4.DataFrame(快速开始)
快速开始

基本概念
''' 在使用 DataFrame 时,需要了解三个对象上的操作:Collection(DataFrame) ,Sequence,Scalar Collection(DataFrame)表示表结构(或者二维结构) Sequence表示列(一维结构) Scalar表示标量 要注意的是,这些对象仅在使用 Pandas 数据创建后会包含实际数据 而在 ODPS 表上创建的对象中并不包含实际的数据, 而仅仅包含对这些数据的操作,实质的存储和计算会在 ODPS 中进行。 ''' # 创建DataFrame ''' 通常情况下,你唯一需要直接创建的 Collection 对象是 DataFrame,这一对象用于引用数据源 可能是一个 ODPS 表, ODPS 分区,Pandas DataFrame或sqlalchemy.Table(数据库表) 用这几种数据源时,相关的操作相同,这意味着你可以不更改数据处理的代码 仅仅修改输入/输出的指向, 便可以简单地将小数据量上本地测试运行的代码迁移到 ODPS 上, 而迁移的正确性由 PyODPS 来保证。 创建 DataFrame 非常简单,只需将 Table 对象、 pandas DataFrame 对象或者 sqlalchemy Table 对象传入即可。 '''

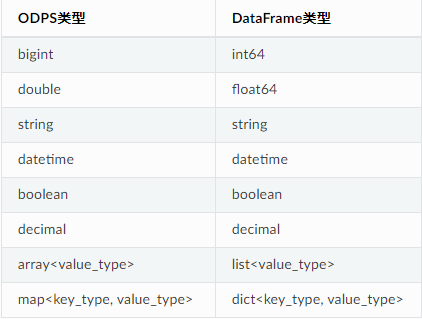
# 列类型 ''' DataFrame包括自己的类型系统,在使用Table初始化的时候,ODPS的类型会被进行转换。 这样做的好处是,能支持更多的计算后端。 目前,DataFrame的执行后端支持ODPS SQL、pandas以及数据库(MySQL和Postgres)。 PyODPS DataFrame 包括以下类型 int8,int16,int32,int64,float32,float64,boolean,string,decimal,datetime,list,dict ODPS的字段和DataFrame的类型映射关系如下: '''
4.DataFrame(快速开始)的更多相关文章
- 今天整理了几个在使用python进行数据分析的常用小技巧、命令。
提高Python数据分析速度的八个小技巧 01 使用Pandas Profiling预览数据 这个神器我们在之前的文章中就详细讲过,使用Pandas Profiling可以在进行数据分析之前对数据进行 ...
- 如何通过Elasticsearch Scroll快速取出数据,构造pandas dataframe — Python多进程实现
首先,python 多线程不能充分利用多核CPU的计算资源(只能共用一个CPU),所以得用多进程.笔者从3.7亿数据的索引,取200多万的数据,从取数据到构造pandas dataframe总共大概用 ...
- Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程 ...
- [大数据之Spark]——快速入门
本篇文档是介绍如何快速使用spark,首先将会介绍下spark在shell中的交互api,然后展示下如何使用java,scala,python等语言编写应用.可以查看编程指南了解更多的内容. 为了良好 ...
- Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN
快速入门 使用 Spark Shell 进行交互式分析 基础 Dataset 上的更多操作 缓存 独立的应用 快速跳转 本教程提供了如何使用 Spark 的快速入门介绍.首先通过运行 Spark 交互 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- pandas.DataFrame学习系列1——定义及属性
定义: DataFrame是二维的.大小可变的.成分混合的.具有标签化坐标轴(行和列)的表数据结构.基于行和列标签进行计算.可以被看作是为序列对象(Series)提供的类似字典的一个容器,是panda ...
- Pandas快速入门笔记
我正以Python作为突破口,入门机器学习相关知识.出于机器学习实践过程中的需要,我快速了解了一下提供了类似关系型或标签型数据结构的Pandas的使用方法.下面记录相关学习笔记. 数据结构 Panda ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
随机推荐
- storm集群安装部署
安装步骤: 搭建Zookeeper集群: 安装Storm依赖库: 下载并解压Storm发布版本: 修改storm.yaml配置文件: 启动Storm各个后台进程. 1. 搭建Zookeeper集群 这 ...
- Git-Git克隆
鸡蛋不装在一个篮子里 Git的版本库目录和工作区在一起,因此存在一损俱损的问题,即如果删除一个项目的工作区,同时也会把这个项目的版本库删除掉.一个项目仅在一个工作区中维护太危险了,如果有两个工作区就会 ...
- ZOJ 3329 Problem Set (期望dp)
One Person Game There is a very simple and interesting one-person game. You have 3 dice, namely Die1 ...
- 后端接口迁移(从 webapi 到 openapi)前端经验总结
此文已由作者张磊授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 前情提要 以前用的是 webapi 现在统一切成 openapi,字段结构统统都变了 接入接口 20+,涉及模 ...
- GCD那些事儿
GCD GCD,全名Grand Central Dispatch,中文名郭草地,是基于C语言的一套多线程开发API,一听名字就是个狠角色,也是目前苹果官方推荐的多线程开发方式.可以说是使用方便,又不失 ...
- react书写规范小记
1.对齐方式 //如果没有属性,在自闭和标签前添加一个空格: <Footer /> //如果可以放在一行,放在一行上即可: <Footer bar="bar" / ...
- js对象使用
以下是js对象使用的两种方式 <script type="text/javascript"> var people = function () { } //方法1 pe ...
- day02-python基础2
操作 列表是用来存储一组数据,可以实现对列表中元素的增删改查等操作. 转换: list(string):把字符串转为列表 声明: 列表使用方括号 查询: 根据元素下标获取列表中元素的值 切片: [0: ...
- .net网站数据抓取
最新项目需要抓取人民币汇率中间价的数据,所以就写了个简单的爬虫抓取数据.抓取的网站为:http://www.safe.gov.cn/wps/portal/sy/tjsj_hlzjj_inquire # ...
- ocrosoft Contest1316 - 信奥编程之路~~~~~第三关 问题 M: 当总统
http://acm.ocrosoft.com/problem.php?cid=1316&pid=12 题目描述 小明想当丑国的总统,丑国大选是按各州的投票结果来确定最终的结果的,如果得到超过 ...