python应用之爬虫实战2 请求库与解析库
知识内容:
1.requests库
2.selenium库
3.BeautifulSoup4库
4.re正则解析库
5.lxml库
参考:
http://www.cnblogs.com/wupeiqi/articles/5354900.html
http://www.cnblogs.com/linhaifeng/articles/7785043.html
一、requests库
1.安装及简单使用
(1)安装
pip3 install requests
(2)简单使用
import requests
r = requests.get("http://www.baidu.com") # 发起get请求
print(r.status_code) # 打印状态码
r.encoding = "utf-8" # 指定编码
print(r.text) # 输出文本内容
2.基于GET请求
requests.get(url, params=None, **kwargs)
(1)基本请求
import requests url = "https://www.autohome.com.cn/news/" response = requests.get(url)
response.encoding = response.apparent_encoding # 指定编码
print(response.text)
(2)带参数的GET请求
加headers
# 在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容
import requests headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
} response = requests.get('https://www.baidu.com/s?wd=python&pn=1', headers=headers)
print(response.text)
对url进行编码
# 在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容
import requests headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
} # 如果查询关键词是中文或者有其他特殊符号,则必须进行url编码
from urllib.parse import urlencode wd = '六六六'
encode_res = urlencode({'k': wd}, encoding='utf-8')
keyword = encode_res.split('=')[1]
print(keyword)
url = 'https://www.baidu.com/s?wd=%s&pn=1' % keyword response = requests.get(url, headers=headers)
res = response.text
print(res)
params参数
Requests模块允许使用params关键字传递参数,以一个字典来传递参数,例子如下:

import requests
data = {
"name":"zhaofan",
"age":22
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
print(response.text)
GET请求中headers常用元素如下:
#通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下
Host
Referer #大型网站通常都会根据该参数判断请求的来源
User-Agent #客户端
Cookie #Cookie信息虽然包含在请求头里,但requests模块有单独的参数处理他,headers内就不要放它了
(3)cookies
# 登录github,然后从浏览器中获取cookies,以后就可以直接拿着cookie登录了,无需输入用户名密码
import requests
Cookies = {
'user_session': 'ac0TP4aV3yyjfejv9dJOv1Erb_IJiSHTd_ac3s4N_sEZ71gK'
}
# github对请求头没有什么限制,我们无需定制user-agent,对于其他网站可能还需要定制
response = requests.get('https://github.com/settings/emails', cookies=Cookies)
print('1572834916@qq.com' in response.text) # True
3.基于POST请求
(1)requests模块的post方法和get方法的区别
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
import requests
data = {
"name":"wyb",
"age": 21,
}
response = requests.post("http://httpbin.org/post", data=data)
print(response.text)
(2)发送post请求,模拟浏览器的登录行为
实例 模拟登录github
'''
一 目标站点分析
浏览器输入https://github.com/login
然后输入错误的账号密码,抓包
发现: 登录行为是post并提交到:https://github.com/session且请求头包含cookie
而且请求体包含:
commit:Sign in
utf8:✓
authenticity_token: taqxIh0Qs8Qm54Ov2WoR+RHq6O/1a8L/F960j/arN6xDEC9QArBTp6D4VFROYwLveIk+o5Ca5aBhWMEmhNmEnA==
