在 Node.js 中引入模块:你所需要知道的一切都在这里

本文作者:Jacob Beltran
编译:胡子大哈翻译原文:http://huziketang.com/blog/posts/detail?postId=58eaf471a58c240ae35bb8e3
英文连接:Requiring modules in Node.js: Everything you need to know
Node 中有两个核心模块来对模块依赖进行管理:
require模块。全局范围生效,不需要require('require')。module模块。全局范围生效,不需要require('module')。
你可以把 require 当做是命令行,而把 module 当做是所有引入模块的组织者。
在 Node 中引入模块并不是什么复杂的概念,见下面例子:
const config = require('/path/to/file');
require 引入的对象主要是函数。当 Node 调用 require() 函数,并且传递一个文件路径给它的时候,Node 会经历如下几个步骤:
- Resolving:找到文件的绝对路径;
- Loading:判断文件内容类型;
- Wrapping:打包,给这个文件赋予一个私有作用范围。这是使
require和module模块在本地引用的一种方法; - Evaluating:VM 对加载的代码进行处理的地方;
- Caching:当再次需要用这个文件的时候,不需要重复一遍上面步骤。
本文中,我会用不同的例子来解释上面的各个步骤,并且介绍在 Node 中它们对我们写的模块有什么样的影响。
为了方便大家看文章和理解命令,我首先创建一个目录,后面的操作都会在这个目录中进行。
mkdir ~/learn-node && cd ~/learn-node
文章中接下来的部分都会在 ~/learn-node 文件夹下运行。
1. Resolving - 解析本地路径
首先来为你介绍 module 对象,可以先在控制台中看一下:
~/learn-node $ node
> module
Module {
id: '<repl>',
exports: {},
parent: undefined,
filename: null,
loaded: false,
children: [],
paths: [ ... ] }
每一个模块都有 id 属性来唯一标示它。id 通常是文件的完整路径,但是在控制台中一般显示成<repl>。
Node 模块和文件系统中的文件通常是一一对应的,引入一个模块需要把文件内容加载到内存中。因为 Node 有很多种方法引入一个文件(例如相对路径,或者提前配置好的路径),所以首先需要找到文件的绝对路径。
如果我引入了一个 'find-me' 模块,并没有指定它的路径的话:
require('find-me');
Node 会按照 module.paths 所指定的文件目录顺序依次寻找 find-me.js。
~/learn-node $ node
> module.paths
[ '/Users/samer/learn-node/repl/node_modules',
'/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules',
'/Users/samer/.node_modules',
'/Users/samer/.node_libraries',
'/usr/local/Cellar/node/7.7.1/lib/node' ]
这个路径列表基本上包含了从当前目录到根目录的所有路径中的 node_modules 目录。其中还包含了一些不建议使用的遗留目录。如果 Node 在上面所有的目录中都没有找到 find-me.js,会抛出一个“cannot find module error.”错误。
~/learn-node $ node
> require('find-me')
Error: Cannot find module 'find-me'
at Function.Module._resolveFilename (module.js:470:15)
at Function.Module._load (module.js:418:25)
at Module.require (module.js:498:17)
at require (internal/module.js:20:19)
at repl:1:1
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)
如果现在创建一个 node_modules,并把 find-me.js 放进去,那么 require('find-me') 就能找到了。
~/learn-node $ mkdir node_modules
~/learn-node $ echo "console.log('I am not lost');" > node_modules/find-me.js
~/learn-node $ node
> require('find-me');
I am not lost
{}
>
假设还有另一个目录中存在 find-me.js,例如在 home/node_modules 目录中有另一个 find-me.js 文件。
$ mkdir ~/node_modules
$ echo "console.log('I am the root of all problems');" > ~/node_modules/find-me.js
当我们从 learn-node 目录中执行 require('find-me') 的时候,由于 learn-node 有自己的node_modules/find-me.js,这时不会加载 home 目录下的 find-me.js:
~/learn-node $ node
> require('find-me')
I am not lost
{}
>
假设我们把 learn-node 目录下的 node_modules 移到 ~/learn-node,再重新执行require('find-me') 的话,按照上面规定的顺序查找文件,这时候 home 目录下的 node_modules 就会被使用了。
~/learn-node $ rm -r node_modules/
~/learn-node $ node
> require('find-me')
I am the root of all problems
{}
>
require 一个文件夹
模块不一定非要是文件,也可以是个文件夹。我们可以在 node_modules 中创建一个 find-me 文件夹,并且放一个 index.js 文件在其中。那么执行 require('find-me') 将会使用 index.js 文件:
~/learn-node $ mkdir -p node_modules/find-me
~/learn-node $ echo "console.log('Found again.');" > node_modules/find-me/index.js
~/learn-node $ node
> require('find-me');
Found again.
