[scrapy]Item Loders
Items
Items就是结构化数据的模块,相当于字典,比如定义一个{"title":"","author":""},items_loders就是从网页中提取title和author字段填充到items里,比如{"title":"初学scrapy","author":"Alex"},然后items把结构化的数据传给pipeline,pipeline可以把数据插入进MySQL里.
实例
items.py
import scrapy class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_date = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
jobbole.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.loader import ItemLoader from urllib import parse
import re
import datetime
from ArticleSpider.items import JobBoleArticleItem from utils.common import get_md5 class JpbboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] #先下载http://blog.jobbole.com/all-posts/这个页面,然后传给parse解析 def parse(self, response): #1.start_urls下载页面http://blog.jobbole.com/all-posts/,然后交给parse解析,parse里的post_urls获取这个页面的每个文章的url,Request下载每个文章的页面,然后callback=parse_detail,交给parse_detao解析
#2.等post_urls这个循环执行完,说明这一个的每个文章都已经解析完了, 就执行next_url,next_url获取下一页的url,然后Request下载,callback=self.parse解析,parse从头开始,先post_urls获取第二页的每个文章的url,然后循环每个文章的url,交给parse_detail解析 #获取http://blog.jobbole.com/all-posts/中所有的文章url,并交给Request去下载,然后callback=parse_detail,交给parse_detail解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
yield Request(url=parse.urljoin(response.url,post_url),meta={"front_image_url":image_url},callback=self.parse_detail) #获取下一页的url地址,交给Request下载,然后交给parse解析
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
if next_url:
yield Request(url=next_url,callback=self.parse) def parse_detail(self,response): article_item = JobBoleArticleItem() #实例化定义的items item_loader = ItemLoader(item=JobBoleArticleItem(),response=response) #实例化item_loader,把我们定义的item传进去,再把下载器下载的网页穿进去
#针对直接取值的情况
item_loader.add_value("url",response.url)
item_loader.add_value("url_object_id",get_md5(response.url))
item_loader.add_value("front_image_url",[front_image_url])
#针对css选择器
item_loader.add_css("title",".entry-header h1::text")
item_loader.add_css("create_date","p.entry-meta-hide-on-mobile::text")
item_loader.add_css("praise_nums",".vote-post-up h10::text")
item_loader.add_css("comment_nums","a[href='#article-comment'] span::text")
item_loader.add_css("fav_nums",".bookmark-btn::text")
#把结果返回给items
article_item = item_loader.load_item()
- .add_value:把直接获取到的值,复制给字段
- .add_css:需要通过css选择器获取到的值
- .add_xpath:需要通过xpath选择器获取到的值
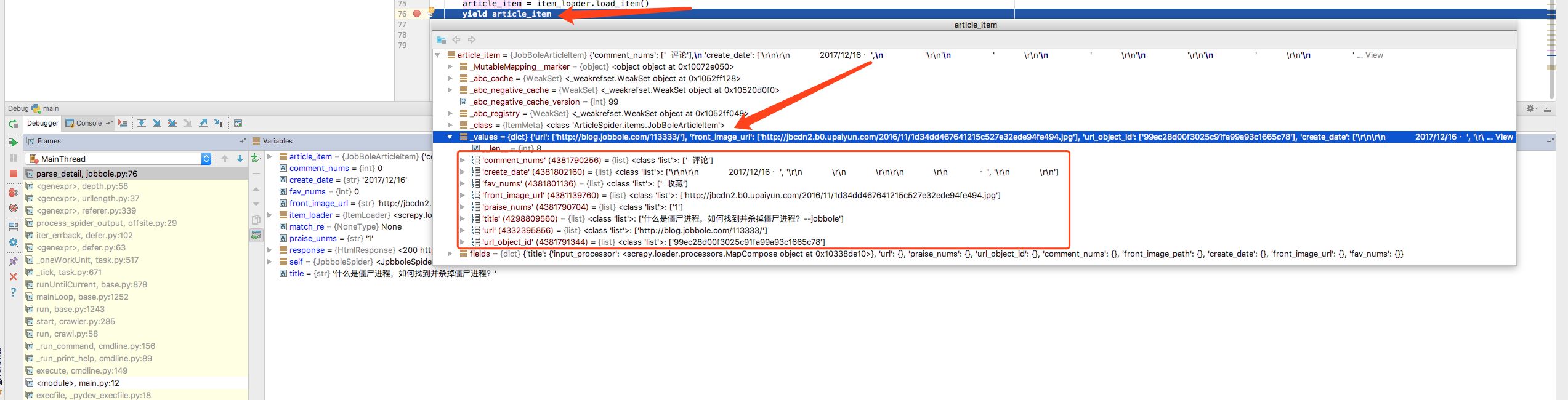
debug调试,可以看到拿到的信息
[scrapy]Item Loders的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- scrapy item
item item定义了爬取的数据的model item的使用类似于dict 定义 在items.py中,继承scrapy.Item类,字段类型scrapy.Field() 实例化:(假设定义了一个名 ...