login: 1572834916@qq.com
password:123 二 流程分析
先GET:https://github.com/login拿到初始cookie与authenticity_token
返回POST:https://github.com/session, 带上初始cookie,带上请求体(authenticity_token,用户名,密码等)
最后拿到登录cookie ps:如果密码是密文形式,则可以先输错账号,输对密码,然后到浏览器中拿到加密后的密码
但是github的密码是明文,故不需使用上述的步骤
''' import requests
import re # 第一次请求
r1 = requests.get('https://github.com/login')
r1_cookie = r1.cookies.get_dict() # 拿到初始cookie(未被授权)
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"', r1.text)[0] # 从页面中拿到CSRF TOKEN # 第二次请求:带着初始cookie和TOKEN发送POST请求给登录页面,带上账号密码
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': '1572834916@qq.com',
'password': 'xxx'
}
r2 = requests.post('https://github.com/session',
data=data,
cookies=r1_cookie
) login_cookie = r2.cookies.get_dict() # 第三次请求:以后的登录,拿着login_cookie就可以,比如访问一些个人配置
r3 = requests.get('https://github.com/settings/emails',
cookies=login_cookie) print('1572834916@qq.com' in r3.text) # True
当然上面也可以用requests.session()来自动保存cookie信息,示例如下:
import requests
import re session = requests.session()
# 第一次请求
r1 = session.get('https://github.com/login')
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"', r1.text)[0] # 从页面中拿到CSRF TOKEN # 第二次请求:带着初始cookie和TOKEN发送POST请求给登录页面,带上账号密码
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': '1572834916@qq.com',
'password': 'xxx'
}
r2 = session.post('https://github.com/session', data=data) # 第三次请求:以后的登录,拿着login_cookie就可以,比如访问一些个人配置
r3 = session.get('https://github.com/settings/emails') print('1572834916@qq.com' in r3.text) # True
4.响应Response
(1)response属性
import requests
response = requests.get('http://www.zhihu.com')
# response属性
print(response.text) # 以文本形式打印网页源码
print(response.content) # 以字节流形式打印
print(response.status_code) # 打印状态码
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookies信息
print(response.cookies.get_dict()) # 将cookies信息以字典方式打印
print(response.cookies.items()) # 打印cookies的键
print(response.url) # 输出响应的链接
print(response.encoding) # 输出响应的编码(从header中猜测的响应内容编码格式)
(2)编码问题
# 编码问题
import requests
response = requests.get('http://www.autohome.com/news') # 将编码设置为网站的编码(不设置可能无法显示中文)
response.encoding = response.apparent_encoding
print(response.text)
(3)获取二进制数据
import requests
response = requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1509868306530&di=712e4ef3ab258b36e9f4b48e85a81c9d&imgtype=0&src=http%3A%2F%2Fc.hiphotos.baidu.com%2Fimage%2Fpic%2Fitem%2F11385343fbf2b211e1fb58a1c08065380dd78e0c.jpg')
# 以字节流的形式写入文件
with open('girl.jpg', 'wb') as f:
f.write(response.content)
#stream参数:一点一点的取,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
import requests
