elasticsearch版本控制及mapping映射属性介绍
学习elasticsearch不仅只会操作,基本的运行原理我们还是需要进行了解,以下内容我讲对elasticsearch中的基本知识原理进行梳理,希望对大家有所帮助!
一、ES版本控制
1.Elasticsearch采用了乐观锁来保证数据的一致性,也就是说,当用户对document进行操作时,并不需要对该document做加锁和解锁的操作,只需要指定要操作的版本即可。当版本号一致时,elasticsearch会允许该操作顺利执行,而当版本号存在冲突时,elasticsearch会提示冲突并抛出异常(versionConfilctEngineException异常)。
2.Elasticsearch的版本号取值范围为1到2^63-1.
1、内部版本控制:
(1)使用的是_version 版本号要与文档的版本号一致
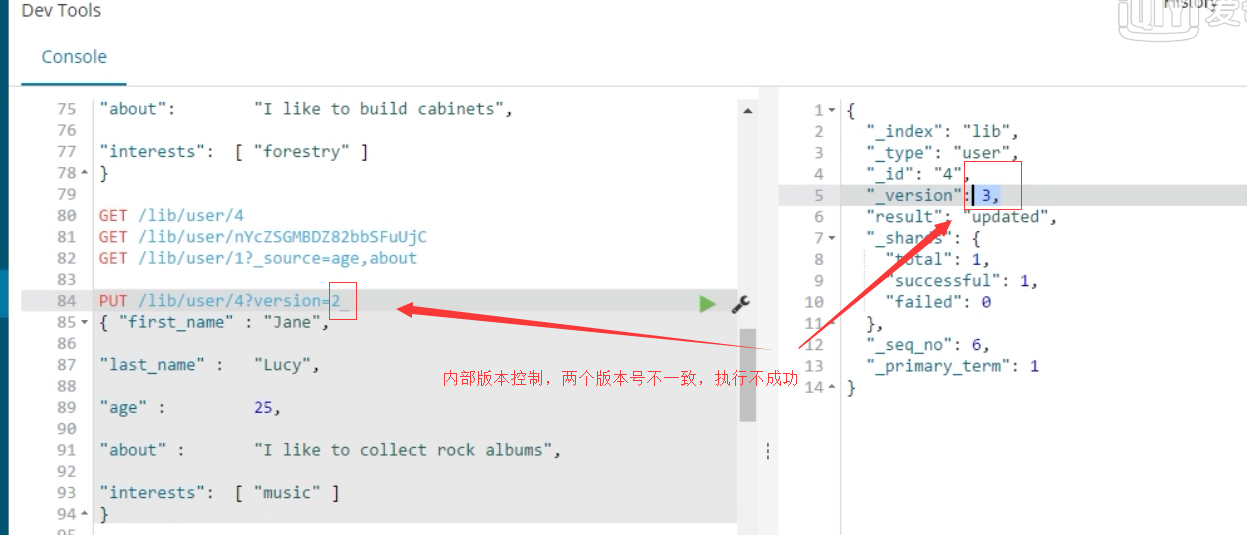
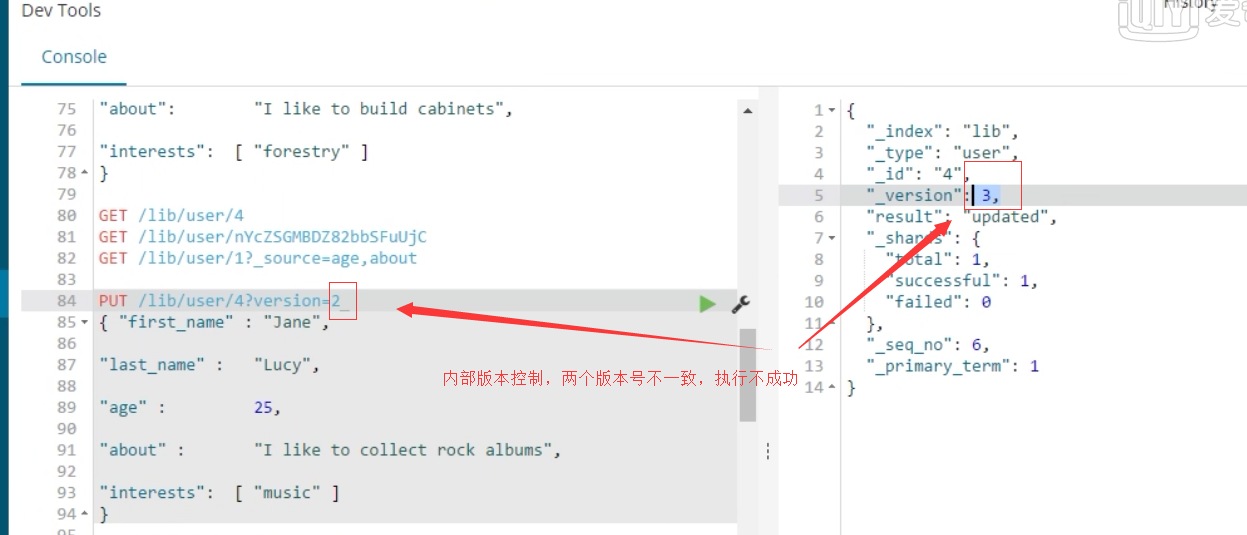
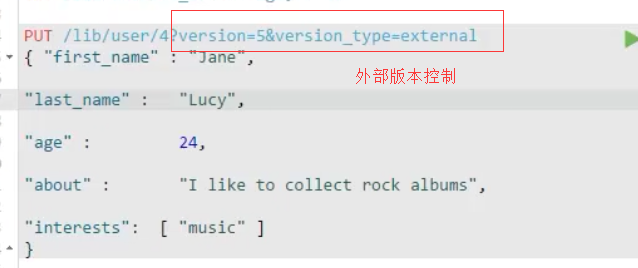
3.外部版本控制:elasticsearch在处理外部版本号时会对内部版本号的处理有些不同。他不在是检查_version是否与请求中指定的数值相同,而是检查当前的_version是否比指定的数值小。如果请求成功,那么外部的版本号就会被存储到文档中的_version中。
4.为保持_version与外部版本控制的数据一致,使用version_type=external
二、ES的mapping
1、核心数据类型(以下的数据类型与java的数据类型类似)
(1)字符型
①Text:被用来索引长文本,在建立索引前会将这项文本进行分词,转化为词的组合,建立索引。允许ES来检索这些词语。Text类型不能用来排序和聚合。
②Keyword:不需要进行分词,可以被用来检索过滤、排序和聚合。Keyword类型字段只能用本身来进行检索
(2)数字类型
①byte,short,integer,Long,double,float
(3)日期类型:date
(4)二进制类型:binary
2、Maping 支持的属性
"type" : "text", #是数据类型一般文本使用text(可分词进行模糊查询);keyword无法被分词(不需要执行分词器),用于精确查找
"analyzer" : "ik_max_word", #指定分词器,一般使用最大分词:ik_max_word
"normalizer" : "normalizer_name", #字段标准化规则;如把所有字符转为小写;具体如下举例
"boost" : 1.5, #字段权重;用于查询时评分,关键字段的权重就会高一些,默认都是1;另外查询时可临时指定权重
"coerce" : true, #清理脏数据:1,字符串会被强制转换为整数 2,浮点数被强制转换为整数;默认为true
"copy_to" : "field_name", #自定_all字段;指定某几个字段拼接成自定义;具体如下举例
"doc_values" : true, #加快排序、聚合操作,但需要额外存储空间;默认true,对于确定不需要排序和聚合的字段可false
"dynamic" : true, #新字段动态添加 true:无限制 false:数据可写入但该字段不保留 'strict':无法写入抛异常
"enabled" : true, #是否会被索引,但都会存储;可以针对一整个_doc
"fielddata" : false, #针对text字段加快排序和聚合(doc_values对text无效);此项官网建议不开启,非常消耗内存
"eager_global_ordinals": true, #是否开启全局预加载,加快查询;此参数只支持text和keyword,keyword默认可用,而text需要设置fielddata属性
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" ,#格式化 此参数代表可接受的时间格式 3种都接受
"ignore_above" : 100, #指定字段索引和存储的长度最大值,超过最大值的会被忽略