- 第十篇 scrapy item loader机制
在我们执行scrapy爬取字段中,会有大量的和下面的代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制 def parse_detail(sel ...
- scrapy item pipeline
item pipeline process_item(self, item, spider) #这个是所有pipeline都必须要有的方法在这个方法下再继续编辑具体怎么处理 另可以添加别的方法 ope ...
- 使用sqlalchemy用orm方式写pipeline将scrapy item快速存入 MySQL
传统的使用scrapy爬下来的数据存入mysql,用的是在pipeline里用pymysql存入数据库, 这种方法需要写sql语句,如果item字段数量非常多的 情况下,编写起来会造成很大的麻烦. 我 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- scrapy item处理----cooperator和parallel()函数
twisted的task之cooperator和scrapy的parallel()函数 本文是关于下载结果返回后调用item处理的过程实现研究. 从scrapy的结果处理说起 def handle_s ...
- Scrapy系列教程(2)------Item(结构化数据存储结构)
Items 爬取的主要目标就是从非结构性的数据源提取结构性数据,比如网页. Scrapy提供 Item 类来满足这种需求. Item 对象是种简单的容器.保存了爬取到得数据. 其提供了 类似于词典(d ...
随机推荐
- GIMP做成颜色蒙板
效果图: 原始的美女图片上盖了一层的颜色,这个是想出来的效果,只是用来实践学到的技能,具体的场景还没有确定. 1/首先打开原始的美女图片: 2/然后在添加一张新的图片,作为新的图层添加进来: 这样的话 ...
- Cookies和Session的区别和理解
Cookies和Session的区别和理解 cookie机制 Cookies是服务器在本地机器上存储的小段文本并随每一个请求发送至同一个服务器.IETF RFC 2965 HTTP State Man ...
- PyQt5(1)——QToolTip, QPushButton, QMessageBox, QDesktopWidget
#面向对象方法 import sys from PyQt5.QtWidgets import QApplication, QWidget, QToolTip, QPushButton, QMessag ...
- HttpServlet RequestDispatcher sendredirect和forward
Servlet的框架是由两个Java包组成:javax.servlet和javax.servlet.http. 在javax.servlet包中定义了所有的Servlet类都必须实现或扩展的的通用接口 ...
- svg path 动画效果
http://www.zhangxinxu.com/wordpress/2014/04/animateion-line-drawing-svg-path-%E5%8A%A8%E7%94%BB-%E8% ...
- intellij idea 17 log4j 中文乱码
先是在intellij idea里设置没有得到解决, 然后在tomcat的server.xml里设置没有得到解决, 再然后在log4j配置文件里配置没有得到解决. 以下是解决方案. C:\Progra ...
- 图论trainning-part-2 B. Claw Decomposition
B. Claw Decomposition Time Limit: 1000ms Memory Limit: 131072KB 64-bit integer IO format: %lld ...
- HDU-4417 Super Mario,划分树+二分!
Super Mario 这个题也做了一天,思路是很清晰,不过二分那里写残了,然后又是无限RE.. 题意:就是查询区间不大于k的数的个数. 思路:裸划分树+二分答案.将区间长度作为二分范围.这个是重点. ...
- n&(n-1)的用途
最近做LeetCode上面的题目,发现很多题目都用到了n&(n-1).感觉真是神通广大,下面就目前所看到的一些用途总结一下: 1,求一个int类型数是否为2的幂 当n=4时,二进制为:0100 ...
- HDU——2444The Accomodation of Students(BFS判二分图+最大匹配裸题)
The Accomodation of Students Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K ( ...