[Spark Core] 在 Spark 集群上运行程序
0. 说明
将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行。
1. 打包程序
1.0 前提
搭建好 Spark 集群,完成代码的编写。
1.1 修改代码
【添加内容,判断参数的有效性】
// 判断参数的有效性
if (args == null || args.length == 0) {
throw new Exception("需要指定文件路径") ;
}
【注释掉 conf.setMaster("...")】
// 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成
// conf.setMaster("spark://s101:7077")
【将加载文件部分由固定路径改为读取传入的路径参数】
// 1. 加载文件
val rdd1 = sc.textFile(args(0))
【原代码参考】
Spark 实现标签生成 中 Scala 代码部分
【修改过的代码如下】
import java.util
import com.share.util.TagUtil
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD /**
* 标签生成
*/
object TaggenCluster {
def main(args: Array[String]): Unit = {
// 判断参数的有效性
if (args == null || args.length == 0) {
throw new Exception("需要指定文件路径") ;
}
// 创建 spark 配置对象
val conf = new SparkConf()
conf.setAppName("TaggenScalaApp") // 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成
// conf.setMaster("spark://s101:7077") // 创建上下文
val sc = new SparkContext(conf) // 1. 加载文件
val rdd1 = sc.textFile(args(0)) // 2. 解析每行的json数据成为集合
val rdd2: RDD[(String, java.util.List[String])] = rdd1.map(line => {
val arr: Array[String] = line.split("\t")
// 商家id
val busid: String = arr(0)
// json
val json: String = arr(1)
val list: java.util.List[String] = TagUtil.extractTag(json)
Tuple2[String, java.util.List[String]](busid, list)
}) // 3. 过滤空集合 (85766086,[干净卫生, 服务热情, 价格实惠, 味道赞])