{}
>
这里注意,我们本目录下创建了 node_modules 文件夹,就不会使用 home 目录下的 node_modules 了。
当引入一个文件夹的时候,默认会去找 index.js 文件,这也可以手动控制指定到其他文件,利用package.json 的 main 属性就可以。例如,我们执行 require('find-me'),并且要从 find-me文件夹下的 start.js 文件开始解析,那么用 package.json 的做法如下:
~/learn-node $ echo "console.log('I rule');" > node_modules/find-me/start.js
~/learn-node $ echo '{ "name": "find-me-folder", "main": "start.js" }' > node_modules/find-me/package.json
~/learn-node $ node
> require('find-me');
I rule
{}
>
require.resolve
如果你只是想解析模块,而不执行的话,可以使用 require.resolve 函数。它和主 require 函数所做的事情一模一样,除了不加载文件。当没找到文件的时候也会抛出错误,如果找到会返回文件的完整路径。
> require.resolve('find-me');
'/Users/samer/learn-node/node_modules/find-me/start.js'
> require.resolve('not-there');
Error: Cannot find module 'not-there'
at Function.Module._resolveFilename (module.js:470:15)
at Function.resolve (internal/module.js:27:19)
at repl:1:9
at ContextifyScript.Script.runInThisContext (vm.js:23:33)
at REPLServer.defaultEval (repl.js:336:29)
at bound (domain.js:280:14)
at REPLServer.runBound [as eval] (domain.js:293:12)
at REPLServer.onLine (repl.js:533:10)
at emitOne (events.js:101:20)
at REPLServer.emit (events.js:191:7)
>
它可以用于检查一个包是否已经安装,只有当包存在的时候才使用该包。
相对路径和绝对路径
除了可以把模块放在 node_modules 目录中,还有更自由的方法。我们可以把模块放在任何地方,然后通过相对路径(./ 和 ../)或者绝对路径(/)来指定文件路径。
例如 find-me.js 文件是在 lib 目录下,而不是在 node_modules 下,我们可以这样引入:
require('./lib/find-me');
文件的 parent-child 关系
创建一个文件 lib/util.js 并且写一行 console.log 在里面来标识它,当然,这个 console.log 就是模块本身。
~/learn-node $ mkdir lib
~/learn-node $ echo "console.log('In util', module);" > lib/util.js
在 index.js 中写上将要执行的 node 命令,并且在 index.js 中引入 lib/util.js:
~/learn-node $ echo "console.log('In index', module); require('./lib/util');" > index.js
现在在 node 中执行 index.js:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [],
paths: [ ... ] }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: {},
parent:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: false,
children: [ [Circular] ],
paths: [...] },
filename: '/Users/samer/learn-node/lib/util.js',
loaded: false,
children: [],
paths: [...] }
注意到这里,index 模块(id:'.')被列到了 lib/util 的 parent 属性中。而 lib/util 并没有被列到 index 的 children 属性,而是用一个 [Circular] 代替的。这是因为这是个循环引用,如果这里使用 lib/util 的话,那就变成一个无限循环了。这就是为什么在 index 中使用 [Circular] 来替代lib/util。
那么重点来了,如果在 lib/util 中引入了 index 模块会怎么样?这就是我们所谓的模块循环依赖问题,在 Node 中是允许这样做的。
但是 Node 如何处理这种情况呢?为了更好地理解这一问题,我们先来了解一下模块对象的其他知识。
