Java爬取校内论坛新帖
Java爬取校内论坛新帖
为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法。
嗯,这次就选Java。
第三方库准备
- Jsoup
Jsoup是一款比较好的Java版HTML解析器。可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
- mysql-connector-java
mysql-connector-java是java JDBC的MySQL驱动,可以提供方便统一的接口来操纵MySQL数据库
爬虫步骤
- 目标分析
- 爬取网页
- 解析网页
- 存储数据
目标分析
博主爬取的是浙大的cc98论坛,需要内网才能上,新帖会在其中一个版面内出现,界面大概是这样:
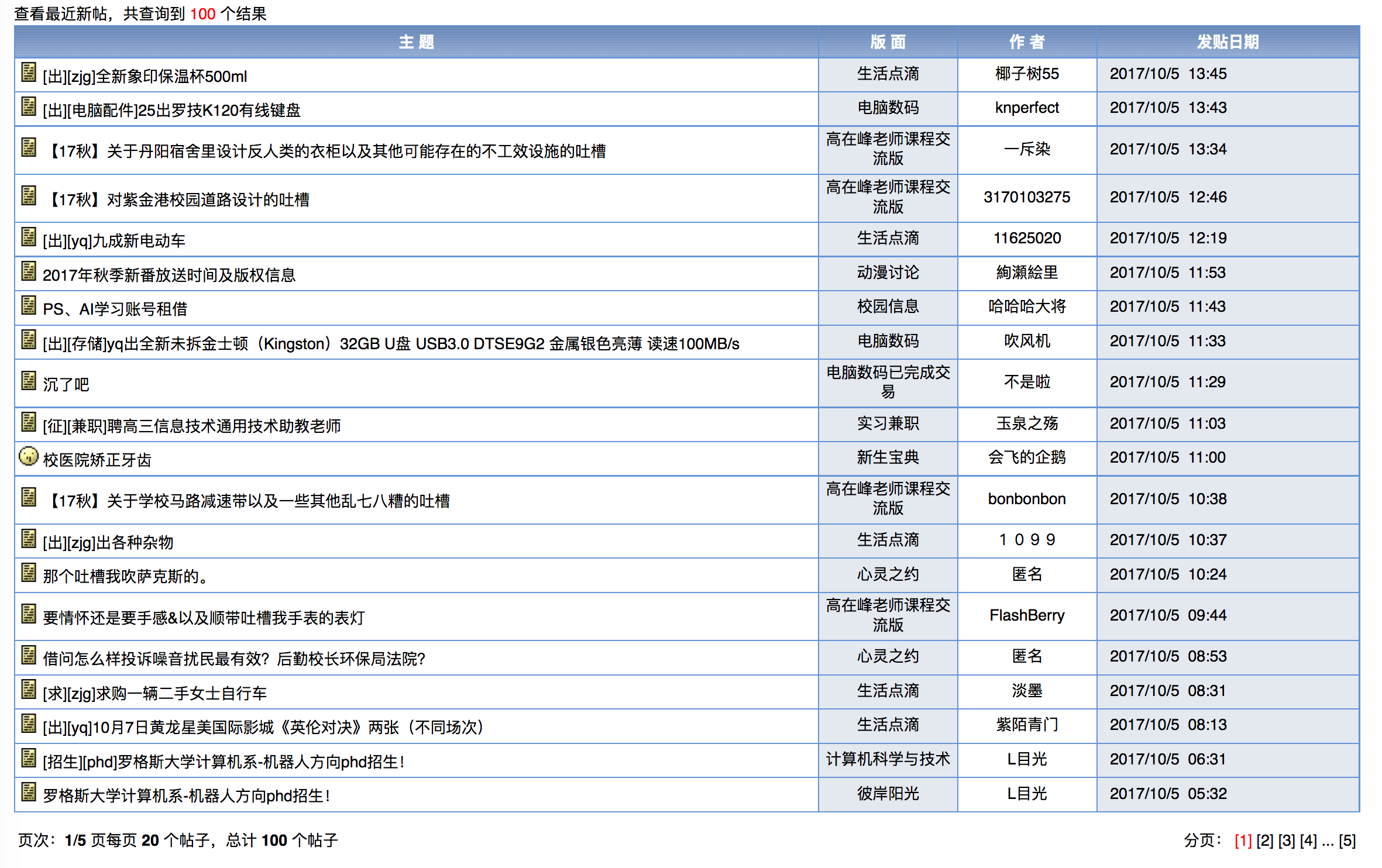
分析一下之后,发现100条新帖一共有5页,内容呈现在一张表格上。
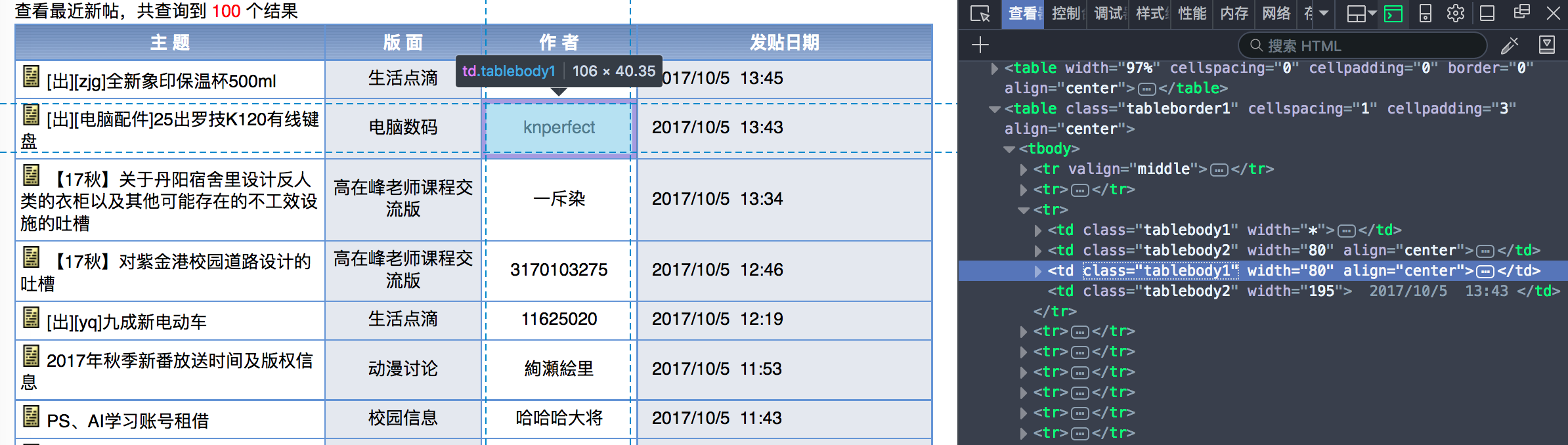
再用Firefox分析一下页面,发现是一个class="tableborder1"的table下有20行记录,每一行有4个td,爬虫只要获取这四个td数据就可以了。
爬取网页
由于这个网站是要用用户名和密码登录的,博主一开始都在使用POST方法,后来用Firefox抓包分析之后,才发现可以使用带cookies的GET方法登录。
private void getDoc(String url, String page)
{
try
{
//获取网页
this.doc = Jsoup.connect(url)
.cookie("aspsky", "***")
.cookie("BoardList","BoardID=Show")
.cookie("owaenabled","True")
.cookie("autoplay","True")
.cookie("ASPSESSIONIDSSCBSSCR","***")
.data(" stype","3")
.data("page",page) //Page就是1-5页
.get();
}
catch (IOException e)
{
e.printStackTrace();
throw new RuntimeException();
}
}
这里使用到的Jsoup很强大,其实还可以添加header之类的作修饰,但博主发现只要加了cookies之后就能成功访问了。
解析网页
根据目标分析的结果,我们可以开始解析HTML文档,同样地,Jsoup允许使用JQuery方法来解析,十分方便
private void parse()
{
//采用JQuery CSS选择
Elements rows = doc.select(".tableborder1 tr");
//去掉表头行
rows.remove(0);
for(Element row : rows)
{
String theme = row.select("td:eq(0) a:eq(1)").text().trim();
String url = "http://www.cc98.org/"
+ row.select("td:eq(0) a:eq(1)").attr("href");
String part = row.select("td:eq(1) a").text().trim();
String author = row.select("td:eq(2) a").text().trim();
if(author.length()==0)
{
author = "匿名";
}
String rawTime = row.select("td:eq(3)").text().
