scrapy item
item
item定义了爬取的数据的model
item的使用类似于dict
定义
在items.py中,继承scrapy.Item类,字段类型scrapy.Field()
实例化:(假设定义了一个名为Product的item类)
Product(key1=value1, key2=value2)
Product({key1:value1, key2:value2}
取赋值
product['key']
product.get('key')
product['key']=value
获取key,value的list
product.keys()
product.items()
转dict
dict(product)
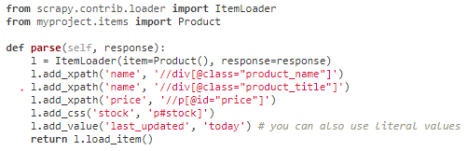
itemloader
scrapy item的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- [scrapy]Item Loders
Items Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},i ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- 使用sqlalchemy用orm方式写pipeline将scrapy item快速存入 MySQL
传统的使用scrapy爬下来的数据存入mysql,用的是在pipeline里用pymysql存入数据库, 这种方法需要写sql语句,如果item字段数量非常多的 情况下,编写起来会造成很大的麻烦. 我 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- scrapy item处理----cooperator和parallel()函数
twisted的task之cooperator和scrapy的parallel()函数 本文是关于下载结果返回后调用item处理的过程实现研究. 从scrapy的结果处理说起 def handle_s ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
随机推荐
- tensorflow 之模型的保存与加载(二)
上一遍博文提到 有些场景下,可能只需要保存或加载部分变量,并不是所有隐藏层的参数都需要重新训练. 在实例化tf.train.Saver对象时,可以提供一个列表或字典来指定需要保存或加载的变量. #!/ ...
- Unix系统编程(六)write系统调用
write系统调用将数据写入一个打开的文件. ssize_t write(int fd, void *buffer, size_t count); write调用的参数含义与read调用相类似.buf ...
- a5调试
1 generating rsa key...[ 4.452000] mmc0: error -110 whilst initialising SD card[ 5.602000] mmc ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- MFC编程之创建Ribbon样式的应用程序框架
Ribbon界面就是微软从Office2007開始引入的一种为了使应用程序的功能更加易于发现和使用.降低了点击鼠标的次数的新型界面.从实际效果来看,不仅外观美丽,并且功能直观,用户操作简洁方便. 利用 ...
- 13 memcache服务检查
[root@cache01 scripts]# vim mem_check.sh #!/bin/bash count_mem=$(netstat -lntup|grep memcached|wc -l ...
- Could not resolve dependencies for project
最近项目上使用的是idea ide的多模块话,需要模块之间的依赖,比如说系统管理模块依赖授权模块进行认证和授权,而认证授权模块需要依赖系统管理模块进行,然后,我就开始相互依赖,然后出现这样的问题: “ ...
- Oracle Tuning 总括
oracle tuning 分为3个阶段 1. application 调优阶段, 包括设计的调优, SQL语句调优, 管理权限等内容, (这部分是我的重点) (调优人员 application de ...
- mac上制作u盘启动盘
Mac上制作Ubuntu USB启动盘 一.下载ubuntu iso镜像 二.将iso转换为img文件 $ hdiutil convert -format UDRW -o /path/to/gener ...
- 嵌入式开发之davinci--- 8148/8168/8127 中的图像采集格式Sensor信号输出YUV、RGB、RAW DATA、JPEG 4种方式区别
简单来说,YUV: luma (Y) + chroma (UV) 格式, 一般情况下sensor支持YUV422格式,即数据格式是按Y-U-Y-V次序输出的RGB: 传统的红绿蓝格式,比如RGB565 ...