2. Loading - exports,module.exports,和模块的同步加载
在所有的模块中,exports 都是一个特殊的对象。如果你有注意的话,上面我们每次打印模块信息的时候,都有一个是空值的 exports 属性。我们可以给这个 exports 对象加任何想加的属性,例如在 index.js 和lib/util.js 中给它添加一个 id 属性:
// 在 lib/util.js 的最上面添加这行
exports.id = 'lib/util';
// 在 index.js 的最上面添加这行
exports.id = 'index';
执行 index.js,可以看到我们添加的属性已经存在于模块对象中:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... }
In util Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: { id: 'lib/util' },
parent:
Module {
id: '.',
exports: { id: 'index' },
loaded: false,
... },
loaded: false,
... }
上面为了输出结果简洁,我删掉了一些属性。你可以往 exports 对象中添加任意多的属性,甚至可以把 exports 对象变成其他类型,比如把 exports 对象变成函数,做法如下:
// 在 index.js 的 console.log 前面添加这行
module.exports = function() {};
当你执行 index.js 的时候,你会看到如下信息:
~/learn-node $ node index.js
In index Module {
id: '.',
exports: [Function],
loaded: false,
... }
这里注意我们没有使用 export = function() {} 来改变 exports 对象。没有这样做是因为在模块中的exports 变量实际上是 module.exports 的一个引用,而 module.exports 才是控制所有对外属性的。exports 和 module.exports 指向同一块内存,如果把 exports 指向一个函数,那么相当于改变了 exports 的指向,exports 就不再是引用了。即便你改变了 exports,module.exports 也是不变的。
模块的 module.exports 是一个模块的对外接口,就是当你使用 require 函数时所返回的东西。例如把index.js 中的代码改一下:
const UTIL = require('./lib/util');
console.log('UTIL:', UTIL);
上面的代码将会捕获 lib/util 中输出的属性,赋值给 UTIL 常量。当执行 index.js 的时候,最后一行将会输出:
UTIL: { id: 'lib/util' }
接下来聊一下 loaded 属性。上面我们每次输出模块信息,都能看到一个 loaded 属性,值是 false。
module 模块使用 loaded 属性来追踪哪些模块已经加载完毕,哪些模块正在加载。例如我们可以调用setImmediate 来打印 module 对象,用它可以看到 index.js 的完全加载信息:
// In index.js
setImmediate(() => {
console.log('The index.js module object is now loaded!', module)
});
输出结果:
The index.js module object is now loaded! Module {
id: '.',
exports: [Function],
parent: null,
filename: '/Users/samer/learn-node/index.js',
loaded: true,
children:
[ Module {
id: '/Users/samer/learn-node/lib/util.js',
exports: [Object],
parent: [Circular],
filename: '/Users/samer/learn-node/lib/util.js',
loaded: true,
children: [],
paths: [Object] } ],
paths:
[ '/Users/samer/learn-node/node_modules',
'/Users/samer/node_modules',
'/Users/node_modules',
'/node_modules' ] }
可以注意到 lib/util.js 和 index.js 都已经加载完毕了。
当一个模块加载完成的时候,exports 对象才完整,整个加载的过程都是同步的。这也是为什么在一个事件循环后所有的模块都处于完全加载状态的原因。
这也意味着不能异步改变 exports 对象,例如,对任何模块做下面这样的事情:
fs.readFile('/etc/passwd', (err, data) => {
if (err) throw err;
exports.data = data; // Will not work.