response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in response.iter_content():
f.write(line)
(4)解析json
#解析json
import requests
import json response=requests.get('http://httpbin.org/get')
res1=json.loads(response.text) # 太麻烦
res2=response.json() # 直接获取json数据 print(res1 == res2) # True
5.所有方法及所有参数
(1)requests模块中所有方法
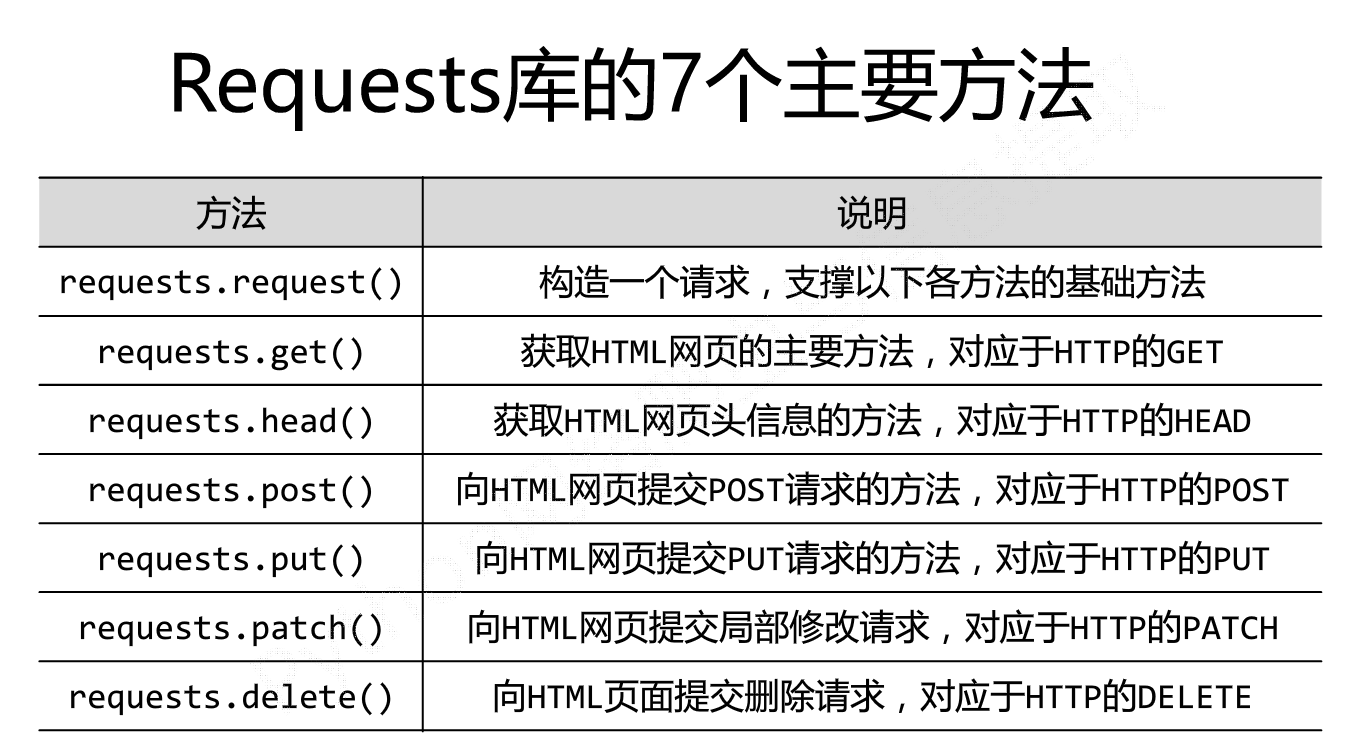
requests.get(url, params=None, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs) # 以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)
(2)requests模块中的参数
重要的参数:
- method: 提交方式
- url: 提交地址
- params: 在URL中传递的参数,GET中独有
requests.request(
method='GET',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'}
)
请求的链接:http://www.oldboyedu.com?k1=v1&k2=v2
- data: 在请求体里传递的数据
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
data = {'use':'wyb','pwd': '123'}(也可以写成"user=wyb&pwd=123")
)
请求头: content-type: application/url-form-encod.....
请求体: "use=wyb&pwd=123"
- json 在请求体里传递的数据
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
json = {'use':'wyb','pwd': '123'}
)
请求头: content-type: application/json
请求体: "{'use':'wyb','pwd': '123'}"
注: 当字典中嵌套字典时使用json
- headers 请求头
requests.request(
method='POST',
url= 'http://www.oldboyedu.com',
params = {'k1':'v1','k2':'v2'},
json = {'use':'alex','pwd': '123'},
headers={
'Referer': 'http://dig.chouti.com/',
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36"
}
)
- cookies Cookies
其他参数:
- files 上传文件
- auth 基本认知(headers中加入加密的用户名和密码)
- timeout 请求和响应的超时时间
- allow_redirects 是否允许重定向
- proxies 代理
- verify 是否忽略证书
- cert 证书文件
- stream 村长下大片
- session: 用于保存客户端历史访问信息
import requests
files= {"files":open("git.jpg","rb")}
response = requests.post("http://httpbin.org/post",files=files)
print(response.text)
(2)获取cookie
import requests
response = requests.get("http://www.baidu.com")
print(response.cookies)
for key,value in response.cookies.items():
print(key+"="+value)
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests
s = requests.Session()
s.get("http://httpbin.org/cookies/set/number/123456")
response = s.get("http://httpbin.org/cookies")
print(response.text)
两次requests请求之间是独立的,通过创建一个session对象,两次请求都通过这个对象访问
(3)证书验证
现在的很多网站都是https的方式访问,所以这个时候就涉及到证书的问题
import requests
response = requests.get("https:/www.12306.cn")
print(response.status_code)
默认的12306网站的证书是不合法的,这样就会提示错误,为了避免这种情况的发生可以通过verify=False
但是这样是可以访问到页面,但是会提示:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
解决方法为:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get("https://www.12306.cn",verify=False)
print(response.status_code)
这样就不会提示警告信息,当然也可以通过cert参数放入证书路径
(4)代理设置
import requests
proxies= {