replace("\n","")
.replace("\t","");
try
{
Date publishTime = sdf.parse(rawTime);
System.out.println(publishTime+" "+theme);
System.out.println("---------------------------------------------------------");
storage.store(theme,publishTime,part,author,url);
}
catch (ParseException e)
{
e.printStackTrace();
}
}
}
存储数据
为了方便日后的分析(博主还打算偶尔分析一下各个版面的活跃情况),我们要把数据存储到硬盘上,这里选用了jdbc连接MySQL
public void store(String theme, Date publishTime,
String part, String author,
String url)
{
try
{
String sql = "INSERT INTO news (theme," +
"publishTime,part,author,url)VALUES(?,?,?,?,?)";
//使用预处理的方法
PreparedStatement ps = null;
ps = conn.prepareStatement(sql);
//依次填入参数
ps.setString(1,theme);
java.sql.Time time = new java.sql.Time(publishTime.getTime());
//这里使用数据库的时间戳
ps.setTimestamp(2,new Timestamp(publishTime.getTime()));
ps.setString(3,part);
ps.setString(4,author);
ps.setString(5,url);
ps.executeUpdate();
}
catch (SQLException e)
{
//主要是重复的异常,在MySQL中已经有约束unique
// e.printStackTrace();
}
}
我们可以通过MySQL可视化工具查看结果,由于MySQLworkbench不太好用,博主使用了DBeaver,结果如下:
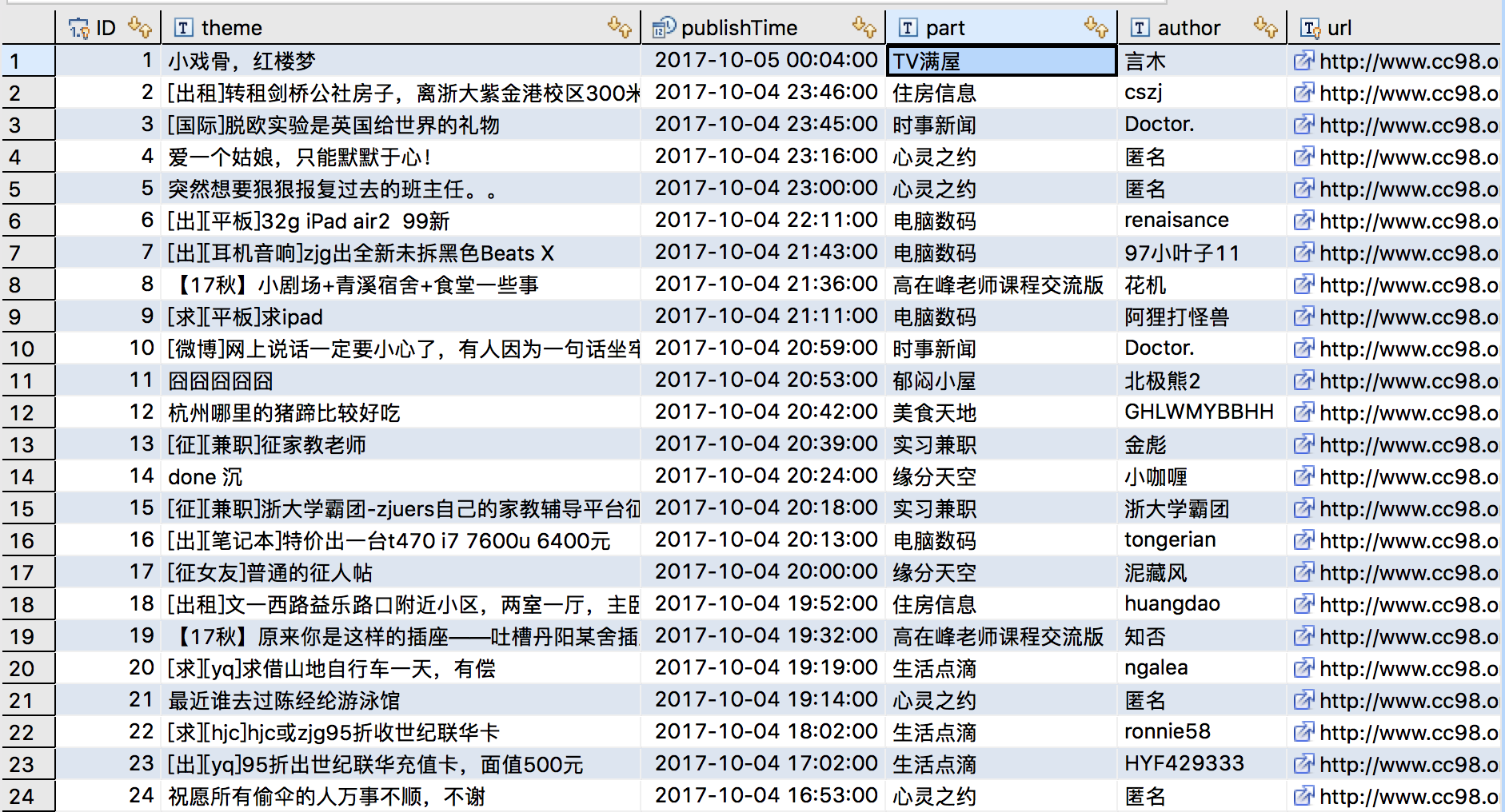
结果非常令人满意。
