Scrapy模拟登录赶集网
1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数
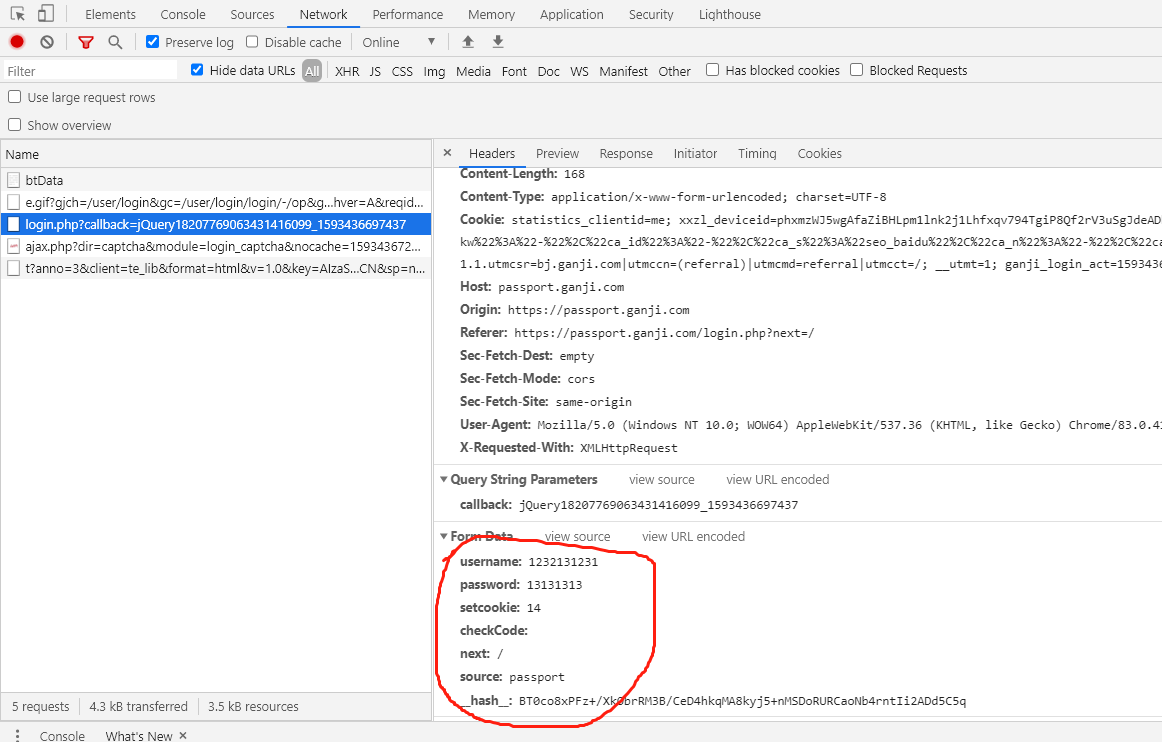
2. 我们只需构造出上面的参数传入formdata即可
参数分析:
setcookie:为自动登录所传的值,不勾选时默认为0。
__hash__值的分析:只需要查看response网页源代码即可 ,然后用正则表达式提取。
3.代码实现
1.workon到自己的虚拟环境 cmd切换到项目目录,输入scrapy startproject ganjiwangdenglu,然后就可以用pycharm打开该目录啦。
2.在pycharm terminal中输入scrapy ganji ganjicom 创建地址,如下为项目目录
3. 代码详情
import scrapy
import re class GanjiSpider(scrapy.Spider):
name = 'ganji'
allowed_domains = ['ganji.com']
start_urls = ['https://passport.ganji.com/login.php'] def parse(self, response):
hash_code = re.search(r'"__hash__":"(.+)"}', response.text).group(1) # 正则获取哈希
img_url = 'https://passport.ganji.com/ajax.php?dir=captcha&module=login_captcha' # 验证码url
yield scrapy.Request(img_url, callback=self.do_formdata, meta={'hash_code': hash_code}) # 发送获取验证码请求并保存验证码到本地 def do_formdata(self, response):
with open('yzm.jpg', 'wb') as f:
f.write(response.body)
# 验证码三种方案:1,保存下来手动输入,2,云打码,3 tesseract模块,在这里我们手动输入
code = input('请输入验证码:')
# 创建表单
formdata = {
'username': 'your_username',
'password': 'your_password',
'setcookie': '',
'checkCode': code,
'next': '',
'source': 'passport',
'__hash__': response.request.meta['hash_code'] # meta是在respose.request中
}
login_url = "https://passport.ganji.com/login.php"
yield scrapy.FormRequest(url=login_url, formdata=formdata, callback=self.after_login) # 发送登录请求 def after_login(self, response):
print(response.text)
4.终端输入scrapy carwl ganji 即可大功告成 。
返回来的json字符串解析如下:
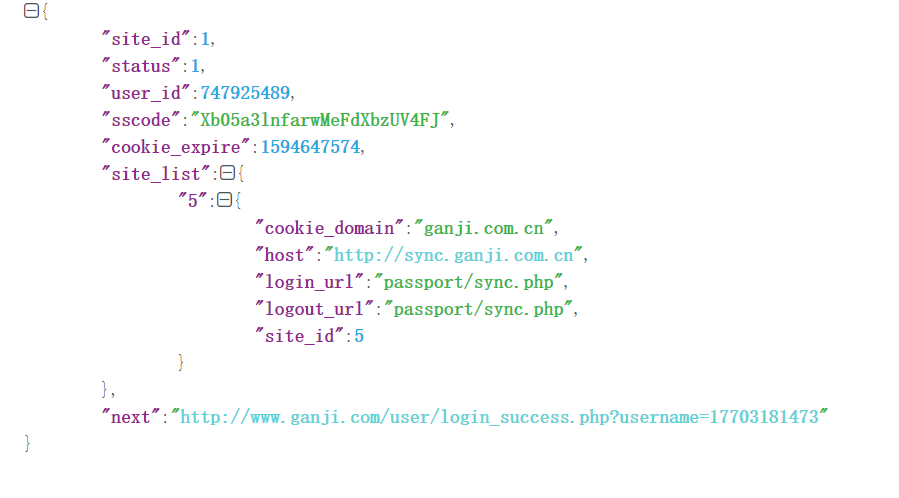
注:setting中的设置不在赘述。
Scrapy模拟登录赶集网的更多相关文章
- scrapy模拟登录微博
http://blog.csdn.net/pipisorry/article/details/47008981 这篇文章是介绍使用scrapy模拟登录微博,并爬取微博相关内容.关于登录流程为嘛如此设置 ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- 利用scrapy模拟登录知乎
闲来无事,写一个模拟登录知乎的小demo. 分析网页发现:登录需要的手机号,密码,_xsrf参数,验证码 实现思路: 1.获取验证码 2.获取_xsrf 参数 3.携带参数,请求登录 验证码url : ...