"http":"http://127.0.0.1:9999",
"https":"http://127.0.0.1:8888"
}
response = requests.get("https://www.baidu.com",proxies=proxies)
print(response.text)
如果代理需要设置账户名和密码,只需要将字典更改为如下:
proxies = {
"http":"http://user:password@127.0.0.1:9999"
}
如果你的代理是通过sokces这种方式则需要pip install "requests[socks]"
proxies= {
"http":"socks5://127.0.0.1:9999",
"https":"sockes5://127.0.0.1:8888"
}
(5)超时设置 -> 通过timeout参数可以设置超时的时间
(6)认证设置 -> 如果碰到需要认证的网站可以通过requests.auth模块实现
import requests
from requests.auth import HTTPBasicAuth
response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123"))
print(response.status_code)
当然这里还有一种方式
import requests
response = requests.get("http://120.27.34.24:9001/",auth=("user","123"))
print(response.status_code)
7.requests使用实例
# __author__ = "wyb"
# date: 2018/5/21
import requests url = "https://item.jd.com/5036602.html"
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
res.raise_for_status()
res.encoding = res.apparent_encoding
print(res.status_code)
print(res.text)
except:
print("爬取失败")
爬取京东商品页面
# __author__ = "wyb"
# date: 2018/5/21
import requests url = "http://www.baidu.com/s"
kv = {"wd": "python"} # 搜索关键词 try:
res = requests.get(url, params=kv)
print(res.url)
print(res.status_code)
res.raise_for_status()
print(res.text)
except:
print("爬取失败")
百度关键词搜索
# __author__ = "wyb"
# date: 2018/5/21
import requests url = "http://m.ip138.com/ip.asp?ip=" try:
ip = "202.204.80.112"
res = requests.get(url+ip)
res.raise_for_status()
res.encoding = res.apparent_encoding
print(res.text[-500:])
except:
print("爬取失败")
IP地址归属地查询
# __author__ = "wyb"
# date: 2018/5/26 import os
import requests
from bs4 import BeautifulSoup
import re
import time headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Mobile Safari/537.36"
} # url = "https://www.zhihu.com/question/22918070" # url为知乎链接
url = input("请输入知乎的链接>>>").strip()
links = [] try:
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'html.parser')
# 用Beautiful Soup结合正则表达式来提取包含所有图片链接(img标签中,class=**,以.jpg格式结尾的链接)的语句
links = soup.find_all('img', src=re.compile(r'.jpg$'))
# print(links)
except Exception as e:
print("请输入正确的链接或查看网络是否连接!")
exit() try:
# 设置保存图片的路径,否则会保存到程序当前路径
path = r'./images' # 路径前的r是保持字符串原始值的意思,就是说不对其中的符号进行转义
for link in links:
print(link.attrs['src'])
src = link.attrs['src']
if not os.path.exists('imgs'):
os.mkdir('imgs')
img = requests.get(src, headers=headers)
import uuid
with open("imgs/%s.jpg" % uuid.uuid4(), "wb") as f:
f.write(img.content)
except Exception as e:
print()
else:
print("图片下载成功请到该程序目录下的imgs文件夹下查看") print("牛不牛逼啊?") time.sleep(5)
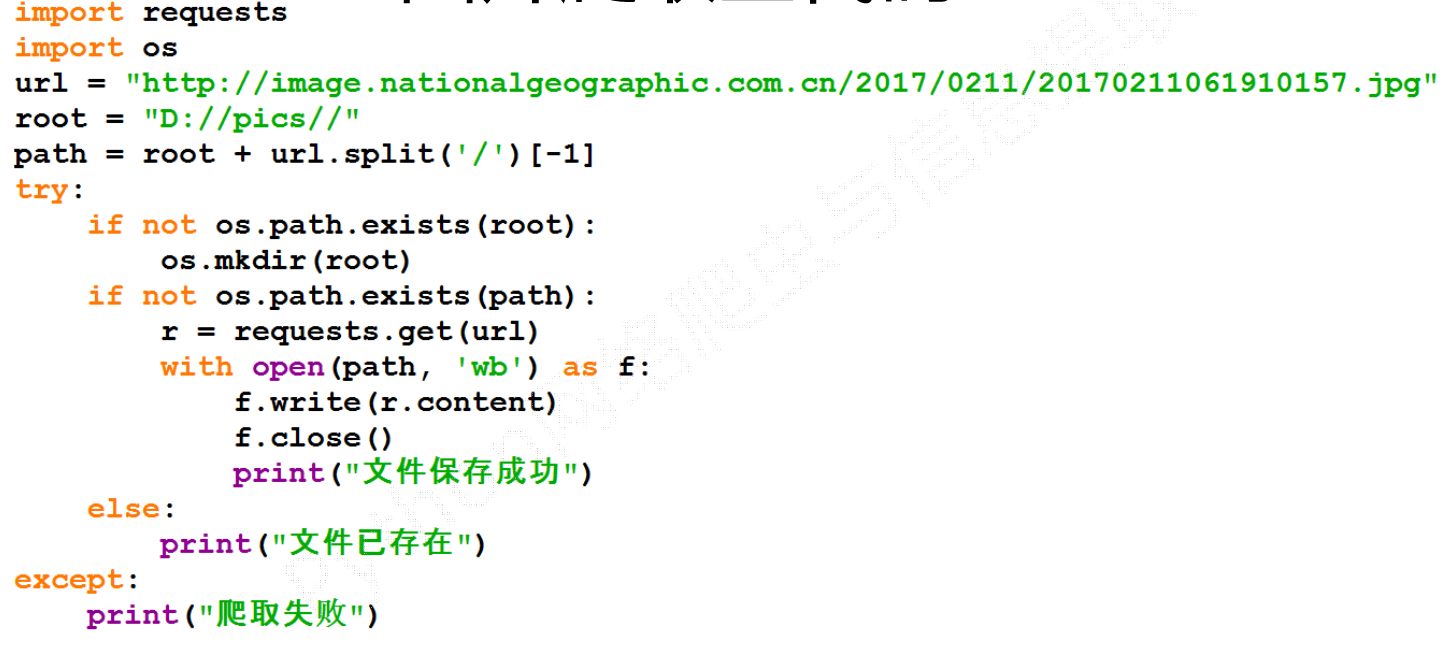
