Python分布式爬虫抓取知乎用户信息并进行数据分析
在以前的文章中,我写过一篇使用selenium来模拟登录知乎的文章,然后在很长一段时间里都没有然后了。。。
不过在最近,我突然觉得,既然已经模拟登录到了知乎了,为什么不继续玩玩呢?所以就创了一个项目,用来采集知乎的用户公开信息,打算用这些数据试着分析一下月入上万遍地走、清华北大不如狗的贵乎用户像不像我们想象中的那么高质量。
第一步:首先是爬虫抓取用户信息,能用图解释的绝不多废话:
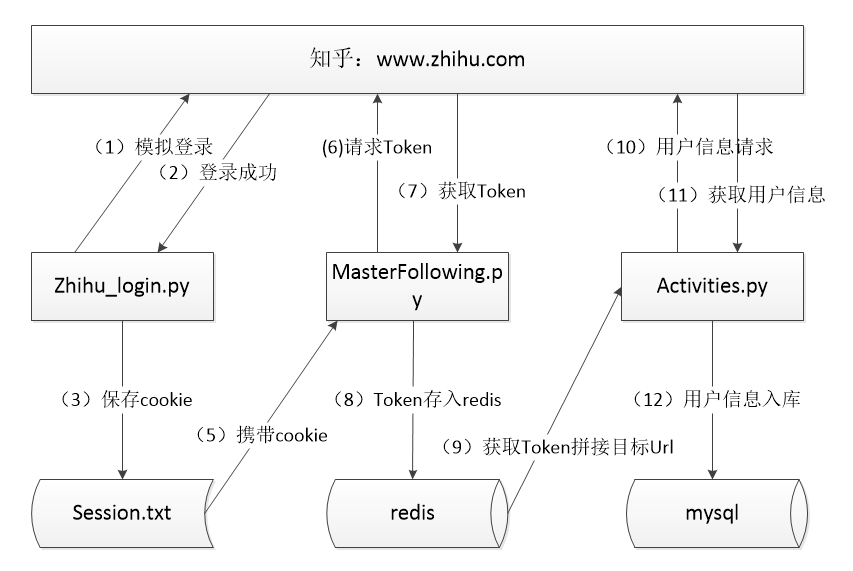
但是还是得主要说下:
首先:个人感觉,在写一些小的demo时用框架就反而更显得繁琐,所以我没有使用框架,而是自己使用requests来发起请求的。
然后简要解释一下整体流程:
(1)zhihu_login.py 是我模拟登录的脚本,并且在前三步中,理想状态下是利用schedule写一个定时执行框架,定期的更换session.txt中的cookie以供后边的抓取脚本使用,然而非常无奈,
这个方法是我在最后数据抓取基本结束时才想到的,所以没有用到,所以我在抓取数据时使用了代理IP.的。
(2)画图时将错误的将第4步写成了第5步。。。MasterFollowing.py是用来获取用户唯一标示:Token的,原理是:以一个用户的url作为起始地址发起请求,遍历该用户的关注列表,将关注列表中的所有用户Token都存入redis中,
下一次请求时,将会从redis中随机取出一个Token拼接成目标url再遍历关注列表将Token存入redis中,因为理论上从redis中取出一个Token就会向里边塞入少则几十多达上百个Token(视该用户关注人数而定),所以理论上redis中的Token值会越来越多,
且我是以set类型来存Token的,所以会自动去重,非常方便。
(3)activities.py是用来抓取最终用户信息的,它每次redis中获取一个Token,拼接成目标Url,请求用户详情页面,采集到用户信息,将其存入到数据库中。
(4)因为两个脚本之间使用redis进行数据共享,即使有哪个蜘蛛宕掉,也不会造成数据丢失,达到了断点续传的效果。
(5)整个过程中,唯一扯淡的是,知乎似乎对并发数做出了限制,当并发请求超过某一阀值时,请求就会被重定向到验证页面,即使使用了代理IP也没用。不过我想,如果用我最终想到的方法每隔一段时间模拟请求,更换cookie的话,
这个问题有可能会得到解决。
整个爬虫项目我在个人github上边扔着,大家可以去拉下来玩玩,感兴趣的可以帮我把代码完善下,把那个定时更新cookie的代码加上,或者各位有什么更好的方法,也可以告诉我。
github地址:https://github.com/songsa1/zhihu_user_relationship
第二步:使用抓取下的数据进行简单分析
大概抓了20w左右的数据,并且数据分析的代码也在上边那个项目中丢着,制作图表使用了matplotlib.
首先我们知道,知乎个人信息中,所属行业一共分为了14大类、98小类:

