4.DataFrame(快速开始)
快速开始

基本概念
''' 在使用 DataFrame 时,需要了解三个对象上的操作:Collection(DataFrame) ,Sequence,Scalar Collection(DataFrame)表示表结构(或者二维结构) Sequence表示列(一维结构) Scalar表示标量 要注意的是,这些对象仅在使用 Pandas 数据创建后会包含实际数据 而在 ODPS 表上创建的对象中并不包含实际的数据, 而仅仅包含对这些数据的操作,实质的存储和计算会在 ODPS 中进行。 ''' # 创建DataFrame ''' 通常情况下,你唯一需要直接创建的 Collection 对象是 DataFrame,这一对象用于引用数据源 可能是一个 ODPS 表, ODPS 分区,Pandas DataFrame或sqlalchemy.Table(数据库表) 用这几种数据源时,相关的操作相同,这意味着你可以不更改数据处理的代码 仅仅修改输入/输出的指向, 便可以简单地将小数据量上本地测试运行的代码迁移到 ODPS 上, 而迁移的正确性由 PyODPS 来保证。 创建 DataFrame 非常简单,只需将 Table 对象、 pandas DataFrame 对象或者 sqlalchemy Table 对象传入即可。 '''

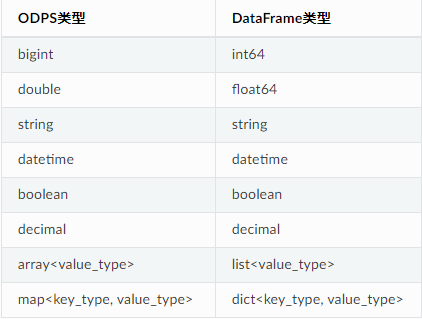
# 列类型 ''' DataFrame包括自己的类型系统,在使用Table初始化的时候,ODPS的类型会被进行转换。 这样做的好处是,能支持更多的计算后端。 目前,DataFrame的执行后端支持ODPS SQL、pandas以及数据库(MySQL和Postgres)。 PyODPS DataFrame 包括以下类型 int8,int16,int32,int64,float32,float64,boolean,string,decimal,datetime,list,dict ODPS的字段和DataFrame的类型映射关系如下: '''
4.DataFrame(快速开始)的更多相关文章
- 今天整理了几个在使用python进行数据分析的常用小技巧、命令。
提高Python数据分析速度的八个小技巧 01 使用Pandas Profiling预览数据 这个神器我们在之前的文章中就详细讲过,使用Pandas Profiling可以在进行数据分析之前对数据进行 ...
- 如何通过Elasticsearch Scroll快速取出数据,构造pandas dataframe — Python多进程实现
首先,python 多线程不能充分利用多核CPU的计算资源(只能共用一个CPU),所以得用多进程.笔者从3.7亿数据的索引,取200多万的数据,从取数据到构造pandas dataframe总共大概用 ...
- Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程 ...
- [大数据之Spark]——快速入门
本篇文档是介绍如何快速使用spark,首先将会介绍下spark在shell中的交互api,然后展示下如何使用java,scala,python等语言编写应用.可以查看编程指南了解更多的内容. 为了良好 ...
- Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN
快速入门 使用 Spark Shell 进行交互式分析 基础 Dataset 上的更多操作 缓存 独立的应用 快速跳转 本教程提供了如何使用 Spark 的快速入门介绍.首先通过运行 Spark 交互 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- pandas.DataFrame学习系列1——定义及属性
定义: DataFrame是二维的.大小可变的.成分混合的.具有标签化坐标轴(行和列)的表数据结构.基于行和列标签进行计算.可以被看作是为序列对象(Series)提供的类似字典的一个容器,是panda ...
- Pandas快速入门笔记
我正以Python作为突破口,入门机器学习相关知识.出于机器学习实践过程中的需要,我快速了解了一下提供了类似关系型或标签型数据结构的Pandas的使用方法.下面记录相关学习笔记. 数据结构 Panda ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
随机推荐
- ASP.NET 使用 MySQL
基本是通用的 C#与MySQL的交互, 先添加MySQL.Data.dll(位于MySQL安装目录下的Connector NET 8.0\Assemblies${version}目录下)引用, 之后代 ...
- 关于原生JS获取class,ID等属性的一些封装
一.传统上获取是通过document.getElementById获取元素的ID属性,通过总结与学习总结一下获取元素class以及id属性的一些封装; 1.创建构造函数,这里面不需要多解释什么:(主要 ...
- 一、MySQL数据库之简介和安装
一.基础部分 1.数据库是简介 之前所学,数据要永久保存,比如用户注册的用户信息,都是保存于文件中,而文件只能存在于某一台机器上. 如果我们不考虑从文件中读取数据的效率问题,并且假设我们的程序 ...
- sql中给逗号分隔的查询结果替换单引号
技术交流群:233513714 第一种方法: SELECT * FROM pay_inf_config a WHERE a.id IN ( SELECT REPLACE ( concat('''', ...
- 抓包工具 - Fiddler - (三)
<转载自 miantest> 我们知道Fiddler是位于客户端和服务器之间的代理,它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据.设置断点.调 ...
- docker部署思路
1.docker安装2.拉取centos镜像或者Ubuntu镜像 看你用哪个3.使用镜像,run出来一个容器A4.进入容器A,安装uwsgi,把Django部署在下面5.在启动脚本中配置开机自启动脚本 ...
- CodeForces-1061D TV Shows
题目链接 https://vjudge.net/problem/CodeForces-1061D 题面 Description There are nn TV shows you want to wa ...
- 聊聊、Mybatis XML
引入相应的依赖包 <dependency><groupId>org.mybatis</groupId><artifactId>mybatis-sprin ...
- Elasticsearch自定义分析器
关于分析器 ES中默认使用的是标准分析器(standard analyzer).如果需要对某个字段使用其他分析器,可以在映射中该字段下说明.例如: PUT /my_index { "mapp ...
- python XlsxWriter创建Excel 表格
文档(英文) https://xlsxwriter.readthedocs.io/index.html 常用模块说明(中文) https://blog.csdn.net/sinat_35930259/ ...