hdfs读写删除过程解析
一、hdfs文件读取过程
hdfs有一个FileSystem实例,客户端通过调用这个实例的open()方法就可以打开系统中希望读取的文件,hdfs通过rpc协议调用Nadmenode获取block的位置信息,对于文件的每一块,Namenode会返回含有该block副本的Datanode的节点地址;客户端还会根据网络拓扑来确定它与每一个DataNode的位置信息,从离它最近的哪个DataNode获取block的副本(所谓的就近原则),最理想的情况是该block就存储在客户端所在的节点上。
hdfs会返回一个FDSaraInputStream对象,FDSDataInputStream类转而封装成DFSDataInputStream对象,这个对象管理着与DataNode和NameNode的I/O,具体过程如下:
1、客户端发起请求。
2、客户端从NameNode得到文件块及位置信息列表(即客户端从NameNode获取该block的元数据信息)
3、客户端直接和DataNode交互读取数据
4、读取完成关闭连接
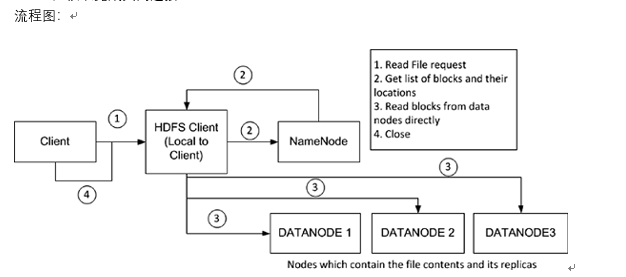
当FSDataInputStream与DataNode通信时遇到错误,它会选取另一个较近的DataNode,并为出故障的DataNode做标记以免重复向其读取数据。
FSDataInputStream还会对读取的数据块进行校验和确认,发现块损坏时也会重新读取并通知NameNode。
这样设计的巧妙之处:
1、 让客户端直接联系DataNode检索数据,可以使hdfs扩展到大量的并发客户端,因为数据流就是分散在集群的每个节点上的,在运行MapReduce任务时,每个客户端就是 DataNode节点。
2、 NameNode仅需相应数据块的weiz信息请求(位置信息在内存中,速度极快),否则随着客户端的增加,NameNode会很快成为瓶颈。
二、hdfs文件写入过程
hdfs有一个DistributedFileSystem实例,客户端通过调用这个实例的create()方法就可以创建文件。DistributedFileSystem会发送给NameNode一个RPC调用,在文件系统的命名空间创建一个新文件,在创建文件前NameNode会做一些检查,如文件是否存在,客户端是否有创建权限等,若检查通过,NameNode会为创建文件写一条记录到本地磁盘的EditLog,若不通过会向客户端抛出IOException。创建成功之后DistributedFileSystem会返回一个FSDataOutputStream对象,客户端由此开始写入数据。
同读文件过程一样,FSDataOutputStream类转而封装成DFSDataOutputStream对象,这个对象管理着与DataNode和NameNode的I/O,具体过程是:
1.客户端在向NameNode请求之前先写入文件数据到本地文件系统的一个临时文件
2.待临时文件达到块大小时开始向NameNode请求DataNode信息
3. NameNode在文件系统中创建文件并返回给客户端一个数据块及其对应DataNode的地址列表(列表中包含副本存放的地址)
4.客户端通过上一步得到的信息把创建临时文件块flush到列表中的第一个DataNode
5.当文件关闭,NameNode会提交这次文件创建,此时,文件在文件系统中可见
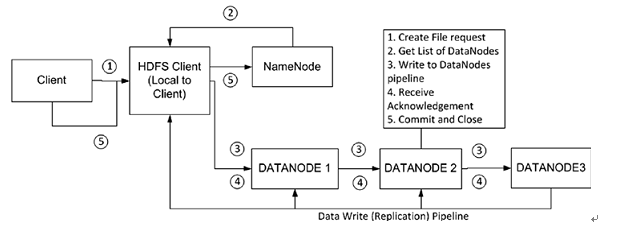
上面第四步描述的flush过程实际处理过程比较负杂,现在单独描述一下:
上面第四步描述的flush过程实际处理过程比较负杂,现在单独描述一下:
1. 首先,第一个DataNode是以数据包(数据包一般4KB)的形式从客户端接收数据的,DataNode在把数据包写入到本地磁盘的同时会向第二个DataNode(作为副本节点)传送数据。
2. 在第二个DataNode把接收到的数据包写入本地磁盘时会向第三个DataNode发送数据包
3. 第三个DataNode开始向本地磁盘写入数据包。此时,数据包以流水线的形式被写入和备份到所有DataNode节点
4. 传送管道中的每个DataNode节点在收到数据后都会向前面那个DataNode发送一个ACK,最终,第一个DataNode会向客户端发回一个ACK
5. 当客户端收到数据块的确认之后,数据块被认为已经持久化到所有节点。然后,客户端会向NameNode发送一个确认
6. 如果管道中的任何一个DataNode失败,管道会被关闭。数据将会继续写到剩余的DataNode中。同时NameNode会被告知待备份状态,NameNode会继续备份数据到新的可用的节点
7. 数据块都会通过计算校验和来检测数据的完整性,校验和以隐藏文件的形式被单独存放在hdfs中,供读取时进行完整性校验
三、hdfs文件删除过程
hdfs文件删除过程一般需要如下几步:
hdfs文件删除过程一般需要如下几步:
1. 一开始删除文件,NameNode只是重命名被删除的文件到/trash目录,因为重命名操作只是元信息的变动,所以整个过程非常快。