val rdd3: RDD[(String, util.List[String])] = rdd2.filter((t: Tuple2[String, java.util.List[String]]) => {
!t._2.isEmpty
}) // 4. 将值压扁 (78477325,味道赞)
val rdd4: RDD[(String, String)] = rdd3.flatMapValues((list: java.util.List[String]) => {
// 导入隐式转换
import scala.collection.JavaConversions._
list
}) // 5. 滤除数字的tag (78477325,菜品不错)
val rdd5 = rdd4.filter((t: Tuple2[String, String]) => {
try {
Integer.parseInt(t._2)
false
} catch {
case _ => true
}
}) // 6. 标1成对 ((70611801,环境优雅),1)
val rdd6: RDD[Tuple2[Tuple2[String, String], Int]] = rdd5.map((t: Tuple2[String, String]) => {
Tuple2[Tuple2[String, String], Int](t, 1)
}) // 7. 聚合 ((78477325,味道赞),8)
val rdd7: RDD[Tuple2[Tuple2[String, String], Int]] = rdd6.reduceByKey((a: Int, b: Int) => {
a + b
}) // 8. 重组 (83073343,List((性价比高,8)))
val rdd8: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd7.map((t: Tuple2[Tuple2[String, String], Int]) => {
Tuple2[String, List[Tuple2[String, Int]]](t._1._1, Tuple2[String, Int](t._1._2, t._2) :: Nil)
}) // 9. reduceByKey (71039150,List((环境优雅,1), (价格实惠,1), (朋友聚会,1), (团建,1), (体验好,1)))
val rdd9: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd8.reduceByKey((a: List[Tuple2[String, Int]], b: List[Tuple2[String, Int]]) => {
a ::: b
}) // 10. 分组内排序 (88496862,List((回头客,5), (服务热情,4), (味道赞,4), (分量足,3), (性价比高,2)))
val rdd10: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd9.mapValues((list: List[Tuple2[String, Int]]) => {
