Scrapy模拟登录赶集网
1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数
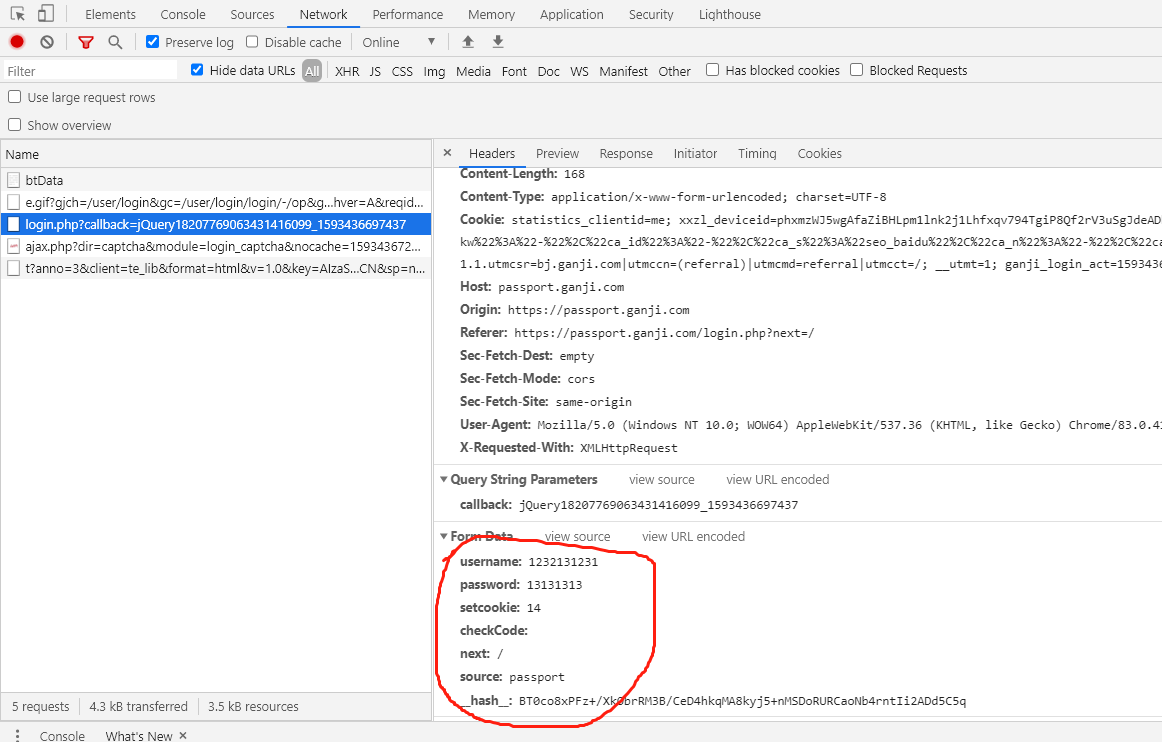
2. 我们只需构造出上面的参数传入formdata即可
参数分析:
setcookie:为自动登录所传的值,不勾选时默认为0。
__hash__值的分析:只需要查看response网页源代码即可 ,然后用正则表达式提取。
3.代码实现
1.workon到自己的虚拟环境 cmd切换到项目目录,输入scrapy startproject ganjiwangdenglu,然后就可以用pycharm打开该目录啦。
2.在pycharm terminal中输入scrapy ganji ganjicom 创建地址,如下为项目目录
3. 代码详情
import scrapy
import re class GanjiSpider(scrapy.Spider):
name = 'ganji'
allowed_domains = ['ganji.com']
start_urls = ['https://passport.ganji.com/login.php'] def parse(self, response):
hash_code = re.search(r'"__hash__":"(.+)"}', response.text).group(1) # 正则获取哈希
img_url = 'https://passport.ganji.com/ajax.php?dir=captcha&module=login_captcha' # 验证码url
yield scrapy.Request(img_url, callback=self.do_formdata, meta={'hash_code': hash_code}) # 发送获取验证码请求并保存验证码到本地 def do_formdata(self, response):
with open('yzm.jpg', 'wb') as f:
f.write(response.body)
# 验证码三种方案:1,保存下来手动输入,2,云打码,3 tesseract模块,在这里我们手动输入
code = input('请输入验证码:')
# 创建表单
formdata = {
'username': 'your_username',
'password': 'your_password',
'setcookie': '',
'checkCode': code,
'next': '',
'source': 'passport',
'__hash__': response.request.meta['hash_code'] # meta是在respose.request中
}
login_url = "https://passport.ganji.com/login.php"
yield scrapy.FormRequest(url=login_url, formdata=formdata, callback=self.after_login) # 发送登录请求 def after_login(self, response):
print(response.text)
4.终端输入scrapy carwl ganji 即可大功告成 。
返回来的json字符串解析如下:
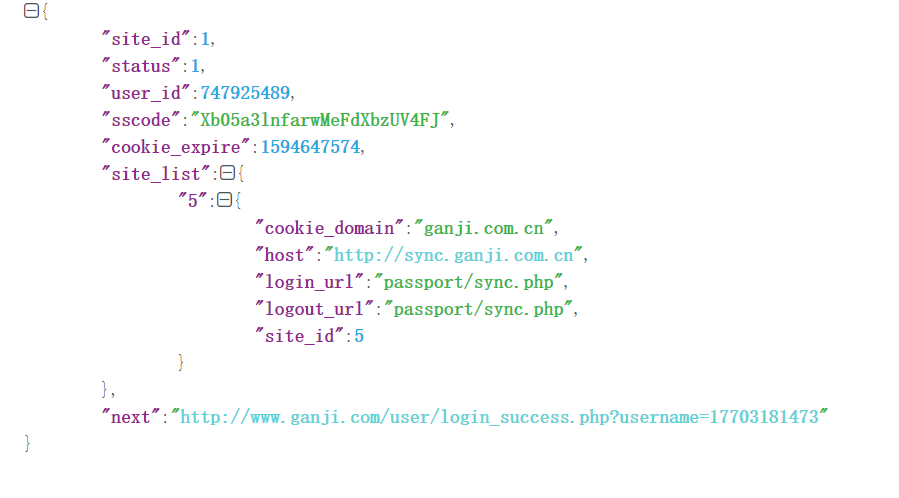
注:setting中的设置不在赘述。
Scrapy模拟登录赶集网的更多相关文章
- scrapy模拟登录微博
http://blog.csdn.net/pipisorry/article/details/47008981 这篇文章是介绍使用scrapy模拟登录微博,并爬取微博相关内容.关于登录流程为嘛如此设置 ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- 利用scrapy模拟登录知乎
闲来无事,写一个模拟登录知乎的小demo. 分析网页发现:登录需要的手机号,密码,_xsrf参数,验证码 实现思路: 1.获取验证码 2.获取_xsrf 参数 3.携带参数,请求登录 验证码url : ...
