将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤。
第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /spark.txt,即可。
第一:看整个代码视图
打开WordCountCluster.java源文件,修改此处代码:

第二步:
打好jar包,步骤是右击项目文件----RunAs--Run Configurations
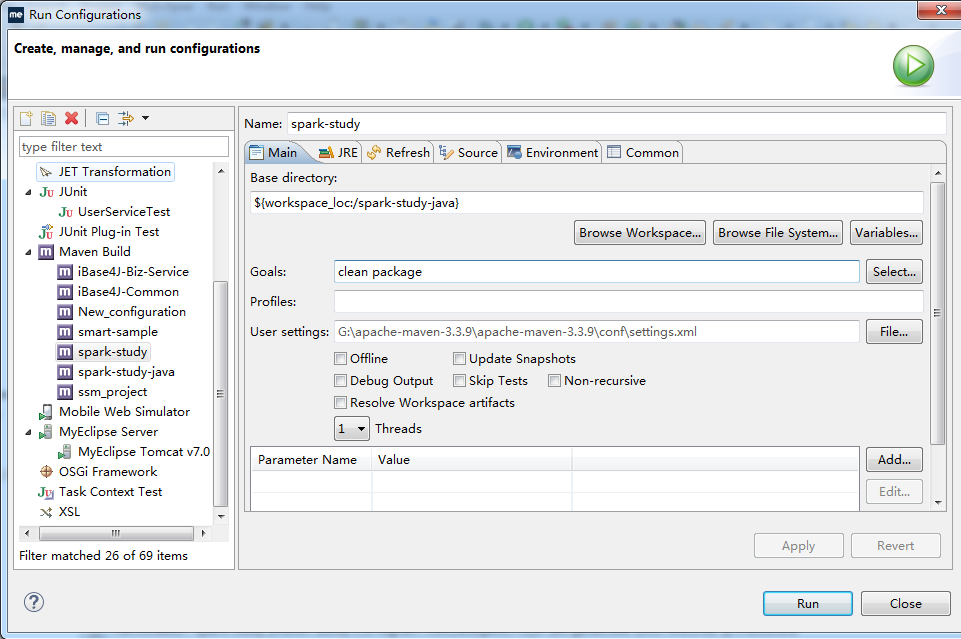
照图填写,然后开始拷贝工程下的jar包,如图,注意是拷贝那个依赖jar包,不是第二个
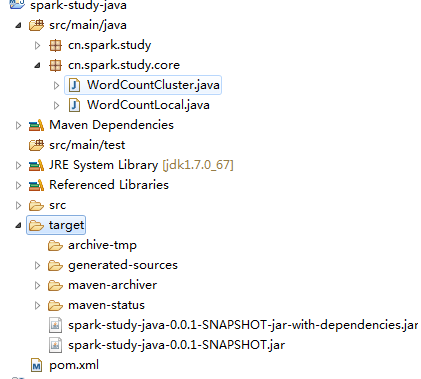
然后将复制到桌面的这个jar包和另外一个文件WordCount.sh上传到平台上,即拖拽到平台上
开始使用上传命令hadoop fs -put spark.txt /spark.txt。
第三步:要启动hadoop集群,启动方式见hadoop配置博文,注意,如果集群里面的datanode或者是namenode之一没有启动,则找到这样一个目录,并删除里面的文件,重新启动即可,如图:即home目录下的文件

打开home目录下的hadoop----dfs-----把里面的两个目录都删除掉,即可
第四步:此时hadoop集群已经启动,然后我们开始修改WordCount.sh配置文件
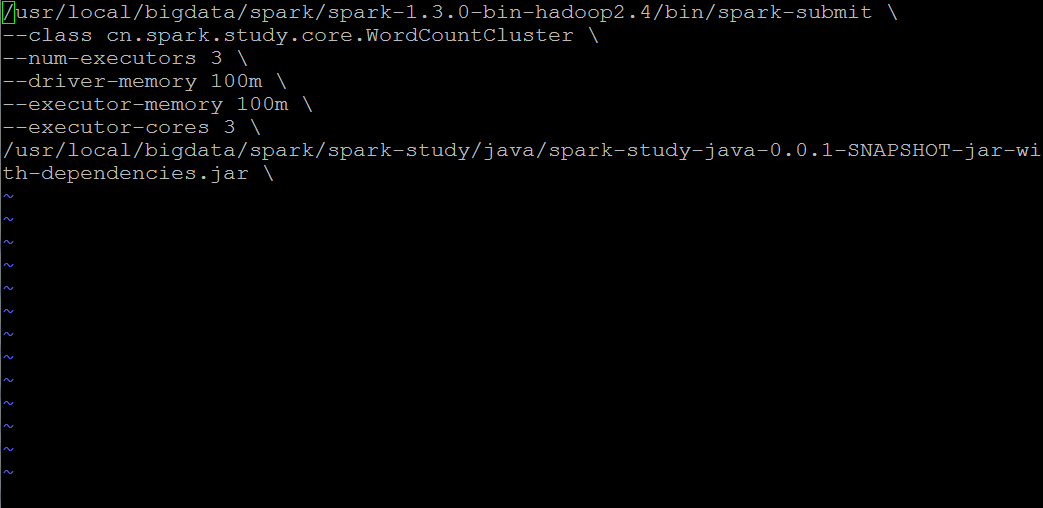
几点注意:
1,class目录必须对应你的eclipse工程下的项目目录
2,关于spark-submit提交工具,路径要和你的spark集群上面的路径一致 ,这里找的是spark集群下的bin目录里面的文件,不是spark-study下的文件,切记
3,最后一行路径就是你的上传程序jar包到平台上后的路径,注意一定是后缀为jar的文件包,不能上传其它的后缀名,一律无效。
4,注意:修改过本地eclipse的程序文件,一定要生效的话,就要重新上传打包,然后部署。
第五步,启动程序文件,即如下图,在wordcount.sh配置文件的目录下,执行以下命令即可