});
模块循环依赖
我们现在来回答上面说到的循环依赖的问题:模块 1 依赖模块 2,模块 2 也依赖模块 1,会发生什么?
现在来创建两个文件,lib/module1.js 和 lib/module2.js,并且让它们相互引用:
// lib/module1.js
exports.a = 1;
require('./module2');
exports.b = 2;
exports.c = 3;
// lib/module2.js
const Module1 = require('./module1');
console.log('Module1 is partially loaded here', Module1);
接下来执行 module1.js,可以看到:
~/learn-node $ node lib/module1.js
Module1 is partially loaded here { a: 1 }
在 module1 完全加载之前需要先加载 module2,而 module2 的加载又需要 module1。这种状态下,我们从 exports 对象中能得到的就是在发生循环依赖之前的这部分。上面代码中,只有 a 属性被引入,因为 b 和 c 都需要在引入 module2 之后才能加载进来。
Node 使这个问题简单化,在一个模块加载期间开始创建 exports 对象。如果它需要引入其他模块,并且有循环依赖,那么只能部分引入,也就是只能引入发生循环依赖之前所定义的这部分。
JSON 和 C/C++ 扩展文件
我们可以使用 require 函数本地引入 JSON 文件和 C++ 扩展文件,理论上来讲,不需要指定其扩展名。
如果没有指定扩展名,Node 会先尝试将其按 .js 文件来解析,如果不是 .js 文件,再尝试按 .json 文件来解析。如果都不是,会尝试按 .node 二进制文件解析。但是为了使程序更清晰,当引入除了 .js 文件的时候,你都应该指定文件扩展名。
如果你要操作的文件是一些静态配置值,或者是需要定期从外部文件中读取的值,那么引入 JSON 是很好的一个选择。例如有如下的 config.json 文件:
{
"host": "localhost",
"port": 8080
}
我们可以直接像这样引用:
const { host, port } = require('./config');
console.log(`Server will run at http://${host}:${port}`);
运行上面的代码会得到这样的输出:
Server will run at http://localhost:8080
如果 Node 按 .js 和 .json 解析都失败的话,它会按 .node 解析,把这个文件当做一个已编译的扩展模块来解析。
Node 文档中有一个 C++ 写的示例扩展文件,它只暴露出一个 hello() 函数,并且函数输出 “world”。
你可以使用 node-gyp 包编译 .cc 文件,生成 .addon 文件。只需要配置 binding.gyp 文件来告诉node-gyp 需要做什么就可以了。
当你有了 addon.node 文件(名字你可以在 binding.gyp 中随意配置)以后,你就可以在本地像引入其他模块一样引入它了:
const addon = require('./addon');
console.log(addon.hello());
可以通过 require.extensions 来查看对三种文件的支持情况:
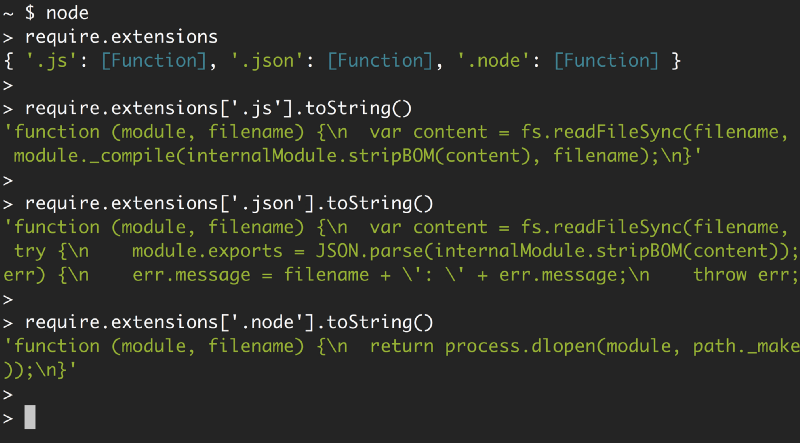
可以清晰地看到 Node 对每种扩展名所使用的函数及其操作:对 .js 文件使用 module._compile;对.json 文件使用 JSON.parse;对 .node 文件使用 process.dlopen。
3. Wrapping - 你在 Node 中所写的所有代码都会被打包成函数
Node 的打包模块不是很好理解,首先要先知道 exports / module.exports 的关系。
我们可以用 exports 对象来输出属性,但是不能直接对 exports 进行赋值(替换整个 exports 对象),因为它仅仅是 module.exports 的引用。
exports.id = 42; // This is ok.
