第1节 kafka消息队列:10、flume与kafka的整合使用
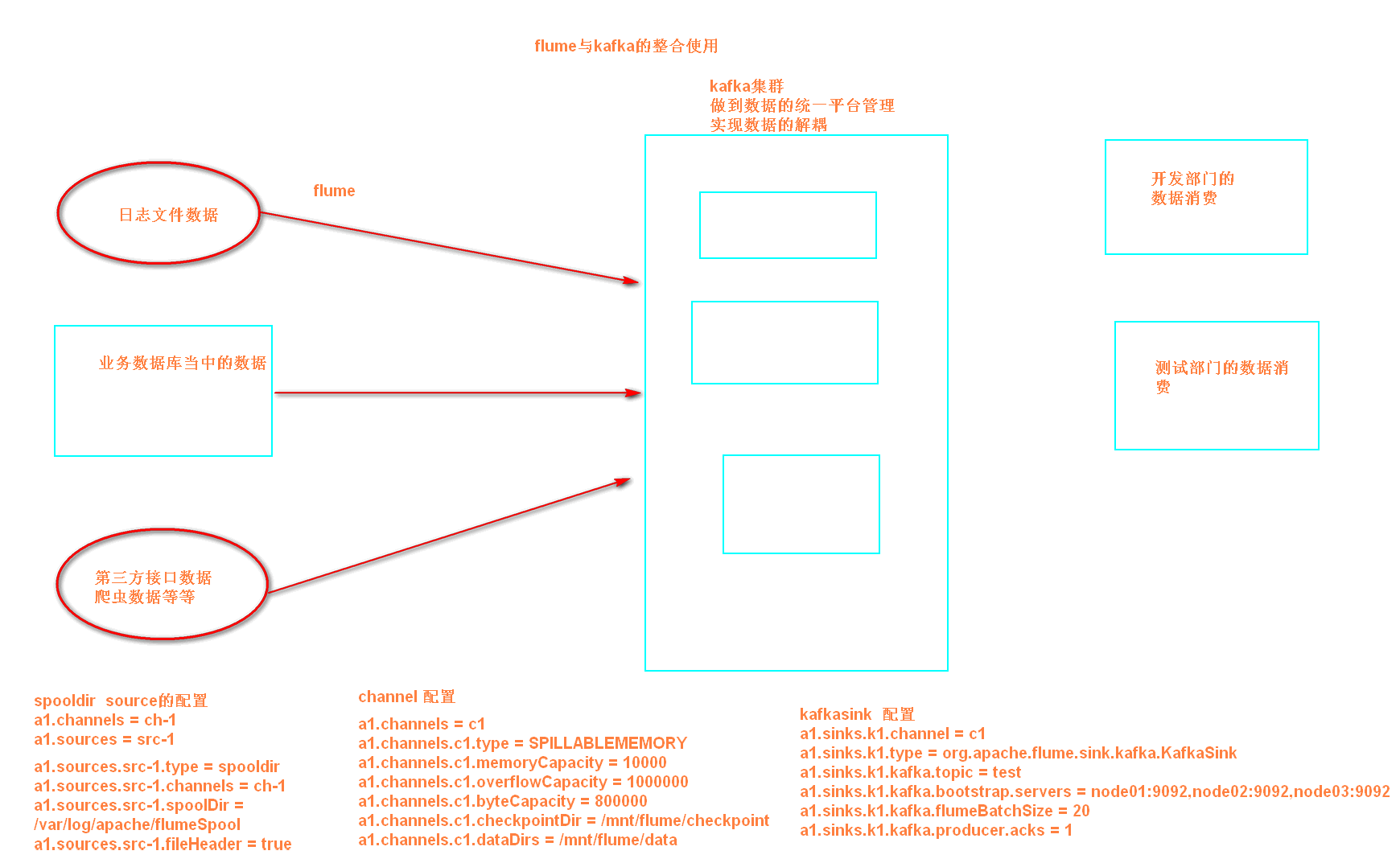
11、flume与kafka的整合
实现flume监控某个目录下面的所有文件,然后将文件收集发送到kafka消息系统中
第一步:flume下载地址
http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.14.0.tar.gz
第二步:上传解压flume
第三步:配置flume.conf
#为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#指定我们的source收集到的数据发送到哪个管道
a1.sources.r1.channels = c1
#指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/servers/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\\.tmp$
a1.sources.r1.inputCharset = GBK
#指定我们的channel为memory,即表示所有的数据都装进memory当中
a1.channels.c1.type = memory
#指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
启动flume
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console
第1节 kafka消息队列:10、flume与kafka的整合使用的更多相关文章
- 第1节 kafka消息队列:11、kafka的数据不丢失机制,以及kafka-manager监控工具的使用;12、课程总结
12.kafka如何保证数据的不丢失 12.1生产者如何保证数据的不丢失 kafka的ack机制:在kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到 如果是同步模 ...
