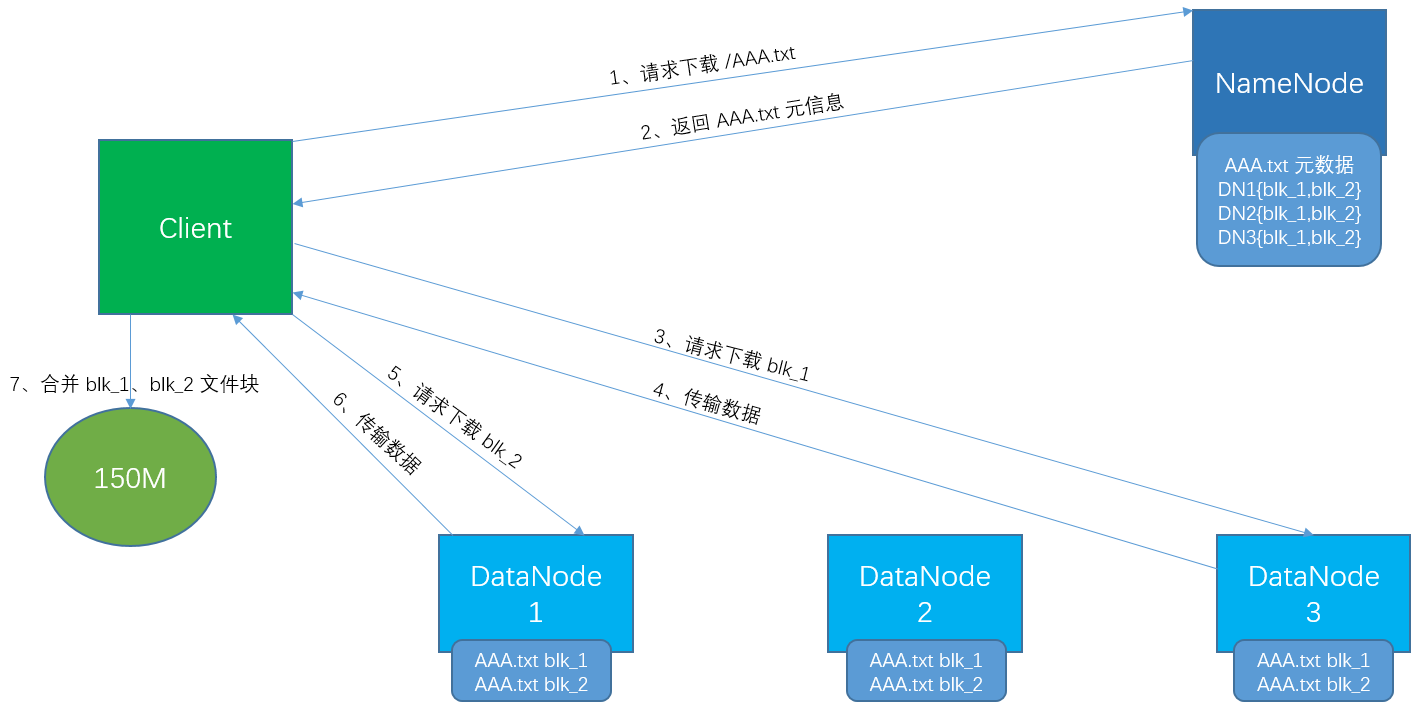
二、下载数据
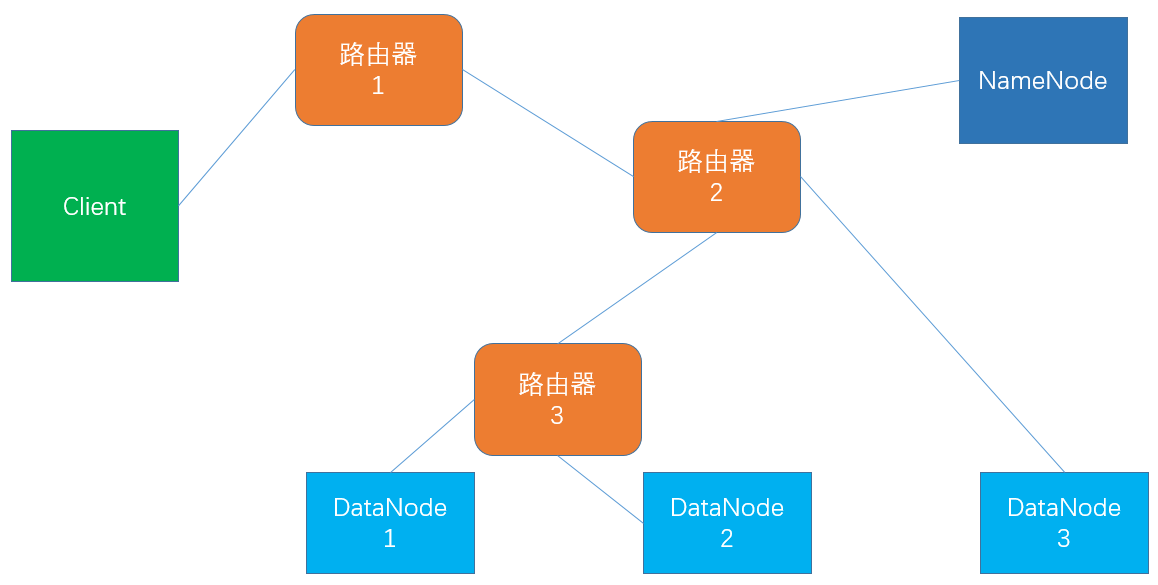
三、读写时的节点位置选择
1.网络节点距离(机架感知)
下图中:
client 到 DN1 的距离为 4
client 到 NN 的距离为 3
DN1 到 DN2 的距离为 2
2.Block 的副本放置策略
NameNode 通过 Hadoop Rack Awareness 确定每个 DataNode 所属的机架 ID
简单但非最优的策略
将副本放在单独的机架上 这可以防止在整个机架出现故障时丢失数据,并允许在读取数据时使用来自多个机架的带宽。
此策略在群集中均匀分布副本,平衡组件故障的负载。
但是此策略会增加写入消耗,因为写入时会将块传输到多个机架。
常见情况策略(HDFS 采取的策略)
当复制因子为 3 时,HDFS 的放置策略是:
若客户端位于 datanode 上,则将一个副本放在本地计算机上,否则放在随机 datanode 上
在另一个(远程)机架上的节点上放置另一个副本,最后一个在同一个远程机架中的另一个节点上。 机架故障的可能性远小于节点故障的可能性。
此策略可以减少机架间写入流量,从而提高写入性能,而不会影响数据可靠性和可用性(读取性能)。
这样减少了读取数据时使用的聚合网络带宽,因为块只放在两个唯一的机架,而不是三个。
如果复制因子大于 3,则随机确定第 4 个及后续副本的放置,同时保持每个机架的副本数量低于上限(基本上是(副本 - 1)/机架+ 2)。
由于 NameNode 不允许 DataNode 具有同一块的多个副本,因此创建的最大副本数是此时DataNode的总数。
原文(Replica Placement: The First Baby Steps 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
3.下载时副本的选择
为了最大限度地减少全局带宽消耗和读取延迟,HDFS 会选择最接客户端的节点中的副本来响应读取请求。 如果客户端与 DataNode 节点在同一机架上,且存在所需的副本,则该副本会首读用来响应取请求。 如果 HDFS 群集跨越多个数据中心,则驻留在本地数据中心的副本优先于任何远程副本。
原文(Replica Selection 章节): http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS 读写数据流程的更多相关文章
- 大数据:Hadoop(HDFS 读写数据流程及优缺点)
一.HDFS 写数据流程 写的过程: CLIENT(客户端):用来发起读写请求,并拆分文件成多个 Block: NAMENODE:全局的协调和把控所有的请求,提供 Block 存放在 DataNode ...
- HDFS读写数据流程
HDFS的组成 1.NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(创建时间,文件权限,文件大小) 以及每个文件的块列表和块所在的DataNode等.类似于一本书的目录功能. 2 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- Hadoop(8)-HDFS的读写数据流程以及机架感知
1. HDFS的写数据流程 1.客户端通过fs模块向NameNode申请文件上传,NameNode检查请求是否合法,如用户权限,目标文件是否已存在,父目录是否存在等等 2.NameNode返回是否可以 ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hdfs读写数据出错