爬取知乎图片
爬取图片原理:
二、selenium库
1.selenium介绍与其作用
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
from selenium import webdriver
browser=webdriver.Chrome()
browser=webdriver.Firefox()
browser=webdriver.PhantomJS()
browser=webdriver.Safari()
browser=webdriver.Edge()
注:个人推荐使用PhantomJS这个浏览器,直接百度下载安装,安装完了后配置一下path即可
2.selenium基本使用
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser=webdriver.Chrome()
try:
browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) #输入回车 wait=WebDriverWait(browser,10)
# 等到id为content_left的元素加载完毕,最多等10秒
wait.until(EC.presence_of_element_located((By.ID,'content_left'))) print(browser.page_source)
print(browser.current_url)
print(browser.get_cookies()) finally:
browser.close()
三、BeautifulSoup4库
#安装 Beautiful Soup
pip install bs4 #安装解析器
pip install lxml
pip install html5lib
BeautifulSoup中可以使用的解释器如下:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
|
|
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
|
|
| lxml XML 解析器 |
BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") |
|
|
| html5lib | BeautifulSoup(markup, "html5lib") |
|
|
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
""" soup = BeautifulSoup(html, 'html.parser') # 创建BeautifulSoup对象
print(soup.prettify()) # 打印soup对象(格式化输出)
(2)BeautifulSoup对象中的常用方法
- find_all方法:fin_all(tag, attributes, recursive, text, limit, keywords)
- find方法:find(tag, attributes, recursive, text, keywords)
- find()方法类似find_all()方法,只不过find_all()方法返回的是文档中符合条件的tag是一个集合,而find()方法返回的只是一个tag
- select()方法: # select方法中的选择器类似CS,将在后面详细介绍
- get_text()方法 -> 获取对象中的文本内容
find和find_all中的参数:
- tag:标签名
- attributes:一个标签的若干属性和其对应的值
- recursive:布尔变量,设置为True表示会递归查找,否则不会递归查找,find_all方法默认支持递归查找,一般情况下这个参数不需要设置
- text:用标签的文本内容匹配
- limit:只用于find_all方法,find其实等价于find_all参数limit等于1时的情况
- keyword:选择那些具有指定属性的标签
(3)BeautifulSoup对象中的属性
- 标签选择器:soup.标签名 -> 获得这个标签(多个这样的标签,返回的结果是第一个标签)
- 获取名称:soup.标签.name -> 获得该标签的名称
- 获取属性:soup.p.attrs['name']或soup.p['name'] -> 可以获取p标签的name属性值
- 获取内容:soup.p.string -> 可以获取第一个p标签的内容
- 嵌套选择:soup.head.title.string -> 获取head标签中的title标签中的内容
# __author__ = "wyb"
# date: 2018/5/21
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
""" soup = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象 print(soup.title) # 输出title标签
print(soup.title.name) # 输出title标签的name
print(soup.p) # 输出第一个p标签
print(soup.p.string) # 输出第一个p标签的内容
print(soup.p['class']) # 输出第一个p标签的class值
print(soup.p.b) # 嵌套查询
(4)BeautifulSoup中节点
子节点:contents和children
子孙节点:descendants
父节点:parent
祖先节点:list(enumerate(soup.a.parents))
兄弟节点:
- soup.a.next_siblings 获取后面的兄弟节点
- soup.a.previous_siblings 获取前面的兄弟节点