- 第1节 kafka消息队列:1、kafka基本介绍以及与传统消息队列的对比
1. Kafka介绍 l Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. l Kafka最初是由LinkedIn开发,并于20 ...
- 第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3.kafka的架构模型 1.producer:消息的生产者,主要是用于生产消息的.主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通 ...
- 第1节 kafka消息队列:7、kafka的消费模型
- 使用Cloudera Manager部署Kafka消息队列
使用Cloudera Manager部署Kafka消息队列 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载需要安装的Kafka版本 1>.查看Cloudera Dis ...
- Kafka:docker安装Kafka消息队列
安装之前先看下图 Kafka基础架构及术语 Kafka基本组成 Kafka cluster: Kafka消息队列(存储消息的队列组件) Zookeeper: 注册中心(kafka集群依赖zookee ...
- Kafka基础教程(四):.net core集成使用Kafka消息队列
.net core使用Kafka可以像上一篇介绍的封装那样使用(Kafka基础教程(三):C#使用Kafka消息队列),但是我还是觉得再做一层封装比较好,同时还能使用它做一个日志收集的功能. 因为代码 ...
- kafka消息队列的简单理解
kafka在大数据.分布式架构中都很流行.kafka可以进行流式计算,也可以做为日志系统,还可以用于消息队列. 本篇主要是消息队列相关的知识. 零.kafka作为消息队列的优点: 分布式的系统 高吞吐 ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- 初试kafka消息队列中间件二(采用java代码收发消息)
初试kafka消息队列中间件二(采用java代码收发消息) 上一篇 初试kafka消息队列中间件一 今天的案例主要是将采用命令行收发信息改成使用java代码实现,根据上一篇的接着写: 先启动Zooke ...
随机推荐
- 「JSOI2013」哈利波特和死亡圣器
「JSOI2013」哈利波特和死亡圣器 传送门 首先二分,这没什么好说的. 然后就成了一个恒成立问题,就是说我们需要满足最坏情况下的需求. 那么显然在最坏情况下伏地魔是不会走回头路的 因为这显然是白给 ...
- 如何使用 Workman 做一个聊天室
一:首先,得简单说说 thinkphp+workerman 的安装. 安装 thinkphp5.1 composer create-project topthink/think=5.1.x-dev t ...
- Django框架之模板路径及静态文件路径配置
内容: (1)模板文件路径的配置 (2)静态文件路径的配置 一.模板文件路径的配置 模板文件主要通过jinja2模板进行渲染html页面,实现动态页面. 步骤一:创建一个template的文件夹,用于 ...
- Thymeleaf Tutorial 文档 中文翻译
原文档地址:https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html Thymeleaf官网地址:https://www.thym ...
- windows下如何快速删除大文件
rmdir 磁盘:\文件夹的名字 /s /q; eg:rmdir E:\vue_workspace\KB\day08 /s/q /S 表示除目录本身外,还将删除指定目录下的所有子目录和文件. ...
- 吴裕雄--天生自然TensorFlow2教程:链式法则
import tensorflow as tf x = tf.constant(1.) w1 = tf.constant(2.) b1 = tf.constant(1.) w2 = tf.consta ...
- c语言中的qsort用法
1.首先了解 int cmp(const void* a, const void* b) 表示声明cmp函数,其返回值为int型,参数为两个不可修改(const)的void型指针 2.函数原型 函数声 ...
- SpringBoot学习笔记(一)——构建springboot项目
生成一个SpringBoot的项目 开发和学习SpringBoot需要一个生成好的SpringBoot项目. 1.可以使用一些IDE(Integrated Development Environmen ...
- 3种使用MQ实现分布式事务的方式
1.保证消息传递与一致性 1.1生产者确保消息自主性 当生产者发送一条消息时,它必须完成他的所有业务操作. 如下图: 这保证消费者接受到消息时,生产者已处理完毕相关业务,也就是1PC的基础. 1.2 ...
- win10+anaconda安装tensorflow和keras遇到的坑小结
win10下利用anaconda安装tensorflow和keras的教程都大同小异(针对CPU版本,我的gpu是1050TI的MAX-Q,不知为啥一直没安装成功),下面简单说下步骤. 一 Anaco ...