四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1、映射(mapping)介绍
映射:创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项,mapping就是我们自己定义的字段数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
2、内置映射类型(也就是数据类型)
string类型:text,keyword两种
text类型:会进行分词,抽取词干,建立倒排索引
keyword类型:就是一个普通字符串,只能完全匹配才能搜索到
数字类型:long,integer,short,byte,double,float
日期类型:date
bool(布尔)类型:boolean
binary(二进制)类型:binary
复杂类型:object,nested
geo(地区)类型:geo-point,geo-shape
专业类型:ip,competion
3、属性介绍
store属性
index属性
null_value属性
analyzer属性
include_in_all属性
format属性

更多属性:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-boost.html
4、创建索引(相当于创建数据库)、创建表、创建字段-设置字段类型,添加数据
说明:

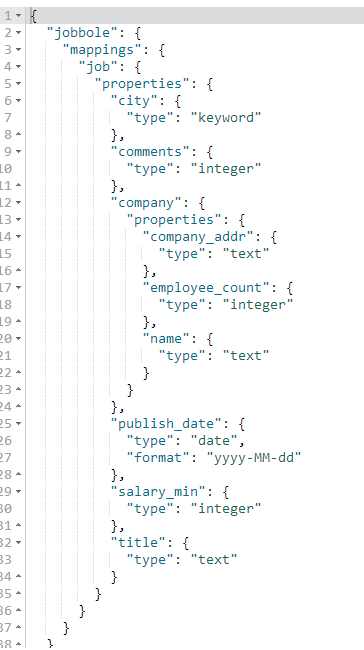
#创建索引(设置字段类型)
PUT jobbole #创建索引设置索引名称
{
"mappings": { #设置mappings映射字段类型
"job": { #表名称
"properties": { #设置字段类型
"title":{ #title字段
"type": "text" #text类型,text类型可以分词,建立倒排索引
},
"salary_min":{ #salary_min字段
"type": "integer" #integer数字类型
},
"city":{ #city字段
"type": "keyword" #keyword普通字符串类型
},
"company":{ #company字段,是嵌套字段
"properties":{ #设置嵌套字段类型
"name":{ #name字段
"type":"text" #text类型
},
"company_addr":{ #company_addr字段
"type":"text" #text类型
},
"employee_count":{ #employee_count字段
"type":"integer" #integer数字类型
}
}
},
"publish_date":{ #publish_date字段
"type": "date", #date时间类型
"format":"yyyy-MM-dd" #yyyy-MM-dd格式化时间样式
},
"comments":{ #comments字段
"type": "integer" #integer数字类型
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1 #索引名称/表/id
{
"title":"python分布式爬虫开发", #字段名称:字段值
"salary_min":15000, #字段名称:字段值
"city":"北京", #字段名称:字段值
"company":{ #嵌套字段
"name":"百度", #字段名称:字段值
"company_addr":"北京市软件园", #字段名称:字段值
"employee_count":50 #字段名称:字段值
},
"publish_date":"2017-4-16", #字段名称:字段值
"comments":15 #字段名称:字段值
}
代码:
#创建索引(设置字段类型)
PUT jobbole
{
"mappings": {
"job": {
"properties": {
"title":{
"type": "text"
},
"salary_min":{
"type": "integer"
},
"city":{
"type": "keyword"
},
"company":{
"properties":{
"name":{
"type":"text"
},
"company_addr":{
"type":"text"
},
"employee_count":{
"type":"integer"
}
}
},
"publish_date":{
"type": "date",
"format":"yyyy-MM-dd"
},
"comments":{
"type": "integer"
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园",
"employee_count":50
},
"publish_date":"2017-4-16",
"comments":15
}
5、获取索引下的mappings映射字段类型
#获取一个索引下的所有表的mappings映射字段类型
GET jobbole/_mapping
#获取一个索引下的指定表的mappings映射字段类型
GET jobbole/_mapping/job
【重点】在创建索引时一旦给字段设置了类型后就不可修改了,如果必须要修改就的重新创建索引,所以在创建索引时就必须确定好字段类型
四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
随机推荐
- 剑指Offer——从尾到头打印链表
题目描述: 输入一个链表,从尾到头打印链表每个节点的值. 分析: 方法1:利用栈的性质,先从头到尾遍历链表每个节点的值存入栈中,最后一个一个出栈顺序便是从尾到头的. 方法2:直接从头到尾遍历链表存储节 ...
- numpy.random.random & numpy.ndarray.astype & numpy.arange
今天看到这样一句代码: xb = np.random.random((nb, d)).astype('float32') #创建一个二维随机数矩阵(nb行d列) xb[:, 0] += np.aran ...
- django--博客系统--后台管理
1.后台管理功能主要实现了,文章的添加与修改,以及富文本的使用 前端页面 母版 <!DOCTYPE html> <html lang="en"> <h ...
- json的相关操作
最近对json的操作不是很理解 定义: JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式. 它基于 ECMAScript (w3c制定的j ...
- MySQL数据库(5)- pymysql的使用、索引
一.pymysql模块的使用 1.pymysql的下载和使用 之前我们都是通过MySQL自带的命令行客户端工具mysql来操作数据库,那如何在python程序中操作数据库呢?这就需要用到pymysql ...
- MySQL 表操作 (Day40)
阅读目录 一.表介绍 二.创建表 三.查看表 四.修改表 五.删除表 六.操作表中的记录 一.表介绍 表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,则称为表 ...
- Linq To Object多字段组合唯一校验
1.第一种方式 if(partsSalesOrderTypes.GroupBy(entity => new { entity.Name, entity.Code }).Any(array =&g ...
- HDU - 1151 Air Raid (最小路径覆盖)
题意:给定一个有向无环图,求最少划分几条路径,使之能够覆盖所有点. 分析:这可以转化为DAG上的最小路径覆盖问题. 路径覆盖的定义:有向图中,路径覆盖就是在图中找一些路径,使之覆盖了图中的所有顶点,且 ...
- HDU - 3829 Cat VS Dog (二分图最大独立集)
题意:P个小朋友,每个人有喜欢的动物和讨厌的动物.留下喜欢的动物并且拿掉讨厌的动物,这个小朋友就会开心.问最多有几个小朋友能开心. 分析:对于每个动物来说,可能既有人喜欢又有人讨厌,那么这样的动物实际 ...
- bat脚本相关
前期准备: 将要执行的脚本名字生成到一个txt文件 首先进入dos运行程序的目录下:输入dir *.jmx /B>FileScript.txt 采用dir *.jmx>list.txt 如 ...