exports = { id: 42 }; // This will not work.
module.exports = { id: 42 }; // This is ok.
在介绍 Node 的打包过程之前先来了解另一个问题,通常情况下,在浏览器中我们在脚本中定义一个变量:
var answer = 42;
这种方式定义以后,answer 变量就是一个全局变量了。其他脚本中依然可以访问。而 Node 中不是这样,你在一个模块中定义一个变量,程序的其他模块是不能访问的。Node 是如何做到的呢?
答案很简单,在编译成模块之前,Node 把模块代码都打包成函数,可以用 module 的 wrapper 属性来查看。
~ $ node
> require('module').wrapper
[ '(function (exports, require, module, __filename, __dirname) { ',
'\n});' ]
>
Node 并不直接执行你所写的代码,而是把你的代码打包成函数后,执行这个函数。这就是为什么一个模块的顶层变量的作用域依然仅限于本模块的原因。
这个打包函数有 5 个参数:exports,require,module,__filename,__dirname。函数使变量看起来全局生效,但实际上只在模块内生效。所有的这些参数都在 Node 执行函数时赋值。exports 定义成module.exports 的引用;require 和 module 都指定为将要执行的这个函数;__filename 和__dirname 指这个打包模块的绝对路径和目录路径。
在脚本的第一行输入有问题的代码,就能看到 Node 打包的行为;
~/learn-node $ echo "euaohseu" > bad.js
~/learn-node $ node bad.js
~/bad.js:1
(function (exports, require, module, __filename, __dirname) { euaohseu
^
ReferenceError: euaohseu is not defined
注意这里报告出错误的就是打包函数。
另外,模块都打包成函数了,我们可以使用 arguments 关键字来访问函数的参数:
~/learn-node $ echo "console.log(arguments)" > index.js
~/learn-node $ node index.js
{ '0': {},
'1':
{ [Function: require]
resolve: [Function: resolve],
main:
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [Object] },
extensions: { ... },
cache: { '/Users/samer/index.js': [Object] } },
'2':
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/samer/index.js',
loaded: false,
children: [],
paths: [ ... ] },
'3': '/Users/samer/index.js',
'4': '/Users/samer' }
第一个参数是 exports 对象,初始为空;require 和 module 对象都是即将执行的 index.js 的实例;最后两个参数是文件路径和目录路径。
打包函数的返回值是 module.exports。在模块内部,可以使用 exports 对象来改变 module.exports属性,但是不能对 exports 重新赋值,因为它只是 module.exports 的引用。
相当于如下代码:
function (require, module, __filename, __dirname) {
let exports = module.exports;
// Your Code...