我们先看看按照小类来分的话,知乎用户群体主要是做什么的呢?
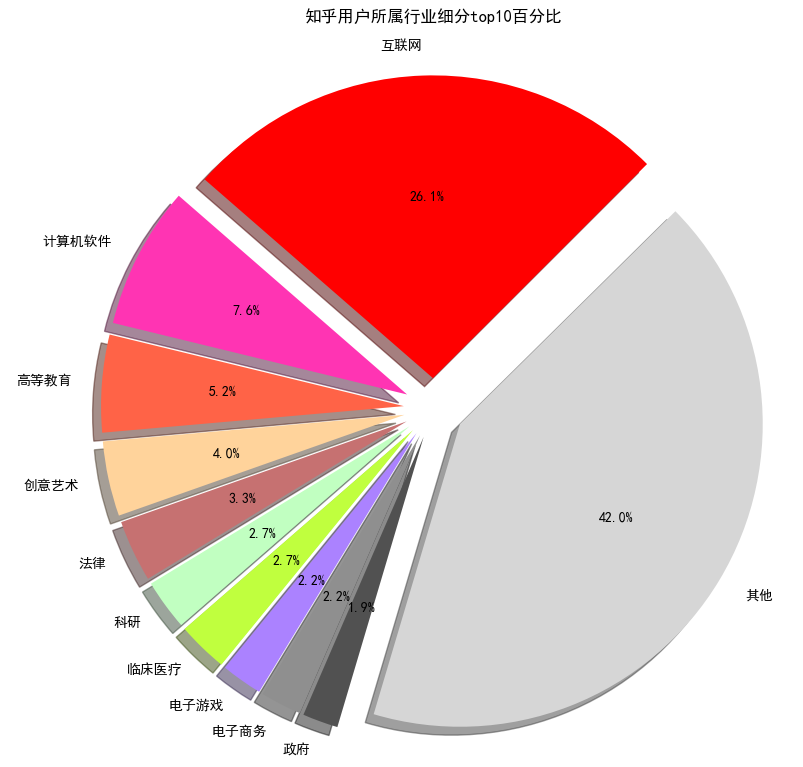
不出所料啊,互联网行业果然是最多的,当然,也有存在误差的可能,我是以我的知乎用户作为起点来抓取的,我关注的人中基本都是互联网圈中的,这样传递下去,采集到的数据中IT圈中的人估计会多一些,不过窥一斑而知全豹,真实情况估计也差不太多。
这次按照14大类来瞅一下:

依旧是高新科技位居第一啊,教育行业和服务行业紧随其后。
然后我们再来看看知乎用户群体的性别比例:
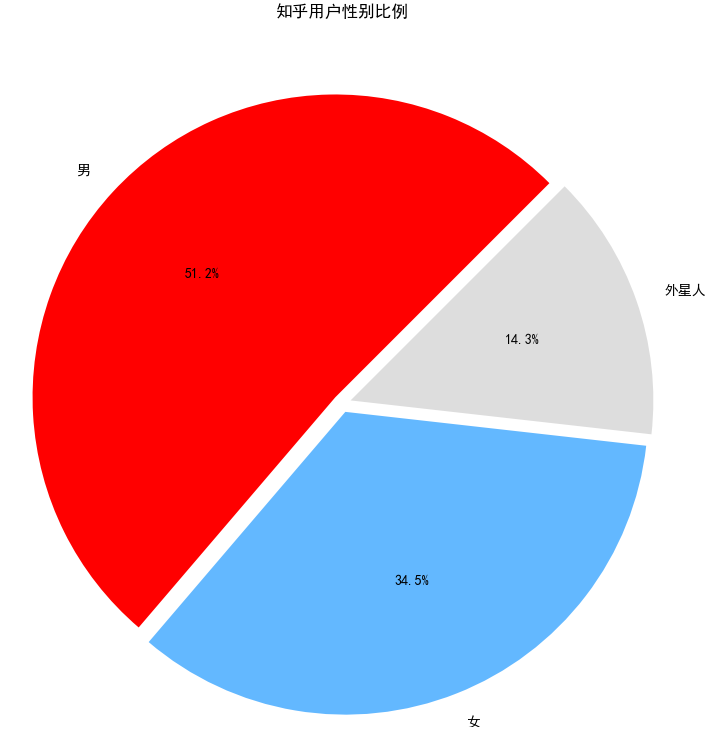
果然男性用户占据了一半还多,女性用户只占了34%,当然还有14%没有填性别的外星人。
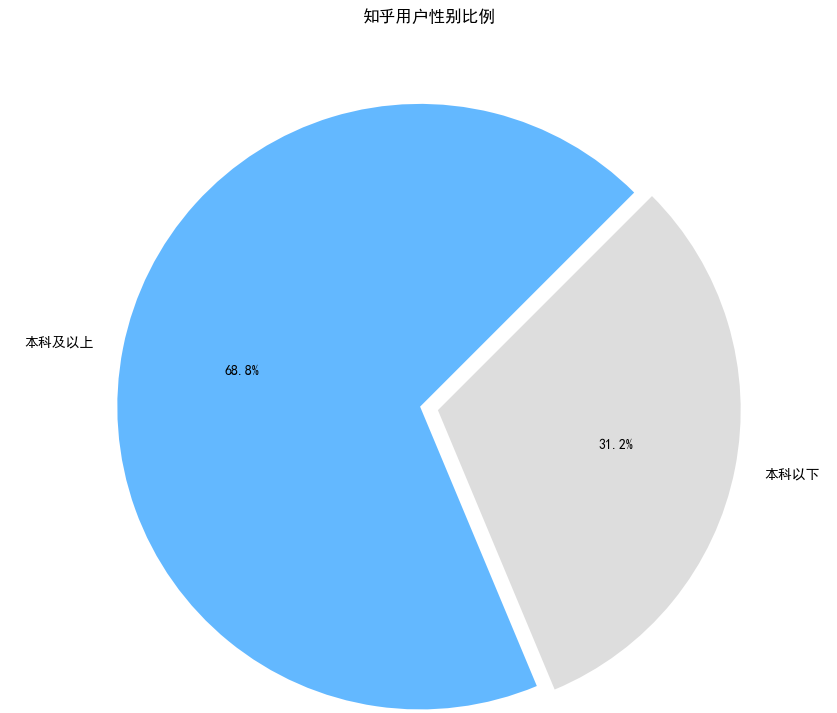
我们一直说逼乎贵乎,一听起来就很有档次的感觉,不负众望,知乎用户群体的文化程度还是非常高的,果然清华北大遍地走,985、211不如狗啊,有图为证(词云中字体越大表明权重越大):