- soup.a.next_sibling 获取下一个兄弟标签
- souo.a.previous_sinbling 获取上一个兄弟标签
# __author__ = "wyb"
# date: 2018/5/21
from bs4 import BeautifulSoup
html = """
<html>
<head><title>The Dormouse's story</title></head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml') # 获取子节点
print(soup.p.contents) # 将p标签下的所有子标签存入到了一个列表中
print(soup.p.children) # 迭代对象,而不是列表,只能通过循环的方式获取信息 # 获取子孙节点
print(soup.descendants) # 迭代对象,而不是列表,只能通过循环的方式获取信息 # 获取父节点
print(soup.p.parent) print(soup.p.next_siblings) # 获取后面的兄弟节点
print(soup.p.previous_siblings) # 获取前面的兄弟节点
print(soup.p.next_sibling) # 获取下一个兄弟标签
print(soup.p.previous_sinbling) # 获取上一个兄弟标签
- .表示class #表示id
- 标签1,标签2 找到所有的标签1和标签2
- 标签1 标签2 找到标签1内部的所有的标签2
- [attr] 可以通过这种方法找到具有某个属性的所有标签
- [atrr=value] 例子[target=_blank]表示查找所有target=_blank的标签
- 获取内容:通过get_text()就可以获取文本内容
- 获取属性:获取属性可以通过[属性名]或者attrs[属性名]
# __author__ = "wyb"
# date: 2018/5/21
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
<b>The Dormouse's story</b>
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
<div class='panel-1'>
<ul class='list' id='list-1'>
<li class='element'>Foo</li>
<li class='element'>Bar</li>
<li class='element'>Jay</li>
</ul>
<ul class='list list-small' id='list-2'>
<li class='element'><h1 class='yyyy'>Foo</h1></li>
<li class='element xxx'>Bar</li>
<li class='element'>Jay</li>
</ul>
</div>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml') # 1、CSS选择器
print(soup.p.select('.sister'))
print(soup.select('.sister span'))
print(soup.select('#link1'))
print(soup.select('#link1 span'))
print(soup.select('#list-2 .element.xxx')) # 2、获取属性
print(soup.select('#list-2 h1')[0].attrs) # 3、获取内容
print(soup.select('#list-2 h1')[0].get_text())
5.BeautifulSoup使用实例
(1)BeautifulSoup简单使用
from bs4 import BeautifulSoup html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title">
<b>The Dormouse's story</b>
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
<div class='panel-1'>
<ul class='list' id='list-1'>
<li class='element'>Foo</li>
<li class='element'>Bar</li>
<li class='element'>Jay</li>
</ul>
<ul class='list list-small' id='list-2'>
<li class='element'><h1 class='yyyy'>Foo</h1></li>
<li class='element xxx'>Bar</li>
<li class='element'>Jay</li>
</ul>
</div>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
""" soup = BeautifulSoup(html, "lxml")
for link in soup.find_all('a'):
print(link.get("href"))
找出所有a标签中的链接
(2)综合使用
python应用之爬虫实战2 请求库与解析库的更多相关文章
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- python应用之爬虫实战1 爬虫基本原理
知识内容: 1.爬虫是什么 2.爬虫的基本流程 3.request和response 4.python爬虫工具 参考:http://www.cnblogs.com/linhaifeng/article ...