完整代码
Spider.java
package com.company;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Spider
{
private Document doc;
//定义时间格式
private SimpleDateFormat sdf = new SimpleDateFormat( " yyyy/MM/dd HH:mm " );
Storage storage = new Storage();
private void getDoc(String url, String page)
{
try
{
//获取网页
this.doc = Jsoup.connect(url)
.cookie("aspsky", "***")
.cookie("BoardList","BoardID=Show")
.cookie("owaenabled","True")
.cookie("autoplay","True")
.cookie("ASPSESSIONIDSSCBSSCR","***")
.data(" stype","3")
.data("page",page)
.get();
}
catch (IOException e)
{
e.printStackTrace();
throw new RuntimeException();
}
}
private void parse()
{
//采用JQuery CSS选择
Elements rows = doc.select(".tableborder1 tr");
//去掉表头行
rows.remove(0);
for(Element row : rows)
{
String theme = row.select("td:eq(0) a:eq(1)").text().trim();
String url = "http://www.cc98.org/"
+ row.select("td:eq(0) a:eq(1)").attr("href");
String part = row.select("td:eq(1) a").text().trim();
String author = row.select("td:eq(2) a").text().trim();
if(author.length()==0)
{
author = "匿名";
}
String rawTime = row.select("td:eq(3)").text().