- urllib库利用cookie实现模拟登录慕课网
思路 1.首先在网页中使用账户和密码名登录慕课网 2.其次再分析请求头,如下图所示,获取到请求URL,并提取出cookie信息,保存到本地 3.最后在代码中构造请求头,使用urllib.request ...
- Scrapy模拟登录信息
携带cookie模拟登录 需要在爬虫里面自定义一个start_requests()的函数 里面的内容: def start_requests(self): cookies = '真实有效的cookie ...
- scrapy模拟登录
对于scrapy来说,也是有两个方法模拟登陆: 直接携带cookie 找到发送post请求的url地址,带上信息,发送请求 scrapy模拟登陆之携带cookie 应用场景: cookie过期时间很长 ...
- python爬虫之scrapy模拟登录
背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎 ...
- 【Java】模拟登录教务网并获取数据
本文章仅做技术交流演示学习,请勿用于违法操作! 前期准备 首先我们需要到要模拟登录的网页,进行抓包操作. 使用Chrome浏览器打开系统的登录页面,按F12打开开发者工具 切换到Network选项卡 ...
- scrapy 基础组件专题(十二):scrapy 模拟登录
1. scrapy有三种方法模拟登陆 1.1直接携带cookies 1.2找url地址,发送post请求存储cookie 1.3找到对应的form表单,自动解析input标签,自动解析post请求的u ...
随机推荐
- 消费者启动,允许期间报task supervisor timed out 异常,解决
如何解决后端项目启动时抛出 task supervisor timed out 异常 现象描述 后端项目启动时抛出如下异常,但是该后段项目能正常启动并注册到注册中心,不影响功能使用. 2018-10- ...
- Android中数据缓存的处理
为了避免重复操作数据库带来的性能问题,可以将数据库中的数据一次性读入到内存中,这样使得对数据查询的操作变得更加高效,但是这样会带来数据同步的问题,所以需要在每次操作完内存中的数据,同步去操作数据库中的 ...
- (三)MySQL基础查询(起别名、去重)
资料下载请前往:链接 补充内容: 1.数据库基本结构: 2.在sqlyog中将myemployees库导入数据库的方法: 右键root@localhost ->选择 执行SQL脚本->选定 ...
- Nirvana【思维+暴力优化】
Nirvana 题目链接(点击) Kurt reaches nirvana when he finds the product of all the digits of some positive i ...
- 求求你,别问了,Java字符串是不可变的
最近,又有好几个小伙伴问我这个问题:"二哥,为什么 Java 的 String 要设计成不可变的啊?"说实话,这也是一道非常经典的面试题,面试官超喜欢问.我之前写过这方面的文章,现 ...
- Android学习笔记Tab代替ActionBar做的顶部导航
1.先准备5个Fragement作为标签页 package com.lzp.youdaotab; import android.os.Bundle; import android.view.Layou ...
- 论logstash的玩法(ELK)
本篇文章采用的采用的是logstash-7.7.0版本,主要从如下几个方面介绍 1.logstash是什么,可以用来干啥 2.logstash的基本原理是什么 3.怎么去玩这个elk的组件logsta ...
- APP自动化1——Appium+pycharm自动化环境搭建全流程
1. 安装python3,pycharm,可参考之前写的文档:https://www.cnblogs.com/chenweitoag/p/13154815.html 2. 准备以下必要工具: 基于wi ...
- ImportError: cannot import name _remove_dead_weakref
出现这个错误, 和python环境有关. 电脑有多个版本造成的. python3 有这个_remove_dead_weakref python 2.7.10 并没有_remove_dead_weakr ...
- Oracle调用Java方法(下)复杂Jar包封装成Oracle方法以及ORA-29521错误
上一篇随笔中已经说了简单的Jar是如何封装的,但是我的需求是根据TIPTOP的查询条件产生XML文件并上传到FTP主机中,那么就要涉及到XML生成的方法和FTP上传的方法 所以在Eclipse写的时候 ...