使用github--stanfordnlp--glove训练自己的数据词向量
1.准备语料
准备好自己的语料,保存为txt,每行一个句子或一段话,注意要分好词。将分好词的语料保存为×××.txt
2.准备源码
下载地址:https://github.com/stanfordnlp/GloVe,解压后将语料×××.txt添加到GloVe-master文件夹下
3.修改训练语料地址
打开demo.sh文件,由于默认是下载TXT8作为语料,故将这段代码删除,并修改CORPUS=×××.txt,最终文件内容如下:
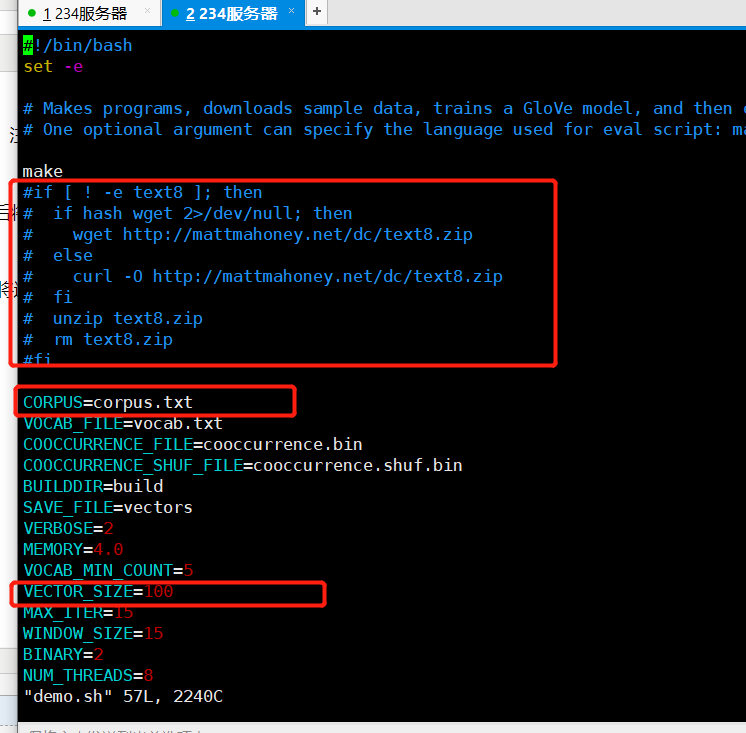
其他应该都可以自行修改。
4.执行
打开终端,进入GloVe-master文件后:
(1)make

(2)demo.sh


5.修改词向量文件
训练后会得到vetors.txt,打开后在第一行加上vacob_size vector_size,这样才能用word2vec的load函数加载成功
第一个数指明一共有多少个向量,第二个数指明每个向量有多少维
6.加载使用巽寮的词向量
1 from gensim.models import Word2Vec
2
3 model = Word2Vec.load_word2vec_format(‘vectors.txt’, binary=False)
接下来的使用就和word2vec一样
使用github--stanfordnlp--glove训练自己的数据词向量的更多相关文章
- 开源共享一个训练好的中文词向量(语料是维基百科的内容,大概1G多一点)
使用gensim的word2vec训练了一个词向量. 语料是1G多的维基百科,感觉词向量的质量还不错,共享出来,希望对大家有用. 下载地址是: http://pan.baidu.com/s/1boPm ...
- 词表征 3:GloVe、fastText、评价词向量、重新训练词向量
原文地址:https://www.jianshu.com/p/ca2272addeb0 (四)GloVe GloVe本质是加权最小二乘回归模型,引入了共现概率矩阵. 1.基本思想 GloVe模型的目标 ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 词向量(one-hot/SVD/NNLM/Word2Vec/GloVe)
目录 词向量简介 1. 基于one-hot编码的词向量方法 2. 统计语言模型 3. 从分布式表征到SVD分解 3.1 分布式表征(Distribution) 3.2 奇异值分解(SVD) 3.3 基 ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- smallcorgi/Faster-RCNN_TF训练自己的数据
熟悉了github项目提供的训练测试后,可以来训练自己的数据了.本文只介绍改动最少的方法,只训练2个类, 即自己添加的类(如person)和 background,使用的数据格式为pascal_voc ...
- YOLOv3:训练自己的数据(附优化与问题总结)
环境说明 系统:ubuntu16.04 显卡:Tesla k80 12G显存 python环境: 2.7 && 3.6 前提条件:cuda9.0 cudnn7.0 opencv3.4. ...
随机推荐
- Neo4j集群容器化部署
集群基本配置(示例) core servers: 10.110.10.11, 10.110.10.12, 10.110.10.13read replicas: 10.110.10.14, 10.110 ...
- 有哪些让人相见恨晚的Python库(一)
对于我这个经常用python倒腾数据的人来说,下面这个库是真·相见恨晚 记得有一次我在服务器上处理数据时,为了解决Pandas读取超过2000W条数据就内存爆炸的问题,整整用了两天时间来优化.最后通过 ...
- Kafka日志压缩剖析
1.概述 最近有些同学在学习Kafka时,问到Kafka的日志压缩(Log Compaction)问题,对于Kafka的日志压缩有些疑惑,今天笔者就为大家来剖析一下Kafka的日志压缩的相关内容. 2 ...
- 区间dp - 括号匹配并输出方案
Let us define a regular brackets sequence in the following way: 1. Empty sequence is a regular seque ...
- 线段相交的异或值 (线段树 or 优先队列)
VVQ 最近迷上了线段这种东西 现在他手上有 n 条线段,他希望在其中找到两条有公共点的线段,使得他们的异或值最大. 定义线段的异或值为它们并的长度减他们交的长度 输入描述: 第一行包括一个正整数 n ...
- 认识一下 RabbitMQ
分布式系统中,如何在各个应用之间高效的进行通信,是系统设计中的一个关键. 使用 消息代理(message broker) 是一个优雅的解决方案. RabbitMQ 就是一个被广泛应用的消息代理,遵循 ...
- Go的http包中默认路由匹配规则
# 一.执行流程 首先我们构建一个简单http server: ```go package main import ( "log" "net/http" ) f ...
- 双指针,BFS和图论(二)
(一)BFS 1.地牢大师 你现在被困在一个三维地牢中,需要找到最快脱离的出路! 地牢由若干个单位立方体组成,其中部分不含岩石障碍可以直接通过,部分包含岩石障碍无法通过. 向北,向南,向东,向西,向上 ...
- asp获取隐藏域的json 并解析
方法粗糙,适用度适中. var data2 = document.getElementById("hd_data02"); var val = data2.value; var o ...
- Centos 7 最小化部署zabbix
前言 文章内容是作者本人编写,之前一直放在word文档中,突然有闲情转移到博客上来了,欢迎后续观看者有问题找我探讨~~~ 废话不多说,先说下原理吧 概述 工作原理 通过c/s模式采集数据,基于b/s模 ...