val list2: List[Tuple2[String, Int]] = list.sortBy((t: Tuple2[String, Int]) => {
-t._2
})
list2.take(5)
}) // 11. 商家间排序 (75144086,List((服务热情,38), (效果赞,30), (无办卡,22), (环境优雅,22), (性价比高,21)))
val rdd11: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd10.sortBy((t: Tuple2[String, List[Tuple2[String, Int]]]) => {
t._2(0)._2
}, false) rdd11.collect().foreach(println)
}
}
1.2 导出 Jar 包,并添加依赖的第三方类库
【打开 Project Structure】
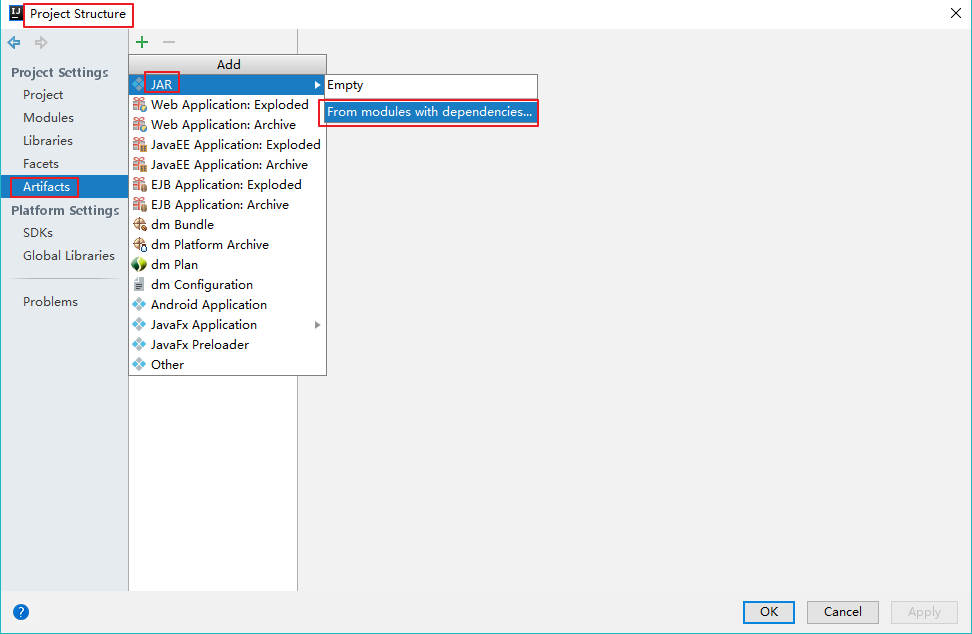
【添加模块】
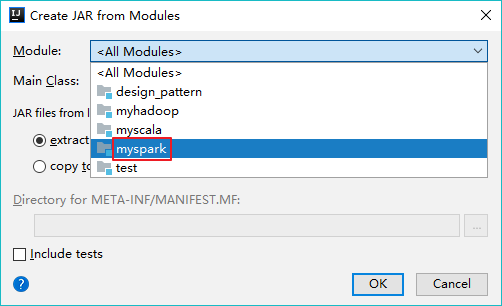
【移除第三方类库】
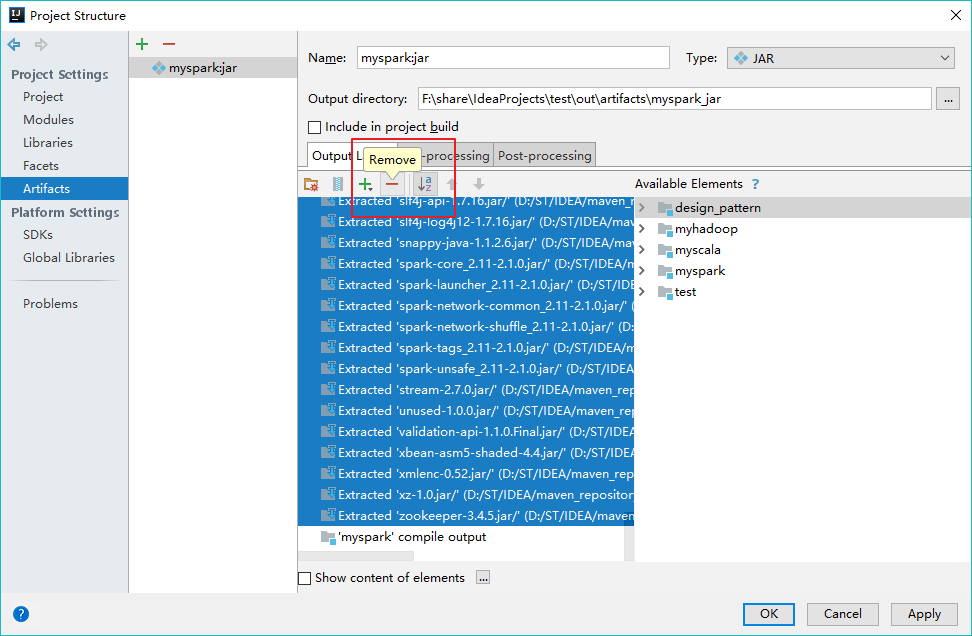
【添加第三方类库 fastjson】
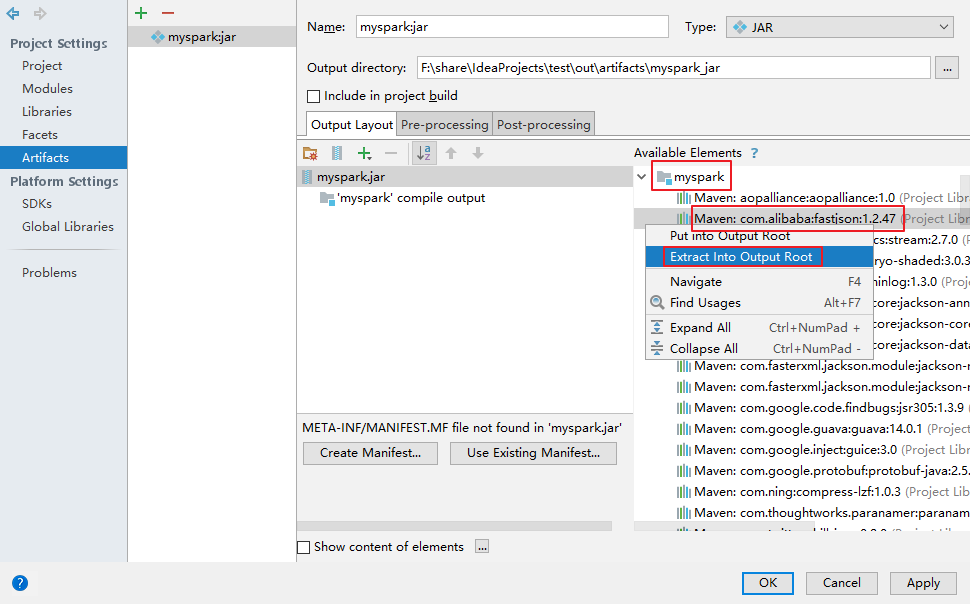
【导入完成】
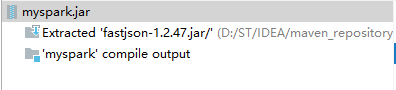
【构建 Jar 包】
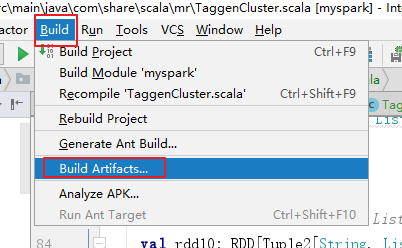
【得到 Jar 包】
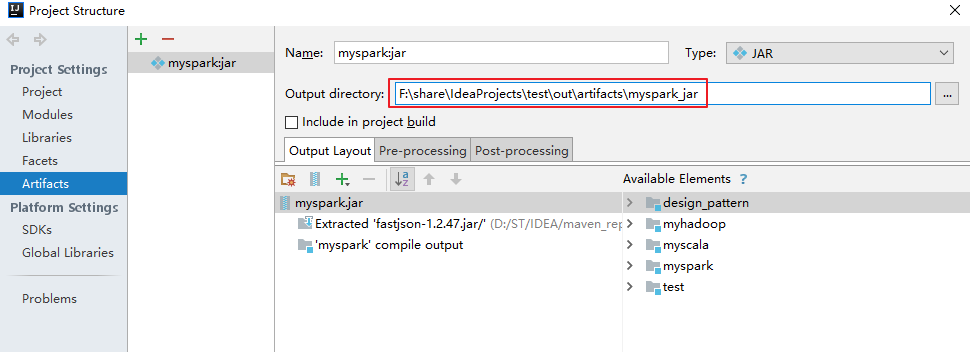

2. 运行程序
2.0 将 Jar 包传输到服务器
通过 Xftp 将 myspark.jar 传到服务器,过程略。
2.1 上传文件到 HDFS 中
hdfs dfs -put temptags.txt /user/centos
2.2 使用 spark-submit 提交应用(Scala)
spark-submit --class com.share.scala.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
2.3 使用 spark-submit 提交应用(Java)
spark-submit --class com.share.java.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
[Spark Core] 在 Spark 集群上运行程序的更多相关文章
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
- Eclipse提交代码到Spark集群上运行
Spark集群master节点: 192.168.168.200 Eclipse运行windows主机: 192.168.168.100 场景: 为了测试在Eclipse上开发的代码在Spa ...
