Pandas 数据分析——超好用的 Groupby 详解
在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像(性别、年龄)进行细分,研究用户的使用情况和偏好等。在 Pandas 中,上述的数据处理操作主要运用 groupby 完成,这篇文章就介绍一下 groupby 的基本原理及对应的 agg、transform 和 apply 操作。
PS:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步!
为了后续图解的方便,采用模拟生成的 10 个样本数据,代码和数据如下:
company=["A","B","C"]
data=pd.DataFrame({
"company":[company[x] for x in np.random.randint(0,len(company),10)],
"salary":np.random.randint(5,50,10),
"age":np.random.randint(15,50,10)
}
)| company | salary | age | |
|---|---|---|---|
| 0 | C | 43 | 35 |
| 1 | C | 17 | 25 |
| 2 | C | 8 | 30 |
| 3 | A | 20 | 22 |
| 4 | B | 10 | 17 |
| 5 | B | 21 | 40 |
| 6 | A | 23 | 33 |
| 7 | C | 49 | 19 |
| 8 | B | 8 | 30 |
一、Groupby 的基本原理
在 pandas 中,实现分组操作的代码很简单,仅需一行代码,在这里,将上面的数据集按照 company 字段进行划分:
In [5]: group = data.groupby("company")将上述代码输入 ipython 后,会得到一个 DataFrameGroupBy 对象
In [6]: group
Out[6]: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002B7E2650240>那这个生成的 DataFrameGroupBy 是啥呢?对 data 进行了 groupby 后发生了什么?ipython 所返回的结果是其内存地址,并不利于直观地理解,为了看看 group 内部究竟是什么,这里把 group 转换成 list 的形式来看一看:
In [8]: list(group)
Out[8]:
[('A', company salary age
3 A 20 22
6 A 23 33),
('B', company salary age
4 B 10 17
5 B 21 40
8 B 8 30),
('C', company salary age
0 C 43 35