"ignore_malformed" : false ,#插入文档时是否忽略类型 默认是false 类型不一致无法插入
"index_options" : "docs" ,
# 4个可选参数
# docs(索引文档号),
# freqs(文档号 + 词频),
# positions(文档号 + 词频 + 位置,通常用来距离查询),
# offsets(文档号 + 词频 + 位置 + 偏移量,通常被使用在高亮字段)
# 分词字段默认是position,其他的默认是docs
"index" : true, #该字段是否会被索引和可查询 默认true
"fields": {"raw": {"type": "keyword"}} ,#可以对一个字段提供多种索引模式,使用text类型做全文检索,也可使用keyword类型做聚合和排序
"norms" : true, #用于标准化文档,以便查询时计算文档的相关性。建议不开启
"null_value" : "NULL", #可以让值为null的字段显式的可索引、可搜索
"position_increment_gap" : 0 ,#词组查询时可以跨词查询 既可变为分词查询 默认100
"properties" : {}, #嵌套属性,例如该字段是音乐,音乐还有歌词,类型,歌手等属性
"search_analyzer" : "ik_max_word" ,#查询分词器;一般情况和analyzer对应
"similarity" : "BM25",#用于指定文档评分模型,参数有三个:
# BM25 :ES和Lucene默认的评分模型
# classic :TF/IDF评分
# boolean:布尔模型评分
"store" : true, #默认情况false,其实并不是真没有存储,_source字段里会保存一份原始文档。
# 在某些情况下,store参数有意义,比如一个文档里面有title、date和超大的content字段,如果只想获取title和date
"term_vector" : "no" #默认不存储向量信息,
# 支持参数yes(term存储),
# with_positions(term + 位置),
# with_offsets(term + 偏移量),
# with_positions_offsets(term + 位置 + 偏移量)
# 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
3、复杂数据类型
(1)数组类型:数组类型不需要专门制定数组元素的type。例如:
①字符型数组:[“one”,”two”]
②整形数组:[1,2]
③数组型数组:[1,[2,3]]等价于[1,2,3]
④对象数组:[{“name”:”mary”,”age”:20},{“name”:”john”,”age”:10}]
(2)对象类型(Object datatype):_object_用于单个json对象
(3)嵌套类型(Nested datatype):_nested_ 用于json数组;
4、地理位置类型
(4)地理坐标类型(Geo-pint datatype):_geo_point_ 用于经纬度坐标:
(5)地理形状类型(Geo-shape datatype):_geo_shape_用于类似于多边形的复杂形状;
5、特定类型
(6)IPv4 类型(IPv4 datatype):ip 用于IPv4 地址
(7)Completion 类型(Completion datatype):completion 提供自动补全建议
(8)Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
(9)mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值
(10)附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等
下篇博客本人将记录使用elasticsearch查询的知识。若大家对本篇博客有所疑问或不同见解,欢迎大家进行评论。本人博客首页地址:https://home.cnblogs.com/u/chenyuanbo/
技术在于沟通交流!