最后我们来看看知乎用户群体大概居住地,目测北上广等一线新一线比较多:

想了解更多Python关于爬虫、数据分析的内容,欢迎大家关注我的微信公众号:悟道Python

Python分布式爬虫抓取知乎用户信息并进行数据分析的更多相关文章
- python3编写网络爬虫22-爬取知乎用户信息
思路 选定起始人 选一个关注数或者粉丝数多的大V作为爬虫起始点 获取粉丝和关注列表 通过知乎接口获得该大V的粉丝列表和关注列表 获取列表用户信息 获取列表每个用户的详细信息 获取每个用户的粉丝和关注 ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- 基于scrapy的分布式爬虫抓取新浪微博个人信息和微博内容存入MySQL
为了学习机器学习深度学习和文本挖掘方面的知识,需要获取一定的数据,新浪微博的大量数据可以作为此次研究历程的对象 一.环境准备 python 2.7 scrapy框架的部署(可以查看上一篇博客的简 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
随机推荐
- html学习笔记(一)div的透明设置
要使得div的透明度设置,有两种方法. 第一种:使用opacity属性,单词的意思是不透明性,你可以设置它的值,范围是0到1,1为不透明,0为全透明.具体使用如下: css代码: #div01{ ba ...
- jQueryMobile(二)
三].按钮 <!-- 一个jQueryMobile页面 --> <div data-role='page'> <div data-role='header'>< ...
- android selector中使用shape
<shape> <!-- 实心 --> <solid android:color="#ff9d77"/> <!-- 渐变 --&g ...
- System Center Configuration Manager 2016 必要条件准备篇(Part4)
步骤4.重新启动Configuration Manager主服务器 注意:在Configuration Manager服务器(CM01)上以本地管理员身份执行以下操作 打开管理命令提示符并发出以下 ...
- manjaro安装后你需要做的配置
1.切换中国源 sudo gedit /etc/pacman-mirrors.conf 如果提示没有gedit , 则执行命令 : sudo pacman -S gedit 修改如下地方为中国: On ...
- Selenium入门系列3 单个元素的定位方法
UI自动化首先要识别对象,再操作对象,最后判定实际结果与预期结果是否一致. 这一节学习的是识别单个对象,webdriver提供了8种方式. <a id="idofa" cla ...
- 将TIMESTAMP类型的差值转化为秒的方法
两个TIMESTAMP之差得到的是INTERVAL类型,而有时我们只需要得到两个时间相差的秒数,如果变成INTERVAL之后,想要获取这个值会非常麻烦. 比较常见的方法是使用EXTRACT来抽取获得的 ...
- Map的嵌套,HDU(1263)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1263 新学的map的嵌套 #include <stdio.h> #include < ...
- 为什么实例没有prototype属性?什么时候对象会有prototype属性呢?
为什么实例没有prototype属性?什么时候对象会有prototype属性呢? javascript loudou 1月12日提问 关注 9 关注 收藏 6 收藏,554 浏览 问题对人有帮助,内容 ...
- Java的感受
感觉Java很重要,但是学起来好像并不比C语言简单.