在/trash中文件会被保留一定间隔的时间(可配置,默认是6小时),在这期间,文件可以很容易的恢复,恢复只需要将文件从/trash移出即可。
2. 当指定的时间到达,NameNode将会把文件从命名空间中删除
3. 标记删除的文件块释放空间,HDFS文件系统显示空间增加
hdfs读写删除过程解析的更多相关文章
- HDFS读写数据过程
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
- Android解析WindowManagerService(三)Window的删除过程
前言 在本系列文章中,我提到过:Window的操作分为两大部分,一部分是WindowManager处理部分,另一部分是WMS处理部分,Window的删除过程也不例外,本篇文章会介绍Window的删除过 ...
- 曹工说Redis源码(5)-- redis server 启动过程解析,以及EventLoop每次处理事件前的前置工作解析(下)
曹工说Redis源码(5)-- redis server 启动过程解析,eventLoop处理事件前的准备工作(下) 文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- MHA自动Failover过程解析(updated) 转
允许转载, 转载时请以超链接形式标明文章原始出处和网站信息 http://www.mysqlsystems.com/2012/03/figure-out-process-of-autofailover ...
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- Hadoop之HDFS读写原理
一.HDFS基本概念 HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访 ...
随机推荐
- 第15.20节 PyQt(Python+Qt)入门学习:QColumnView的作用及开发中对应Model的使用
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在Qt Designer的Item Views(Model-based)部件中,Colum ...
- 冰点文库下载器 v3.2.12(0314) 去广告单文件
冰点文库,免积分免登陆文档下载神器!付费文档免费下载工具.百度文库免费下载工具. 冰点文库下载器,免费下载文档工具,无需积分也无需登陆就能自由下载百度文库.豆丁网.丁香网.电器网.MBA ...
- 团队作业三——需求改进&系统设计
需求改进&系统设计 一. 需求&原型改进 1. 针对课堂讨论环节老师和其他组的问题及建议,对修改选题及需求进行修改 老师及其他组的同学在课堂讨论时尚未提出问题及修改意见,但是课后我们有 ...
- Scrum冲刺_Day03
一.团队展示: 1.项目:light_note备忘录 2.队名:删库跑路队 3.团队成员 队员(不分先后) 项目角色 黄敦鸿 后端工程师.测试 黄华 后端工程师.测试 黄骏鹏 后端工程师.测试 黄源钦 ...
- socket和http有什么区别?
socket是网络传输层的一种技术,跟http有本质的区别,http是应用层的一个网络协议.使用socket技术理论上来讲, 按照http的规范,完全可以使用socket来达到发送http请求的目的, ...
- 五、Zookeeper基于API操作Node节点
安装zookeeper :linux下安装Zookeeper 3.4.14 zookeeper 分为5个包: org.apache.zookeeper //客户端主要类文件 org.apache.zo ...
- 8、Spring Cloud Zuul
1.Zuul简介 Zuul包含了对请求的路由和过滤两个最主要的功能. 路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础. 过滤器功能则负责对请求的处理过程进行干预,是实现请 ...
- vue单页面应用刷新网页后vuex的state数据丢失的解决办法
第一种方案 首先将数据保存在vuex的store中,同时将这些信息也保存在sessionStorage中.这里需要注意的是vuex中的变量是响应式的,而sessionStorage不是,当你改变vue ...
- Docker(二):Docker镜像仓库Harbor搭建
安装docker-compose 因为docker-compose下载容易失败, 所以选择从github下载方式安装. [root@harbor ~]# mv docker-compose-Linux ...
- 一、Electron + Webpack + Vue 搭建开发环境及打包安装
目录 Webpack + Vue 搭建开发环境及打包安装 ------- 打包渲染进程 Electron + Webpack 搭建开发环境及打包安装 ------- 打包主进程 Electron + ...