- 在集群上运行Spark
Spark 可以在各种各样的集群管理器(Hadoop YARN.Apache Mesos,还有Spark 自带的独立集群管理器)上运行,所以Spark 应用既能够适应专用集群,又能用于共享的云计算环境 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
随机推荐
- 基于SpringBoot+SSM实现的Dota2资料库智能管理平台
Dota2资料库智能管理平台的设计与实现 摘 要 当今社会,游戏产业蓬勃发展,如PC端的绝地求生.坦克世界.英雄联盟,再到移动端的王者荣耀.荒野行动的火爆.都离不开科学的游戏管理系统,游戏管理系 ...
- 阿里巴巴java手册示例
package com.led.daorumysql; /** * @Description:alibaba java development manual * @author 86157 * */ ...
- C#生成带Logo二维码
1.下载ThoughtWorks.QRCode引用并添加在工程中2.在实现类QRCodeEncoderDemo中引入Dll,添加方法 using System; using System.Collec ...
- 使用IcoMoon生成图标字体
就我个人而言,往往要想找点什么ICON素材啊,往往都是酱婶滴,先去FontAwesome(在线图标字体库,但资源有限)里面巴拉巴拉,或者其他资源看看有没有合适的.如果没有就去求助我们大UI,笑笑给我来 ...
- Java maven项目的小随笔
1.web.xml里面有filter拦截设置,注意. 2.编译之后,网页中读取资源的路径是apache-tomcat/wtpwebapps/..,若该路径下没有相应资源,则报404错误.
- Microsoft Office MIME Types
经常需要查找Microsoft Office MIME Types,终于在MSDN网上找到,摘录如下,以备查阅与参考:http://blogs.msdn.com/b/vsofficedeveloper ...
- Spring源码分析:Bean加载流程概览及配置文件读取
很多朋友可能想看Spring源码,但是不知道应当如何入手去看,这个可以理解:Java开发者通常从事的都是Java Web的工作,对于程序员来说,一个Web项目用到Spring,只是配置一下配置文件而已 ...
- Java基本数据类型总结(转载)
Java基本数据类型总结 基本类型,或者叫做内置类型,是JAVA中不同于类的特殊类型.它们是我们编程中使用最频繁的类型.java是一种强类型语言,第一次申明变量必须说明数据类型,第一次变量赋值称为变量 ...
- git 提交规范
git 提交规范 前言 无规矩不成方圆,编程也一样. 如果你有一个项目,从始至终都是自己写,那么你想怎么写都可以,没有人可以干预你.可是如果在团队协作中,大家都张扬个性,那么代码将会是一团糟,好好的项 ...
- 【Tomcat】部署Web到tomcat的四种方式
一.静态部署 1.直接将web项目文件件拷贝到webapps 目录中 Tomcat的Webapps目录是Tomcat默认的应用目录,当服务器启动时,会加载所有这个目录下的应用.所以可以将JSP ...