Python 爬虫实例(8)—— 爬取 动态页面
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图
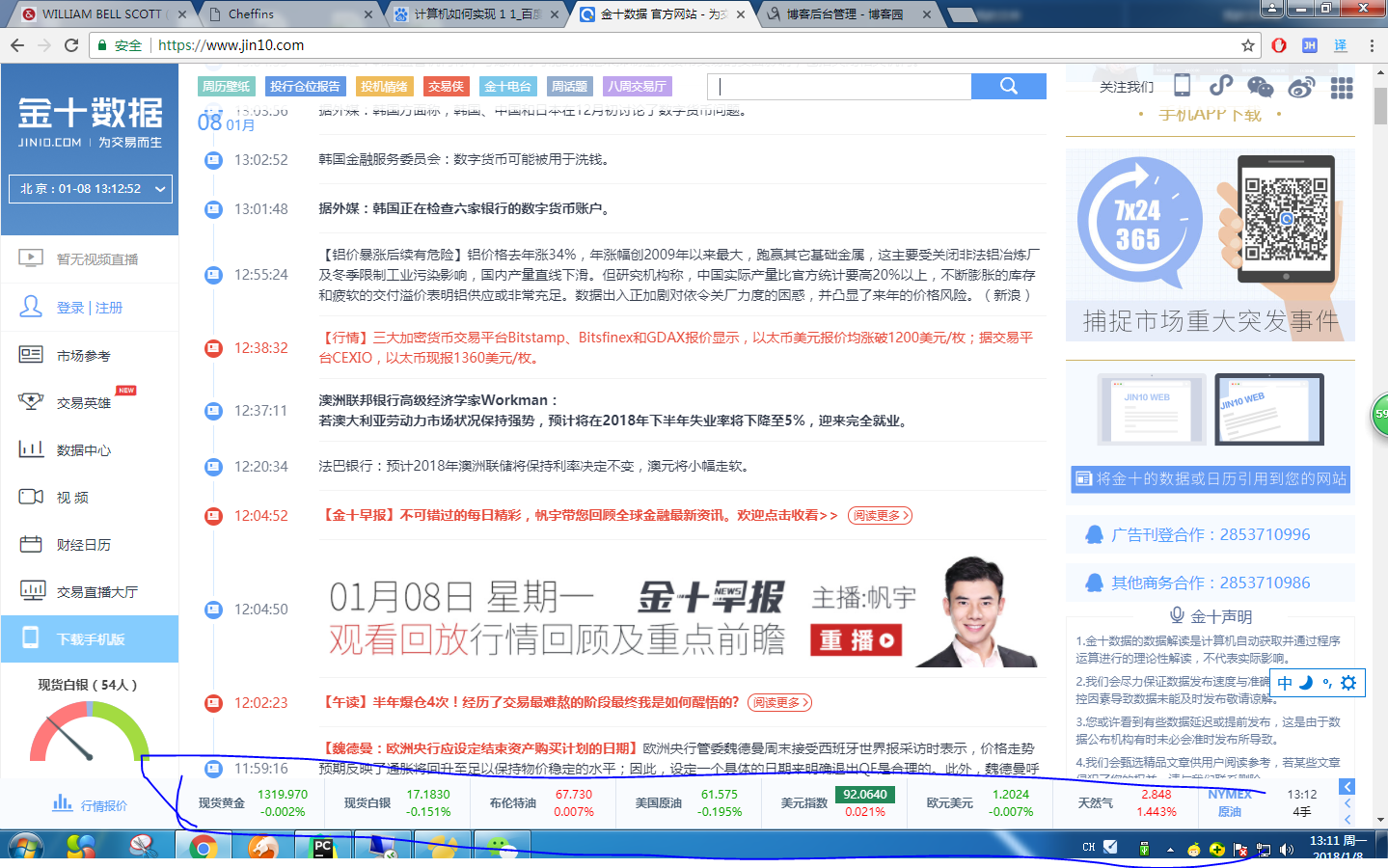
源代码:
#-*-coding:utf-8-*-
import time
from selenium import webdriver
import os
import re
#引入chromedriver.exe
chromedriver = "C:/Users/xuchunlin/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver) #设置浏览器需要打开的url
url = "https://www.jin10.com/"
# 使用for循环不停的刷新页面,也可以每隔一段时间刷新页面
for i in range(1,100000):
browser.get(url)
result= browser.page_source
gold_price = ""
gold_price_change = ""
try:
gold_price = re.findall('<div id="XAUUSD_B" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
gold_price_change = re.findall('<div id="XAUUSD_P" class="jin-price_value" style=".*?">(.*?)</div>',result)[0]
except:
gold_pric = "------"
gold_price_change = "------" print gold_price
print gold_price_change
time.sleep(1)
Python 爬虫实例(8)—— 爬取 动态页面的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
随机推荐
- 简单配置umiJS学习笔记
最近跟着Antd-Pro官方教程学习umi,这里给大家推荐一下这个教程,特别适合初学者学习,教程涉及了AntD,AntD-Pro,umiJS,dvaJS等框架知识. 学习过程中跟着教程做了个Demo, ...
- ironic-inspector硬件信息收集
主机上报 ironic-inspector流程会在小系统里收集裸机的硬件信息,然后上报到ironic-conductor. 其中收集硬件信息主要使用hwinfo和lshw命令.Centos可以使用如下 ...
- [jzoj]1729.blockenemy
Link https://jzoj.net/senior/#main/show/1729 Description 你在玩电子游戏的时候遇到了麻烦...... 你玩的游戏是在一个虚拟的城市里进行,这个城 ...
- pointer-net
Pointer network 主要用在解决组合优化类问题(TSP, Convex Hull等等),实际上是Sequence to Sequence learning中encoder RNN和deco ...
- JS_高程3.基本概念(3)
1.ECMAScript数值的范围 由于内存的限制,在大多数浏览器中,ECMAScript能够拿保存的数据的范围是 5e-324 ~ 1.7976931348623157e+308,其中最小的数值保存 ...
- FIlter(2)—案例
案例 demo2,login.jsp请求提交到hello.jsp,该页面中有两个text,分别使用两个Filter链拦截,验证账号密码是否正确,把账号密码设置到Filter初始化参数中 login.j ...
- IO流(4)—字符流
1.IO体系: 抽象基类 --节点流(文件流) InputStream -- FileInputStream OutputStream --FileOutputSteam Reader --FileR ...
- linux 下令chmod 755的意思
linux 命令chmod 755的意思 chmod是Linux下设置文件权限的命令,后面的数字表示不同用户或用户组的权限. 一般是三个数字:第一个数字表示文件所有者的权限第二个数字表示与文件所有者同 ...
- sqoop导出到hdfs
./sqoop export --connect jdbc:mysql://192.168.58.180/db --username root --password 123456 --export- ...
- java.lang.NumberFormatException: multiple points错误问题
最近项目一直会出现时间转换报错,一直不知道是什么问题??? java.lang.NumberFormatException: multiple points at sun.misc.Float ...