将java开发的wordcount程序提交到spark集群上运行的更多相关文章
- IntelliJ IDEA编写的spark程序在远程spark集群上运行
准备工作 需要有三台主机,其中一台主机充当master,另外两台主机分别为slave01,slave02,并且要求三台主机处于同一个局域网下 通过命令:ifconfig 可以查看主机的IP地址,如下图 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- win10下将spark的程序提交给远程集群中运行
一,开发环境: 操作系统:win19 64位 IDE:IntelliJ IDEA JDK:1.8 scala:scala-2.10.6 集群:linux上cdh集群,其中spark为1.5.2,had ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- 在集群上运行caffe程序时如何避免Out of Memory
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况.实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较 ...
随机推荐
- python列表的通用操作
#'+'和'*'#+可以将两个列表拼接为一个列表my_list = [1,2,3]+[4,5,6]#*可以将列表重复指定的次数my_list = [1,2,3]*5 print(my_list) #创 ...
- Java编码算法和摘要算法
编码算法 编码算法是将一种形式转换成等价的另外一种形式.主要是为了方便某种特定场景的处理. 字母如何在计算机中表示呢? 用ASCII编码 那中文字符如何在计算机中表示呢? 用Unicode编码 如何同 ...
- Oracle入门第四天(下)——约束
一.概述 1.分类 表级约束主要分为以下几种: NOT NULL UNIQUE PRIMARY KEY FOREIGN KEY CHECK 2.注意事项 如果不指定约束名 ,Oracle server ...
- 20155239 2016-2017-2 《Java程序设计》第10周学习总(2017-04-22 16:26
教材学习 1.基本概念划分 OIS的七层协议: 应用层.表示层.会话层.运输层.网络层.数据链路层.物理层. OIS的五层协议: 应用层.运输层.网络层.数据链路层.物理层. 由下往上介绍如下: 2. ...
- 20155331 《Java程序设计》实验一(Java开发环境的熟悉)实验报告
20155331 <Java程序设计>实验一(Java开发环境的熟悉)实验报告 一.实验内容及步骤 使用JDK编译.运行简单的java程序 实验目的与要求: 使用JDK和IDE编译.运行简 ...
- 关于快速沃尔什变换(FWT)的一些个人理解
定义 FWT是一种快速完成集合卷积运算的算法. 它可以用于求解类似 $C[i]=\sum\limits_{j⊗k=i}A[j]*B[k]$ 的问题. 其中⊗代表位运算中的|,&,^的其中一种. ...
- 【LG5019】[NOIP2018]道路铺设
[LG5019][NOIP2018]道路铺设 题面 洛谷 题解 \(NOIP\) 抄 \(NOIP\)差评 设当前做到了位置\(i\) 且\(h_i\) \(-\) \(h_i\)\(_+\)\(_1 ...
- P1546 最短网络(codevs | 2627村村通)
P1546 最短网络 Agri-Net 题目背景 农民约翰被选为他们镇的镇长!他其中一个竞选承诺就是在镇上建立起互联网,并连接到所有的农场.当然,他需要你的帮助. 题目描述 约翰已经给他的农场安排了一 ...
- SQL基本的45题
-- 查询Student表中的所有记录的Sname.Ssex和Class列.SELECT Sname,Ssex,Class from student -- 查询教师所有的单位即不重复的Depart列. ...
- Java 注解 初探 (一)
自JDK1.5之后,就开始出现注解.想要了解注解的来源和注解的用法,通过搜索引擎大都是针对某一个注解的解释,很难找到关于注解系列的文章,便自己看下. 基于Annotation的注释,说明Annotai ...