elasticsearch版本控制及mapping映射属性介绍的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- elasticsearch中的mapping映射配置与查询典型案例
elasticsearch中的mapping映射配置与查询典型案例 elasticsearch中的mapping映射配置示例比如要搭建个中文新闻信息的搜索引擎,新闻有"标题".&q ...
- 四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字段的类型以及相关属性elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项, ...
- elasticsearch 权威指南Mapping(映射)
什么是映射 类似于数据库中的表结构定义,主要作用如下: 定义Index下字段名(Field Name) 定义字段的类型,比如数值型,字符串型.布尔型等 定义倒排索引的相关配置,比如是否索引.记录pos ...
- elasticsearch的mapping映射
Mapping简述 Elasticsearch是一个schema-less的系统,但并不代表no shema,而是会尽量根据JSON源数据的基础类型猜测你想要的字段类型映射.Elasticsearch ...
- Elasticsearch(八)【NEST高级客户端--Mapping映射】
要使用NEST与Elasticsearch进行交互,我们需要能够将我们的解决方案中的POCO类型映射到存储在Elasticsearch中的反向索引中的JSON文档和字段.本节介绍NEST中可用的所有不 ...
- Elasticsearch学习系列之mapping映射
什么是映射 为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成全文本(Full-text)或精确(Exact-value)的字符串值,Elasticsearch需要知道每个字段里面 ...
- Elasticsearch mapping映射文件设置没有生效
Elasticsearch mapping映射文件设置没有生效 问题背景 我们一般会预先创建 Elasticsearch index的 mapping.properties 文件(类似于MySQL中的 ...
- Elasticsearch索引的操作,利用kibana 创建/删除一个es的索引及mapping映射
索引的创建及删除 1. 通过索引一篇文档创建了一个新的索引 .这个索引采用的是默认的配置,新的字段通过动态映射的方式被添加到类型映射. 利用Kibana提供的DevTools来执行命令,要创建一个索引 ...
随机推荐
- TCP/IP 笔记 - DHCP和自动配置
动态主机配置协议(DHCP),一个局域网的网络协议,使用UDP协议工作,用于局域网中集中管理.分配IP地址. DHCP介绍 DHCP有两个主要部分组成:地址管理和配置数据交付.地址管理用于IP地址的动 ...
- 自己动手实现java数据结构(四)双端队列
1.双端队列介绍 在介绍双端队列之前,我们需要先介绍队列的概念.和栈相对应,在许多算法设计中,需要一种"先进先出(First Input First Output)"的数据结构,因 ...
- [TensorFlow] Introduction to TensorFlow Datasets and Estimators
Datasets and Estimators are two key TensorFlow features you should use: Datasets: The best practice ...
- JS读取服务器返回的XMl格式字符串
function PostSMS(phoneNumber, sessionID, requestUrl, successAction) { $.ajax( { type: 'POST', url: r ...
- LINQ 小项目【组合查询、分页】
使用 linq 在网页上对用户信息增删改,组合查询,分页显示 using System; using System.Collections.Generic; using System.Linq; us ...
- php 中的sprintf 坑
先说下为什么要写这个函数的前言,这个是我在看工作中发现一处四舍五入的bug后,当时非常不理解, echo sprintf('%.2f',123.455); //123.45 echo sprintf( ...
- 安装 kubernetes v1.11.1
kubernetes 版本 v1.11.1 系统版本:Centos 7.4 3.10.0-693.el7.x86_64 master: 192.168.0.205 node1: 192.168.0.2 ...
- csharp: sum columns or rows in a dataTable
DataTable dt = setData(); // Sum rows. //foreach (DataRow row in dt.Rows) //{ // int rowTotal = 0; / ...
- putty之pscp上传文件
控制台下打开pscp可执行文件 命令 >pscp -i 证书名 -r 要上传的文件 root@服务器路径:/opt
- Ubuntu16.04升级 Ubuntu18.04
1.更新资源 $ sudo apt-get update $ sudo apt-get upgrade $ sudo apt dist-upgrade 2.安装update-manager-core ...