1 C 17 25
2 C 8 30
7 C 49 19)]转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照 company 进行分组,所以最后分为了 A,B,C),第二个元素的是对应组别下的 DataFrame,整个过程可以图解如下:
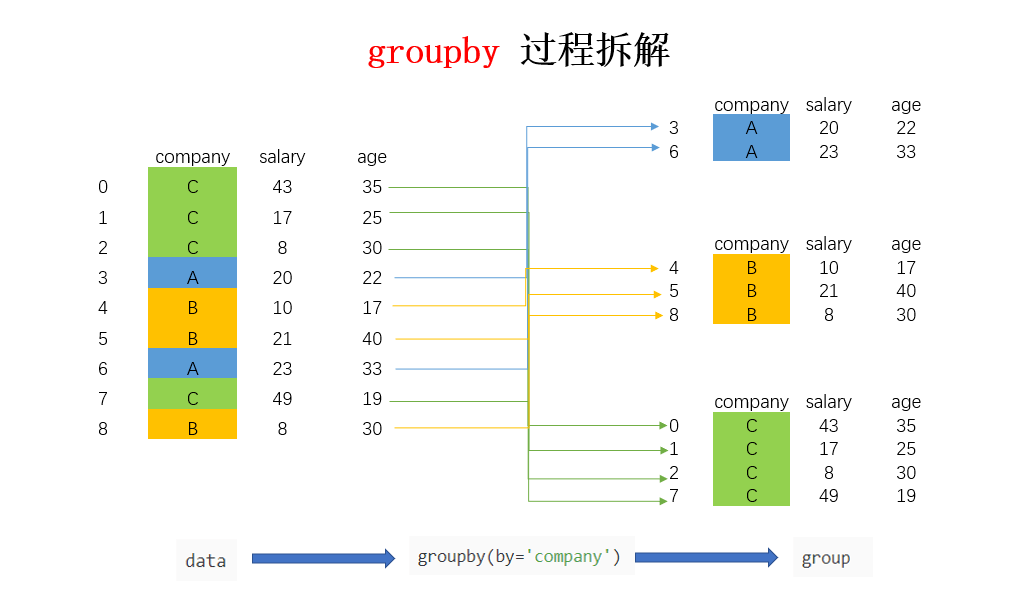
总结来说,groupby 的过程就是将原有的 DataFrame 按照 groupby 的字段(这里是 company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在 groupby 之后的一系列操作(如 agg、apply 等),均是基于子DataFrame 的操作。理解了这点,也就基本摸清了 Pandas 中 groupby 操作的主要原理。下面来讲讲 groupby 之后的常见操作。
二、agg 聚合操作
聚合操作是 groupby 后非常常见的操作,会写 SQL 的朋友对此应该是非常熟悉了。聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了 Pandas 中常见的聚合操作。
| 函数 | 用途 |
|---|---|
| min | 最小值 |
| max | 最大值 |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| std | 标准差 |
| var | 方差 |
| count | 计数 |
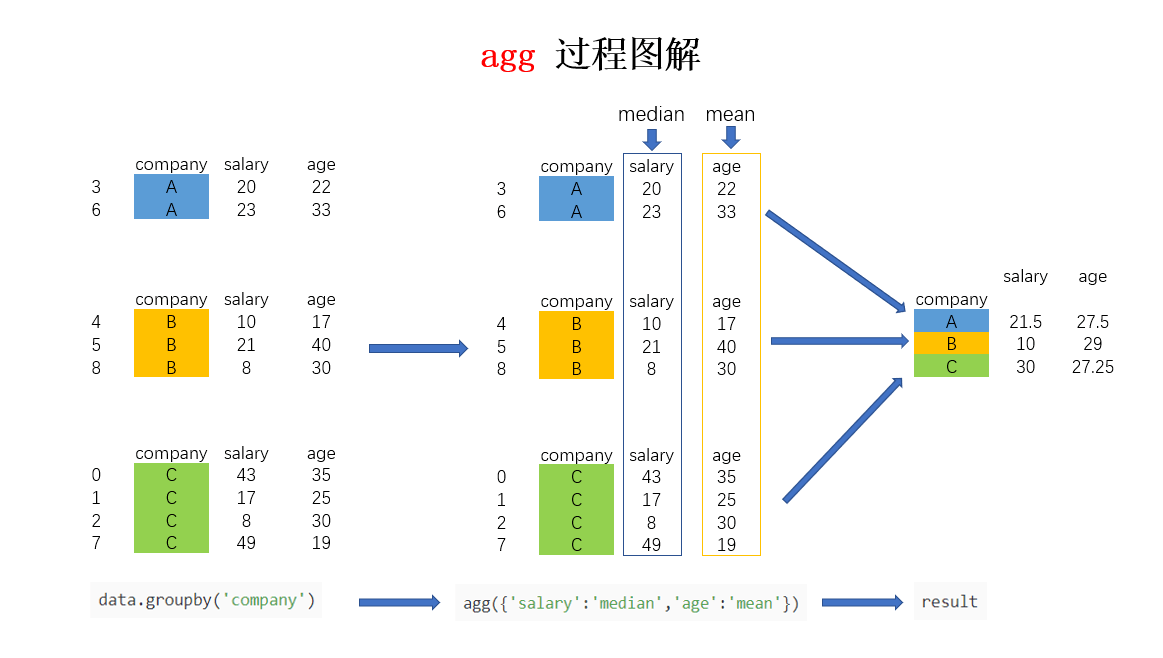
针对样例数据集,如果我想求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
In [12]: data.groupby("company").agg('mean')
Out[12]:
salary age
company
A 21.50 27.50
B 13.00 29.00
C 29.25 27.25如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定:
In [17]: data.groupby('company').agg({'salary':'median','age':'mean'})
Out[17]:
salary age
company
A 21.5 27.50
B 10.0 29.00
C 30.0 27.25agg 聚合过程可以图解如下(第二个例子为例):
三、transform
transform 是一种什么数据操作?和 agg 有什么区别呢?为了更好地理解 transform 和 agg 的不同,下面从实际的应用场景出发进行对比。