1.Hdfs读数据出错:若在读数据的过程中,客户端和DataNode的通信出现错误,则会尝试连接下一个 包含次文件块的DataNode.同时记录失败的DataNode,此后不再被连接. 2.Hdfs在 ...
- HDFS读写文件流程
读取: 写入:https://www.imooc.com/article/70527
- HDFS写数据和读数据流程
HDFS数据存储 HDFS client上传数据到HDFS时,首先,在本地缓存数据,当数据达到一个block大小时.请求NameNode分配一个block. NameNode会把block所在的Dat ...
随机推荐
- LEGB规则
链接:https://www.cnblogs.com/GuoYaxiang/p/6405814.html 命名空间 大约来说,命名空间就是一个容器,其中包含的是映射到不同对象的名称.你可能已经听说过了 ...
- 【XSY2772】数列 特征多项式 数学
题目描述 给你一个数列: \[ f_n=\begin{cases} a^n&1\leq n\leq k\\ \sum_{i=1}^k(a-1)f_{n-i}&n>k \end{c ...
- Android 简单天气预报
IDE: Android studio3.1.2 界面: activity_main.xml
- Hdoj 1050.Moving Tables 题解
Problem Description The famous ACM (Advanced Computer Maker) Company has rented a floor of a buildin ...
- Python的快排应有的样子
快排算法 简单来说就是定一个位置然后,然后把比它小的数放左边,比他大的数放右边,这显然是一个递归的定义,根据这个思路很容易可以写出快排的代码 快排是我学ACM路上第一个让我记住的代码,印象很深 ...
- 【BZOJ4890】[TJOI2017]城市(动态规划)
[BZOJ4890][TJOI2017]城市(动态规划) 题面 BZOJ 洛谷 题解 数据范围都这样了,显然可以暴力枚举断开哪条边. 然后求出两侧直径,暴力在直径上面找到一个点,使得其距离直径两端点的 ...
- 【BZOJ5212】[ZJOI2018]历史(Link-Cut Tree)
[BZOJ5212][ZJOI2018]历史(Link-Cut Tree) 题面 洛谷 BZOJ 题解 显然实际上就是给定了一棵树和每个点被\(access\)的次数,求解轻重链切换的最大次数. 先考 ...
- POJ2411 铺地砖 Mondriaan's Dream
Mondriaan's Dream Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 15962 Accepted: 923 ...
- 让Mac 可以使用mysql -u用户直接连接数据库
在执行完安装版本的mysql数据库后,会发现执行mysql还是会出现 command not found的错误:解决方案 方案1.设置软连接到/usr/local/bin下在命令行下输入如下 ln - ...
- servlet 上下文
一.应用需求: 如何统计网站在线人数? 使用ServletContext. 二.ServletContext详解: 1.是不同于session和cookie,是可以让所有客户端共同访问的内容,是在服务 ...