- urllib库利用cookie实现模拟登录慕课网
思路 1.首先在网页中使用账户和密码名登录慕课网 2.其次再分析请求头,如下图所示,获取到请求URL,并提取出cookie信息,保存到本地 3.最后在代码中构造请求头,使用urllib.request ...
- Scrapy模拟登录信息
携带cookie模拟登录 需要在爬虫里面自定义一个start_requests()的函数 里面的内容: def start_requests(self): cookies = '真实有效的cookie ...
- scrapy模拟登录
对于scrapy来说,也是有两个方法模拟登陆: 直接携带cookie 找到发送post请求的url地址,带上信息,发送请求 scrapy模拟登陆之携带cookie 应用场景: cookie过期时间很长 ...
- python爬虫之scrapy模拟登录
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎 ...
- 【Java】模拟登录教务网并获取数据
本文章仅做技术交流演示学习,请勿用于违法操作! 前期准备 首先我们需要到要模拟登录的网页,进行抓包操作. 使用Chrome浏览器打开系统的登录页面,按F12打开开发者工具 切换到Network选项卡 ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
随机推荐
- 处理npm安装模块报错01
报错:Error: EACCES: permission denied, mkdir '/usr/local/lib/node_modules/nodemon_tmp' 解决:sudo cnpm in ...
- Istio的运维-诊断工具(istio 系列五)
Istio的运维-诊断工具 在参考官方文档的时候发现环境偶尔会出现问题,因此插入一章与调试有关的内容,便于简单问题的定位.涵盖官方文档的诊断工具章节 目录 Istio的运维-诊断工具 使用istioc ...
- ubuntu12.04 qtcreate支持中文输入
1.sudo apt-get install ibus-qt4 2.重启电脑 reboot
- 【从单体架构到分布式架构】(三)请求增多,单点变集群(2):Nginx
上一个章节,我们学习了负载均衡的理论知识,那么是不是把应用部署多套,前面挂一个负载均衡的软件或硬件就可以应对高并发了?其实还有很多问题需要考虑.比如: 1. 当一台服务器挂掉,请求如何转发到其他正常的 ...
- TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值.梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降. 在回归中,使用梯度下降来优化损失函数并获得系数.本节将介绍如何使 ...
- MySQL的LIKE模糊查询优化
原文链接:https://www.cnblogs.com/whyat/p/10512797.html %xxx%这种方式对于数据量少的时候,我们倒可以随意用,但是数据量大的时候,我们就体验到了查询性能 ...
- 深入理解Java虚拟机学习笔记(三)-----类文件结构/虚拟机类加载机制
第6章 类文件结构 1. 无关性 各种不同平台的虚拟机与所有平台都统一使用的程序存储格式——字节码(即扩展名为 .class 的文件) 是构成平台无关性的基石. 字节码(即扩展名为 .class 的文 ...
- 测试人员遇到Android APP崩溃和无响应手足无措?
这2天,在测APP兼容性时,遇到APP奔溃闪退的情况.将问题反馈给开发后,开发自己调试后,没有复现.由于又是远程,base地不在一块,我总不能把手机寄过去吧,那也太费事了. 所以就想到,提供明确的报错 ...
- Spring中基于xml的AOP
1.Aop 全程是Aspect Oriented Programming 即面向切面编程,通过预编译方式和运行期动态代理实现程序功能的同一维护的一种技术.Aop是oop的延续,是软件开发中的 一个热点 ...
- 八张图彻底了解JDK8 GC调优秘籍-附PDF下载
目录 简介 分代垃圾回收器的内存结构 JDK8中可用的GC 打印GC信息 内存调整参数 Thread配置 通用GC参数 CMS GC G1参数 总结 简介 JVM的参数有很多很多,根据我的统计JDK8 ...