在上面的 agg 中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列 avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用 transform 的话,实现代码如下:
In [21]: avg_salary_dict = data.groupby('company')['salary'].mean().to_dict()
In [22]: data['avg_salary'] = data['company'].map(avg_salary_dict)
In [23]: data
Out[23]:
company salary age avg_salary
0 C 43 35 29.25
1 C 17 25 29.25
2 C 8 30 29.25
3 A 20 22 21.50
4 B 10 17 13.00
5 B 21 40 13.00
6 A 23 33 21.50
7 C 49 19 29.25
8 B 8 30 13.00如果使用 transform 的话,仅需要一行代码:
In [24]: data['avg_salary'] = data.groupby('company')['salary'].transform('mean')
In [25]: data
Out[25]:
company salary age avg_salary
0 C 43 35 29.25
1 C 17 25 29.25
2 C 8 30 29.25
3 A 20 22 21.50
4 B 10 17 13.00
5 B 21 40 13.00
6 A 23 33 21.50
7 C 49 19 29.25
8 B 8 30 13.00还是以图解的方式来看看进行 groupby 后 transform 的实现过程(为了更直观展示,图中加入了 company列,实际按照上面的代码只有 salary 列):
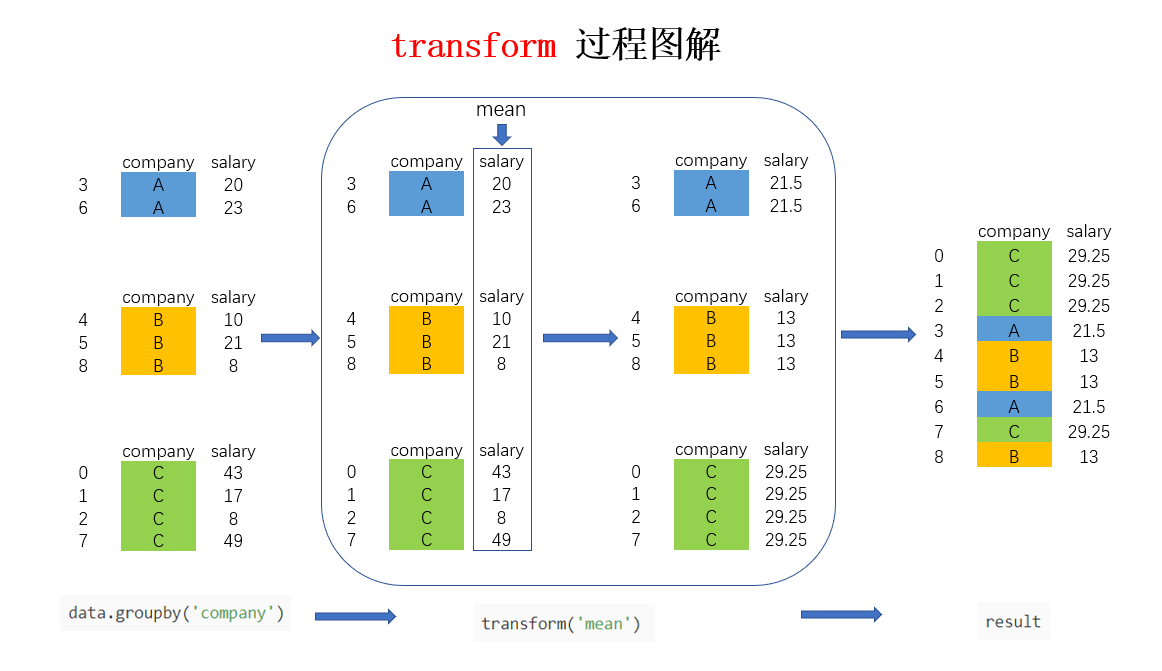
图中的大方框是 transform 和 agg 所不一样的地方,对 agg 而言,会计算得到 A,B,C 公司对应的均值并直接返回,但对 transform 而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果,如果有不理解的可以拿这张图和 agg 那张对比一下。
四、apply
apply 应该是大家的老朋友了,它相比 agg 和 transform 而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作。在 Pandas 数据处理三板斧 ——map、apply、applymap 详解
) 中,介绍了 apply 的使用,那在 groupby 后使用 apply 和之前所介绍的有什么区别呢?
