Spark学习之路 (四)Spark的广播变量和累加器[转]
概述
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
广播变量broadcast variable
为什么要将变量定义成广播变量?
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
广播变量图解
错误的,不使用广播变量
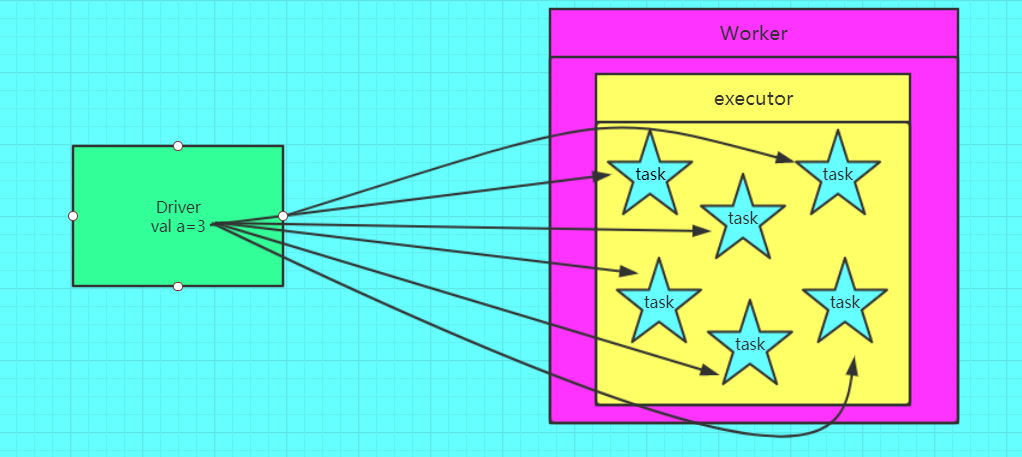
正确的,使用广播变量的情况

如何定义一个广播变量?
val a = 3
val broadcast = sc.broadcast(a)如何还原一个广播变量?
val c = broadcast.value定义广播变量需要的注意点?
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
注意事项
- 能不能将一个RDD使用广播变量广播出去?不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
- 广播变量只能在Driver端定义,不能在Executor端定义。
- 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
- 如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
- 如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
累加器
为什么要将一个变量定义为一个累加器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
图解累加器
错误的图解

正确的图解

如何定义一个累加器?
val a = sc.accumulator(0)如何还原一个累加器?
val b = a.value注意事项
- 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
- 累加器不是一个调优的操作,因为如果不这样做,结果是错的
Spark学习之路 (四)Spark的广播变量和累加器[转]的更多相关文章
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- SparkCore | Rdd| 广播变量和累加器
Spark中三大数据结构:RDD: 广播变量: 分布式只读共享变量: 累加器:分布式只写共享变量: 线程和进程之间 1.RDD中的函数传递 自己定义一些RDD的操作,那么此时需要主要的是,初始化工作 ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
随机推荐
- php扩展模块的安装
PHP的扩展模块安装 模块安装总则: 进入到ext/目录下对应的模块 执行/usr/local/php/bin/phpize 也就是执行一遍phpize生成编译文件 ./configure --wit ...
- Go语言实现:【剑指offer】左旋转字符串
该题目来源于牛客网<剑指offer>专题. 汇编语言中有一种移位指令叫做循环左移(ROL),现在有个简单的任务,就是用字符串模拟这个指令的运算结果.对于一个给定的字符序列S,请你把其循环左 ...
- Thread类的interrupted方法和isInterrupted方法的区别
如下所示,interrupted()会改变线程的中断状态(清除),而isInterrupted()不影响线程的中断状态 /** * Tests whether the current thread ...
- Vue项目使用vant框架
近期在开发h5端项目,用到vant框架,vant是一款基于Vue的移动UI组件,看了vant的官方文档(https://youzan.github.io/vant/#/zh-CN/)感觉不错,功能比较 ...
- php 搭建webSocket
<?php //2.设计一个循环挂起WebSocket通道,进行数据的接收.处理和发送 //对创建的socket循环进行监听,处理数据 function run(){ //死循环,直到socke ...
- 【转】Android之四大组件、六大布局、五大存储
文章来自:http://blog.csdn.net/shenggaofei/article/details/52450668 一.四大组件: Android四大组件分别为activity.servic ...
- Aliyun搭建svn服务器外网访问报错权限配置失败错误
搭建完后所有的配置如下 [root@iZuf655czz7lmtn8v15tsjZ conf]# pwd /home/SVN/conf [root@iZuf655czz7lmtn8v15tsjZ co ...
- Win环境下安装vue及运行vue开发的前端项目
vue安装及配置 首先下载node.js要求版本在8.9以上 官网:https://nodejs.org/zh-cn/ 下载完可检查在windows任务命令行里输入node -v 使用淘 ...
- python笔记23(面向对象课程五)
今日内容 上节作业 单例模式 class Foo: pass obj1 = Foo() # 实例,对象 obj2 = Foo() # 实例,对象 日志模块(logging) 程序的目录结构 内容回顾 ...
- linux 查看系统资源使用信息的一些命令集合
linux上的进程查看及管理工具: pstree,ps,pidof,pgrep,top,htop,glances,pmap,vmstat,dstat,kill,pkill,job,bg,fg,nohu ...