return module.exports;
}
如果对 exports 重新赋值(改变整个 exports 对象),那它就不是 module.exports 的引用了。这是 JavaScript 引用的工作原理,不仅仅是在这里是这样。
4. Evaluating - require 对象
require 没有什么特别的,通常作为一个函数返回 module.exports 对象,函数参数是一个模块名或者一个路径。如果你想的话,尽可以根据自己的逻辑重写 require 对象。
例如,为了达到测试的目的,我们希望所有的 require 都默认返回一个 mock 值来替代真实的模块返回值。可以简单地实现如下:
require = function() {
return { mocked: true };
}
这样重写了 require 以后,每个 require('something') 调用都会返回一个模拟对象。
require 对象也有自己的属性。上面已经见过了 resolve 属性,它的任务是处理引入模块过程中的解析步骤,上面还提到过 require.extensions 也是 require 的属性。还有 require.main,它用于判断一个脚本是否应该被引入还是直接执行。
例如,在 print-in-frame.js 中有一个 printInFrame 函数。
// In print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};
函数有两个参数,一个是数字类型参数 size,一个是字符串类型参数 header。函数功能很简单,这里不赘述。
我们想用两种方式使用这个文件:
1.直接使用命令行:
~/learn-node $ node print-in-frame 8 Hello
传递 8 和 “Hello” 两个参数进去,打印 8 个星星包裹下的 “Hello”。
2.使用 require。假设所引入的模块对外接口是 printInFrame 函数,我们可以这样调用:
const print = require('./print-in-frame');
print(5, 'Hey');
传递的参数是 5 和 “Hey”。
这是两种不同的用法,我们需要一种方法来判断这个文件是作为独立的脚本来运行,还是需要被引入到其他的脚本中才能执行。可以使用简单的 if 语句来实现:
if (require.main === module) {
// 这个文件直接执行(不需要 require)
}
继续演化,可以使用不同的调用方式来实现最初的需求:
// In print-in-frame.js
const printInFrame = (size, header) => {
console.log('*'.repeat(size));
console.log(header);
console.log('*'.repeat(size));
};
if (require.main === module) {
printInFrame(process.argv[2], process.argv[3]);
} else {
module.exports = printInFrame;
}
当文件不需要被 require 时,直接通过 process.argv 调用 printInFrame 函数即可。否则直接把module.exports 变成 printInFrame 就可以了,即模块接口是 printInFrame。
5. Caching - 所有的模块都会被缓存
对缓存的理解特别重要,我用简单的例子来解释缓存。
假设你有一个 ascii-art.js 文件,打印很酷的 header:

我们想要在每次 require 这个文件的时候,都打印出 header。所以把这个文件引入两次:
require('./ascii-art') // 显示 header
require('./ascii-art') // 不显示 header.
第二个 require 不会显示 header,因为模块被缓存了。Node 把第一个调用缓存起来,第二次调用的时候就不加载文件了。
可以在第一次引入文件以后,使用 require.cache 来看一下都缓存了什么。缓存中实际上是一个对象,这个对象中包含了引入模块的属性。我们可以从 require.cache 中把相应的属性删掉,以使缓存失效,这样 Node 就会重新加载模块并且将其重新缓存起来。
对于这个问题,这并不是最有效的解决方案。最简单的解决方案是把 ascii-art.js 中的打印代码打包成一个函数,并且 export 这个函数。这样当我们引入 ascii-art.js 文件时,我们获取到的是这个函数,所以可以每次都能打印出想要的内容了:
require('./ascii-art')() // 打印出 header.
require('./ascii-art')() // 也会打印出 header.
总结
这就是我所要介绍的内容。回顾一下通篇,分别讲述了:
- Resolving
- Loading
- Wrapping
- Evaluating
- Caching
即解析、加载、打包、VM功能处理和缓存五大步骤,以及五大步骤中每个步骤都涉及到了什么内容。
在 Node.js 中引入模块:你所需要知道的一切都在这里的更多相关文章
- node.js中net模块创建服务器和客户端(TCP)
node.js中net模块创建服务器和客户端 1.node.js中net模块创建服务器(net.createServer) // 将net模块 引入进来 var net = require(" ...
- node.js中express模块创建服务器和http模块客户端发请求
首先下载express模块,命令行输入 npm install express 1.node.js中express模块创建服务端 在js代码同文件位置新建一个文件夹(www_root),里面存放网页文 ...
- node.js中ws模块创建服务端和客户端,网页WebSocket客户端
首先下载websocket模块,命令行输入 npm install ws 1.node.js中ws模块创建服务端 // 加载node上websocket模块 ws; var ws = require( ...