区别是有的,但是整个实现原理是基本一致的。两者的区别在于,对于 groupby 后的 apply,以分组后的子DataFrame 作为参数传入指定函数的,基本操作单位是 DataFrame,而之前介绍的 apply 的基本操作单位是 Series。还是以一个案例来介绍 groupby 后的 apply 用法。
假设我现在需要获取各个公司年龄最大的员工的数据,该怎么实现呢?可以用以下代码实现:
In [38]: def get_oldest_staff(x):
...: df = x.sort_values(by = 'age',ascending=True)
...: return df.iloc[-1,:]
...:
In [39]: oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff)
In [40]: oldest_staff
Out[40]:
company salary age
0 A 23 33
1 B 21 40
2 C 43 35 这样便得到了每个公司年龄最大的员工的数据,整个流程图解如下:
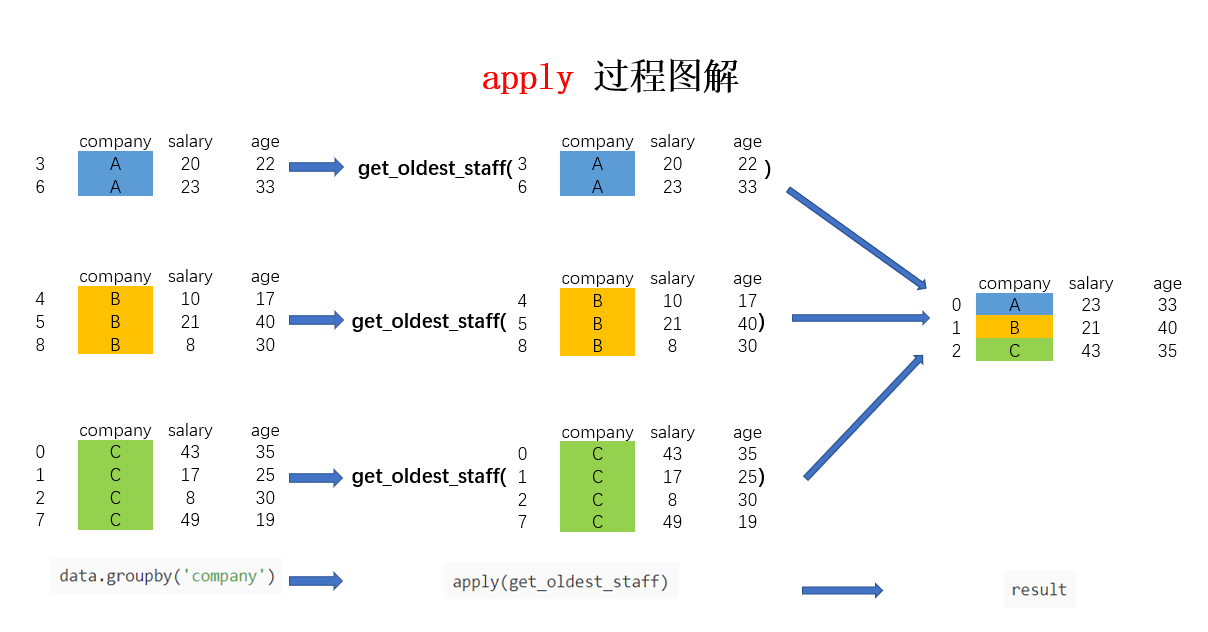
可以看到,此处的 apply 和上篇文章中所介绍的作用原理基本一致,只是传入函数的参数由 Series 变为了此处的分组DataFrame。
最后,关于 apply 的使用,这里有个小建议,虽然说 apply 拥有更大的灵活性,但 apply 的运行效率会比 agg 和 transform 更慢。所以,groupby 之后能用 agg 和 transform 解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用 apply 进行操作。
总结:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
Pandas 数据分析——超好用的 Groupby 详解的更多相关文章
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
- Pandas系列(十二)-可视化详解
目录 1. 折线图 2. 柱状图 3. 直方图 4. 箱线图 5. 区域图 6. 散点图 7. 饼图六边形容器图 数据分析的结果不仅仅只是你来看的,更多的时候是给需求方或者老板来看的,为了更直观地看出 ...
