如何寻找决策最优解?熵权TOPSIS助你科学决策
熵权topsis是一种融合了熵值法与TOPSIS法的综合评价方法。熵值法是一种客观赋值法,可以减少主观赋值带来的偏差;而topsis法是一种常见的多目标决策分析方法,适用于多方案、多对象的对比研究,从中找出最佳方案或竞争力最强的对象。
熵权topsis是先由熵权法计算得到指标的客观权重,再利用TOPSIS法,对各评价对象进行评价。
熵权topsis法分析步骤通常可分为以下三步:
(1)数据标准化
(2)熵值法确定评价指标的权重
(3)topsis法得到评价对象的排名结果
其中第2、3步由SPSSAU自动计算输出。
一、研究背景
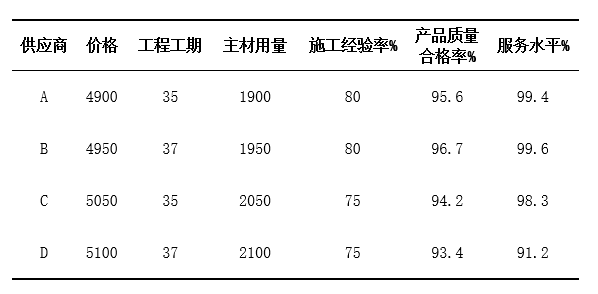
当前有一个项目进行招标,共有4个承包商,分别是A,B,C,D厂。由于招标需要考虑多个因素,各个方案指标的优劣程度也并不统一。为了保证评价过程中的客观、公正性。因此,考虑通过熵权TOPSIS法,对各个方案进行综合评价,从而选出最优方案。
二、操作步骤
(1)数据标准化
首先,需要对数据进行标准化处理。指标量纲(单位)不一致会造成不同指标的数据有大有小,这样会影响计算结果。为了消除量纲的影响,分析前需要先对数据进行处理。
正向指标:(X-Min)/(Max-Min) (生成变量-正向化MMS)
逆向指标:(Max-X)/(Max-Min) (生成变量-逆向化NMMS)
![]()
具体标准化的处理方式有很多种,具体结合文献和自身数据选择使用即可。不同的处理方式肯定会带来不同的结果,但结论一般不会有太大的偏倚。
本案例中,价格、工程工期、主材用量均为逆向指标;施工经验率、产品质量合格率、服务水平均为正向指标。按上述步骤分别对正向指标、逆向指标进行标准化处理。
(2)熵权TOPSIS法
选择【综合评价】--【熵权TOPSIS】。
![]()
将指标项放入【评价指标】框中,点击开始分析。
![]()
三、结果分析
(1)熵值法确定权重
![]()
上表是通过熵值法计算得出的6个指标权重,可以看出指标权重分布相对较为均匀。
各项指标的权重={0.1415, 0.2366, 0.1415, 0.1415, 0.2366, 0.1433, 0.1004}。
这一步仅仅得到了指标权重,熵值TOPSIS的核心在于TOPSIS法计算出相对接近度。权重值与数据相乘,得到新数据newdata,这一过程是SPSSAU自动完成,利用newdata进行TOPSIS法计算。
(2)topsis法得到每组样本的竞争力排名
![]()
从上表可知,利用熵权法后加权生成的数据(由SPSSAU算法自动完成)进行TOPSIS分析,针对6个指标进行TOPSIS评价。最终计算得出各评价对象与最优方案的接近程度(C值),并对C值进行排序,得到最优方案。
根据结果显示,A厂(评价对象1)是最佳的供应商选择,其次为B厂。
四、其他说明
(1)分析之前是否需要进行标准化、归一化、正向化或逆向化处理等?
如果原始数据中有负向指标(数字越大反而越不好的意思),需要针对此类指标先‘逆向化’处理。当确认所有指标均为正向指标(数字越大越好的意思)后,需要接着进标准化处理。
数据进行标准化处理目的在于解决量纲问题,标准化处理的方式有很多,常见是‘归一化’,‘区间化’,‘均值化’,‘求和归一化’,‘平方和归一化’等等非常多。如果指标数据全部都大于0,SPSSAU建议是使用‘均值化’处理,如果指标数据有小于或等于0的数据,SPSSAU建议使用‘区间化’(默认将数据压缩成1~2之间)。
(2)如果分析数据中有负数或者0值如何办?
如果分析数据有负数或者0,这会导致无法进行熵值法计算,SPSSAU算法默认会进行‘非负平移’处理。SPSSAU非负平移功能是指,如果某列(某指标)数据出现小于等于0,则让该列数据同时加上一个‘平移值’【该值为某列数据最小值的绝对值+0.01】,以便让数据全部都大于0,因而满足算法要求。
以上就是本次分享内容,登录SPSSAU官网了解更多内容。
如何寻找决策最优解?熵权TOPSIS助你科学决策的更多相关文章
- 基于topsis和熵权法
% % X 数据矩阵 % % n 数据矩阵行数即评价对象数目 % % m 数据矩阵列数即经济指标数目 % % B 乘以熵权的数据矩阵 % % Dist_max D+ 与最大值的距离向量 % % Dis ...