- node.js中module模块的理解
node.js中使用CommonJS规范实现模块功能,一个单独的文件就是一个单独的模块.通过require方法实现模块间的依赖管理. 通过require加载模块,是同步操作. 加载流程如下: 1.找到 ...
- Web 前端模块出现的原因,以及 Node.js 中的模块
模块出现原因 简单概述 随着 Web 2.0 时代的到来,JavaScript 不再是以前的小脚本程序了,它在前端担任了更多的职责,也逐渐地被广泛运用在了更加复杂的应用开发的级别上. 但是 JavaS ...
- Node.js中的模块接口module.exports浅析
在写node.js代码时,我们经常需要自己写模块(module).同时还需要在模块最后写好模块接口,声明这个模块对外暴露什么内容.实际上,node.js的模块接口有多种不同写法.这里作者对此做了个简单 ...
- Node.js中的模块接口module.exports
在写node.js代码时,我们经常需要自己写模块(module).同时还需要在模块最后写好模块接口,声明这个模块对外暴露什么内容.实际上,node.js的模块接口有多种不同写法.在此做了个简单的总结. ...
- node.js中通过dgram数据报模块创建UDP服务器和客户端
node.js中 dgram 模块提供了udp数据包的socket实现,可以方便的创建udp服务器和客户端. 一.创建UDP服务器和客户端 服务端: const dgram = require('dg ...
- node.js中net网络模块TCP服务端与客户端的使用
node.js中net模块为我们提供了TCP服务器和客户端通信的各种接口. 一.创建服务器并监听端口 const net = require('net'); //创建一个tcp服务 //参数一表示创建 ...
随机推荐
- vue+nginx配置二级域名
[1]修改路由文件 [2]修改配置文件 [3]修改本机nginx配置文件 [4]修改服务器nginx配置文件 [5]重启nginx文件,用二级域名访问 http://192.168.199.xxx:7 ...
- Linux安全审计-基础篇
安全审计这块我能想到的有两种方案可以解决,一种是在Linux中配置实现,一种是使用Python开发堡垒机实现,我先实现了第一种比较简单的:后面会开发堡垒机: 一.首先我们需要在/etc/profi ...
- WriteFile
从R3 ,到磁盘 1:kernel32 WriteFile 1) 挺惊讶的,符号好使了, 前面大概4条判断,根据句柄判断要写到什么地方,一共有4个地方可能要去, stdin stdout s ...
- finalize的作用
1. finalize的作用 finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法. finalize()与C++中的析构函数 ...
- java 打印1到n之间的整数
package java_day08; /* * 打印1-n之间的整数 * * 递归:方法体自己调用自己 */ public class DiGui { public static void main ...
- arm-linux-strip 的使用
3.2.1 1. 移除所有的符号信息 [arm@localhost gcc]#cp hello hello1 [arm@localhost gcc]#armlinuxstrip strip ...
- FCC——相关练习
算法题目1:Seek and Destroy(摧毁数组) 金克斯的迫击炮! 实现一个摧毁(destroyer)函数,第一个参数是待摧毁的数组,其余的参数是待摧毁的值. 帮助资源: Arguments ...
- python ORM框架:SqlAlchemy
ORM,对象关系映射,即Object Relational Mapping的简称,通过ORM框架将编程语言中的对象模型与数据库的关系模型建立映射关系,这样做的目的:简化sql语言操作数据库的繁琐过程( ...
- thinkphp 系统流程
用户URL请求 调用应用入口文件(通常是网站的index.php) 载入框架入口文件(ThinkPHP.php) 记录初始运行时间和内存开销 系统常量判断及定义 载入框架引导类(Think\Think ...
- 计算几何,向量——cf995c
网上的题解直接用随机过的, 自己用模拟就模拟三个向量的和并就模拟不出来.. 以后再回头看看 #include<bits/stdc++.h> #include<cmath> us ...