replace("\n","")
.replace("\t","");
try
{
Date publishTime = sdf.parse(rawTime);
System.out.println(publishTime+" "+theme);
System.out.println("---------------------------------------------------------");
storage.store(theme,publishTime,part,author,url);
}
catch (ParseException e)
{
e.printStackTrace();
}
}
}
public void run(String url)
{
for (Integer i = 1; i<=5; i++)
{
getDoc(url, i.toString());
parse();
}
storage.close();
}
public static void main(String[] args)
{
Spider spider = new Spider();
spider.run("http://www.cc98.org/queryresult.asp?stype=3");
}
}
Storage.java
package com.company;
import java.sql.*;
import java.util.Date;
public class Storage {
//数据库连接字符串,cc98为数据库名
private static final String URL="jdbc:mysql://localhost:3306/cc98?characterEncoding=utf8&useSSL=false";
//登录名
private static final String NAME="***";
//密码
private static final String PASSWORD="***";
private Connection conn = null;
public Storage()
{
//加载jdbc驱动
try
{
Class.forName("com.mysql.jdbc.Driver");
}
catch (ClassNotFoundException e)
{
System.out.println("未能成功加载驱动程序,请检查是否导入驱动程序!");
e.printStackTrace();
}
try
{
conn = DriverManager.getConnection(URL, NAME, PASSWORD);
// System.out.println("获取数据库连接成功!");
}
catch (SQLException e)
{
// System.out.println("获取数据库连接失败!");
e.printStackTrace();
}
}
public void close()
{
//关闭数据库
if(conn!=null)
{
try
{
conn.close();
}
catch (SQLException e)
{
e.printStackTrace();
}
}
}
public void store(String theme, Date publishTime,
String part, String author,
String url)
{
try
{
String sql = "INSERT INTO news (theme," +
"publishTime,part,author,url)VALUES(?,?,?,?,?)";
//使用预处理的方法
PreparedStatement ps = null;
ps = conn.prepareStatement(sql);
//依次填入参数
ps.setString(1,theme);
java.sql.Time time = new java.sql.Time(publishTime.getTime());
//这里使用数据库的时间戳
ps.setTimestamp(2,new Timestamp(publishTime.getTime()));
ps.setString(3,part);
ps.setString(4,author);
ps.setString(5,url);
ps.executeUpdate();
}
catch (SQLException e)
{
//主要是重复的异常,在MySQL中已经有约束unique
// e.printStackTrace();
}
}
}
小结
这个项目其实涉及的知识点还挺多的,博主也刚学java,很多细节也没有很好吃透,如JDBC、Jsoup都值得好好学习一下。欢迎大家批评指正。
另,祝大家中秋国庆双节快乐~
Java爬取校内论坛新帖的更多相关文章
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
- 【Python】爬取理想论坛单帖爬虫
代码: # 单帖爬虫,用于爬取理想论坛帖子得到发帖人,发帖时间和回帖时间,url例子见main函数 from bs4 import BeautifulSoup import requests impo ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
随机推荐
- 最新版谷歌浏览器的Flash设置已经不能保存了?
解决方法:先去chrome实验室界面chrome://flags/#enable-ephemeral-flash-permission选择取消Disabled.取消该实验室选项. 然后去chrome: ...
- CentOS安装CAS 5.3.4服务端
1.安装jdk1.8 https://www.cnblogs.com/kgdxpr/p/6824093.html 2.安装tomcat8 3.安装maven https://www.cnblogs.c ...
- fputcsv导出大量数据
<?php set_time_limit(0); ini_set('memory_limit', '128M'); $fileName = date('YmdHis', time()); hea ...
- nginx 日志 cron任务切割日志
#vim cut_nginx_log.sh #cd /usr/local/nginx/logs/ #/bin/mv access.log access_$(date +%F).log #/usr/lo ...
- sed命令实现文件内容替换总结案例
sed -i "s@AAAAA@BBBBB@g" /home/local/payment-biz-service/env/test.txt sed -i "s#htxk. ...
- img没有src属性时自动出现边框
当img没有接收到src属性的时候会自动出现边框,border:0/none都不管用的情况下 解决方法 一行css 可以解决 img[src=""],img:not([src]){ ...
- Python学习(十六)—— 数据库
一.数据库介绍 数据库(Database,DB)是按照数据结构来组织.存储和管理数据的,并且是建立在计算机存储设备上的仓库. 数据库指的是以一定方式存储在一起.能为多个用户共享.具有尽可能小的冗余度. ...
- ELK使用2-Kibana使用
一.创建kibana索引 1.es索引可以在这儿查看 2.kibana创建索引可以在这儿查看(必须es中存在相应的索引才能在kibana中创建) 点击创建然后选择es中存在的索引即可创建相应的索引 3 ...
- Codeforces 1017F The Neutral Zone 数论
原文链接https://www.cnblogs.com/zhouzhendong/p/CF1017F.html 题目传送门 - CF1017F 题意 假设一个数 $x$ 分解质因数后得到结果 $x=p ...
- oracle数据入库出现空格问题
java做数据入库,不知为什么报如下图错误: debug发现数据是两位,如(FB),但是入库后发现FB后面多了两个空格,检查表发现类型声明是char(4),上网百度,说是char类型会自动补足.参考h ...