- BZOJ_4609_[Wf2016]Branch Assignment_决策单调性+带权二分
BZOJ_4609_[Wf2016]Branch Assignment_决策单调性+带权二分 Description 要完成一个由s个子项目组成的项目,给b(b>=s)个部门分配,从而把b个部门 ...
- BZOJ_5311_贞鱼_决策单调性+带权二分
BZOJ_5311_贞鱼_决策单调性+带权二分 Description 众所周知,贞鱼是一种高智商水生动物.不过他们到了陆地上智商会减半. 这不?他们遇到了大麻烦! n只贞鱼到陆地上乘车,现在有k辆汽 ...
- 吴裕雄 python 熵权法确定特征权重
一.熵权法介绍 熵最先由申农引入信息论,目前已经在工程技术.社会经济等领域得到了非常广泛的应用. 熵权法的基本思路是根据各个特征和它对应的值的变异性的大小来确定客观权重. 一般来说,若某个特征的信息熵 ...
- 熵权法(the Entropy Weight Method)以及MATLAB实现
按照信息论基本原理的解释,信息是系统有序程度的一个度量,熵是系统无序程度的一个度量:如果指标的信息熵越小,该指标提供的信息量越小,在综合评价中所起作用理当越小,权重就应该越低.因此,可利用信息熵这个工 ...
- 熵权法原理及matlab代码实现
参考原理博客地址https://blog.csdn.net/u013713294/article/details/53407087 一.基本原理 在信息论中,熵是对不确定性的一种度量.信息量越大,不确 ...
- 如何科学衡量广告投放效果?HMS Core分析服务助您科学归因
日益多元化的广告形式以及投放成本的不断攀升,让广告主们更加关注每一次广告投放带来的实际价值. 然而,广告主一般仅能从平台获得展示.点击.下载等前端效果字段,实际的用户注册.激活等后端深度转化指标并无法 ...
- DP的各种优化(动态规划,决策单调性,斜率优化,带权二分,单调栈,单调队列)
前缀和优化 当DP过程中需要反复从一个求和式转移的话,可以先把它预处理一下.运算一般都要满足可减性. 比较naive就不展开了. 题目 [Todo]洛谷P2513 [HAOI2009]逆序对数列 [D ...
- Spring Security入门(3-5)Spring Security 的鉴权 - 决策管理器和投票器
1.决策管理器的运行原理: 2.Spring Security提供的决策管理器实现 3.用户自定义的决策管理器
随机推荐
- 1_Java语言概述
学于尚硅谷开源课程 宋红康老师主讲 感恩 尚硅谷官网:http://www.atguigu.com 尚硅谷b站:https://space.bilibili.com/302417610?from=se ...
- Django学习路36_函数参数 反向解析 修改404 页面
在 templates 中创建对应文件名的 html 文件 (.html) 注: 开发者服务器发生变更是因为 python 代码发生变化 如果 html 文件发生变化,服务器不会进行重启 需要自己手动 ...
- Python字符串内建函数_下
Python字符串内建函数: 1.join(str) : 使用调用的字符串对 str 进行分割,返回值为字符串类型 # join(str) : # 使用调用的字符串对 str 进行分割. strs = ...
- Django学习路32_创建管理员及内容补充+前面内容复习
创建管理员 python manage.py createsuperuser 数据库属性命名限制 1.不能是python的保留关键字 2.不允许使用连续的下划线,这是由django的查询方式决定的 ...
- PHP xml_set_element_handler() 函数
定义和用法 xml_set_element_handler() 函数规定在 XML 文档中元素的起始和终止调用的函数. 如果成功,该函数则返回 TRUE.如果失败,则返回 FALSE.高佣联盟 www ...
- IDEA查看项目日志Version Control、log
打开IDEA找到以下两处: 右下角git 黄色指针指向当前项目的版本 选中初始化项目,点击右键选择"Checkout Revision 1db2f3d5",如下图 ...
- Typora + PicGo-Core + Custom Command 实现上传图片到图床
教程参考 Typora+PicGo-Core(command line)+Gitee实现图片上传到图床 主要借鉴 picgo 操作命令 Typora + PicGo + Gitee 实现图片自动上传到 ...
- AutoMapper 9.0的改造(续)
上一篇有一个读者,有疑问,如何自动化注册Dto 我开篇,做了一个自动化注册的 public sealed class AutoInjectAttribute : Attribute { public ...
- Android Studio--Activity实现跳转功能
首先,完成一个布局文件,名字就叫做activity_text_view.xml <?xml version="1.0" encoding="utf-8"? ...
- c语言学习笔记之typedef
这是我觉得这个博主总结的很好转载过来的 原地址:https://blog.csdn.net/weixin_41632560/article/details/80747640 C语言语法简单,但内涵却博 ...