- Pandas系列(十)-转换连接详解
目录 1. 拼接 1.1 append 1.2 concat 2. 关联 2.1 merge 2.2 join 数据准备 # 导入相关库 import numpy as np import panda ...
- Oracle数据库的安装 【超详细的文图详解】
Oracle简介Oracle Database,又名Oracle RDBMS,或简称Oracle.是甲骨文公司的一款关系数据库管理系统.它是在数据库领域一直处于领先地位的产品.可以说Oracle数据库 ...
- 超全MyBatis动态SQL详解!( 看完SQL爽多了)
MyBatis 令人喜欢的一大特性就是动态 SQL. 在使用 JDBC 的过程中, 根据条件进行 SQL 的拼接是很麻烦且很容易出错的. MyBatis 动态 SQL 的出现, 解决了这个麻烦. My ...
- 超详细的Hadoop2配置详解
1. 集群环境 Master 192.168.2.100 Slave1 192.168.2.101 Slave2 192.168.2.102 2. 下载安装包 Master wget http://m ...
- Pandas进阶笔记 (一) Groupby 重难点总结
如果Pandas只是能把一些数据变成 dataframe 这样优美的格式,那么Pandas绝不会成为叱咤风云的数据分析中心组件.因为在数据分析过程中,描述数据是通过一些列的统计指标实现的,分析结果也需 ...
- 【python】详解numpy库与pandas库axis=0,axis= 1轴的用法
对数据进行操作时,经常需要在横轴方向或者数轴方向对数据进行操作,这时需要设定参数axis的值: axis = 0 代表对横轴操作,也就是第0轴: axis = 1 代表对纵轴操作,也就是第1轴: nu ...
- 学机器学习,不会数据处理怎么行?—— 二、Pandas详解
在上篇文章学机器学习,不会数据处理怎么行?—— 一.NumPy详解中,介绍了NumPy的一些基本内容,以及使用方法,在这篇文章中,将接着介绍另一模块——Pandas.(本文所用代码在这里) Panda ...
随机推荐
- H5_0019:JS中定义json结构
"7HKm": function(e, a, d) { "use strict"; Object ...
- 500kuai
https://www.bilibili.com/bangumi/media/md11653495/?spm_id_from=666.10.b_62616e67756d695f64657461696c ...
- C++ -> 在使用动态链表和异质链表产生野指针的步骤
C++ -> 在使用动态链表和异质链表产生野指针的步骤 使用异质链表产生野指针的情况,下面是修改书本的例子: ------------------------------------------ ...
- linux下载phantomjs记录
step1:建目录: cd /root mkdir PhantomJS step2:下载phantomjs安装包 可以直接进网址下载到本地后,再传到linux路径,例如phantomjs-1.9.7- ...
- 22.01.Cluster
1. 클러스터링 iris 데이터셋 확인¶ In [2]: from sklearn import cluster from sklearn import datasets iris = dat ...
- 一步步教你如何在Ubuntu虚拟机中安装QEMU并模拟模拟arm 开发环境(一)uImage u-boot(转)
初次接触qemu是因为工作的需要,有时候下了班,可能需要在家研究一些东西,因为博主用到arm环境,这时候博主比较小气,不愿花钱买开发板,当然博主在这里给大家的建议是,如果要真正学懂arm构架的相关知识 ...
- 主从分离之SSM与Mysql
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够.到了数据业务层.数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢 ...
- Codeforces1295D. Same GCDs (欧拉函数)
https://codeforces.com/contest/1295/problem/D 设gcd(a,m)= n,那么找gcd(a +x ,m)= n个数,其实就等于找gcd((a+x)/n,m/ ...
- 腾讯云OCR图片文字识别
一. OCR OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别 ...
- 在vue中使用swiper4.x
需求 :实现一个左右两边有边距的轮播图vue+swiper4 轮播图左右两边含有上一张和下一张的一部分 先安装swiper: 1.npm install swiper 安装swiper 2.在入口 ...