- python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 2.请求资源列表页面,定位获得左侧目录每一章的跳转url(难点) 3.请求每个跳转url,定位右侧下载 ...
- Python爬虫实战(一) 使用urllib库爬取拉勾网数据
本笔记写于2020年2月4日.Python版本为3.7.4,编辑器是VS code 主要参考资料有: B站视频av44518113 Python官方文档 PS:如果笔记中有任何错误,欢迎在评论中指出, ...
- 爬虫:HTTP请求与HTML解析(爬取某乎网站)
1. 发送web请求 1.1 requests 用requests库的get()方法发送get请求,常常会添加请求头"user-agent",以及登录"cookie&q ...
- 爬虫实战【7】Ajax解析续-今日头条图片下载
昨天我们分析了今日头条搜索得到的信息,一直对图集感兴趣的我还是选择将所有的图片下载下来. 我们继续讲一下如何通过各个图集的url得到每个图集下面的照片. 分析图集的组成 [插入图片,某个图集的页面] ...
- 爬虫实战【8】Selenium解析淘宝宝贝-获取多个页面
作为全民购物网站的淘宝是在学习爬虫过程中不可避免要打交道的一个网站,而是淘宝上的数据真的很多,只要我们指定关键字,将会出现成千上万条数据. 今天我们来讲一下如何从淘宝上获取某一类宝贝的信息,比如今天我 ...
- 爬虫实战【9】Selenium解析淘宝宝贝-获取宝贝信息并保存
通过昨天的分析,我们已经能到依次打开多个页面了,接下来就是获取每个页面上宝贝的信息了. 分析页面宝贝信息 [插入图片,宝贝信息各项内容] 从图片上看,每个宝贝有如下信息:price,title,url ...
- 爬虫模块介绍--Beautifulsoup (解析库模块,正则)
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
随机推荐
- MQTT连接服务器返回2
/********************************************************************************* * MQTT连接服务器返回2 * ...
- os.path.join 用法
写在前面的话:看大家阅读量这么大,也应该在放点干货来了~~ 获取层级路径,直到可以获取文件夹下面的文件,多一个判断就行了: level1_list = [os.path.join(base_path, ...
- BZOJ1095: [ZJOI2007]Hide 捉迷藏【线段树维护括号序列】【思维好题】
Description 捉迷藏 Jiajia和Wind是一对恩爱的夫妻,并且他们有很多孩子.某天,Jiajia.Wind和孩子们决定在家里玩 捉迷藏游戏.他们的家很大且构造很奇特,由N个屋子和N-1条 ...
- .NET Core Generic Host Windows服务部署使用Topshelf
此文源于前公司在迁移项目到.NET Core的过程中,希望使用Generic Host来管理定时任务程序时,没法部署到Windows服务的问题,而且官方也没给出解决方案,只能关注一下官方issue # ...
- 杭电 KazaQ's Socks
KazaQ wears socks everyday. At the beginning, he has n pairs of socks numbered from 1 to n in his cl ...
- alpha和color key
一.alpha 1.透明度,一般取值0-255 2.Alpha 通道: Alpha 通道是为保存选择区域而专门设计的通道.在生成一个图像文件时,并不必须产生 Alpha 通道.通常它是由人们在图 ...
- day37 mysql数据库学习
3.什么是数据库 用来存储数据的仓库 数据是以文件的形式保存 海峰补充内容 ↓ 4 数据库服务器.数据管理系统.数据库.表与记录的关系(重点理解!!!) 记录:1 刘海龙 324245234 2 ...
- 彻底删除vscode及安装的插件和个人配置信息
1.卸载vscode应用软件(在控制面板里面找不到改软件,所以只能进入应用所在文件夹进行卸载) ## 此步骤虽然删掉了应用软件,但是此时重新安装会发现之前下载的插件和个人配置信息都还会重新加载出来,所 ...
- Java的四种引用之强弱软虚
在java中提供4个级别的引用:强引用.软引用.弱引用和虚引用.除了强引用外,其他3中引用均可以在java.lang.ref包中找到对应的类.开发人员可以在应用程序中直接使用他们. 1 强引用 强引用 ...
- Grid中添加链接,打开选项卡页面
如何在grid中点击,添加一个选项卡并打开页面 function addeditnew(id, title) { var node ...