潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页
2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享
3,Queue 中存放的是所有的代理,我们要分离出可用的代理,所以再搞个队列,存放可用代理,
4,检测速度过慢,效率低,引入 gevent,猴子补丁 一次多个检测 5,将分离出的有用代理存入 mongodb
另开个进程操作 6, flask web 框架 , API接口,
7,调度,每次开启时先对数据库中的代理进行检测,

因为maogo db无法远程连接,所以改成了用 json 存数据到本地的方法,一样可以实现代理
configure 是配置文件,把免费代理的网址放入 parser_list 中,
可以放入多个免费代理的网址, url 由 for 循环生成,实现翻页的功能,
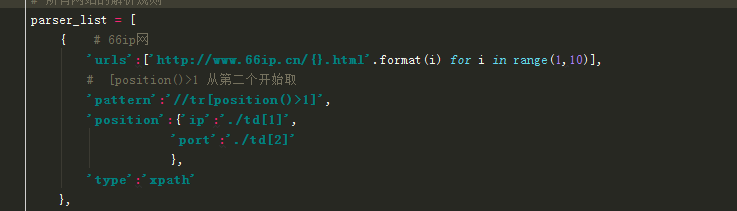
Parser 解析方法,由 configure 传过来的 type 判断是用 xpath 还是用 re 解析,
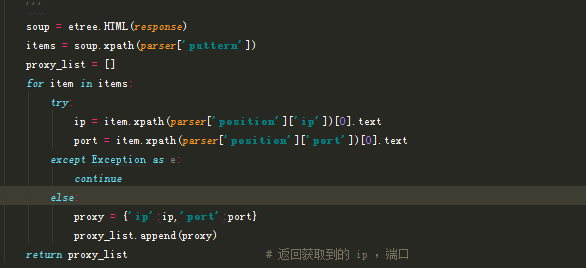
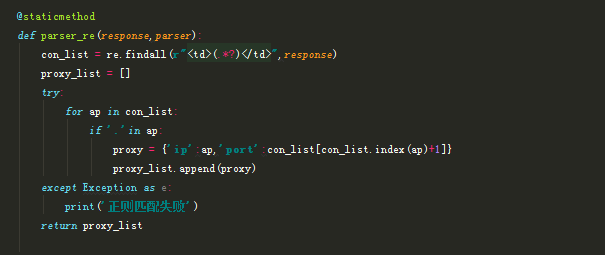
Server 在 flask 的基础上实现 API 接口,
spider_ 为运行的主程序,实现 ip ,端口的爬取,检测,存储,再检测再存储...
潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州学院-JavaVIP的Javascript的高级进阶-KeKe老师
潭州学院-JavaVIP的Javascript的高级进阶-KeKe老师 讲的不错,可以学习 下面是教程的目录截图: 下载地址:http://www.fu83.cn/thread-283-1-1.htm ...
- 潭州课堂25班:Ph201805201 爬虫基础 第一课 (课堂笔记)
爬虫的概念: 其实呢,爬虫更官方点的名字叫数据采集,英文一般称作spider,就是通过编程来全自动的从互联网上采集数据.比如说搜索引擎就是一种爬虫.爬虫需要做的就是模拟正常的网络请求,比如你在网站上点 ...
- 潭州课堂25班:Ph201805201 爬虫基础 第三课 urllib (课堂笔记)
Python网络请求urllib和urllib3详解 urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了url ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第四课 登录注册 (课堂笔记)
index.html 首页 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第三课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第二课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第一课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 潭州课堂25班:Ph201805201 第十课 类的定义,属性和方法 (课堂笔记)
类的定义 共同属性,特征,方法者,可分为一类,并以名命之 class Abc: # class 定义类, 后面接类名 ( 规则 首字母大写 ) cls_name = '这个类的名字是Abc' # 在类 ...
随机推荐
- selenium 操作复选框
场景 从上一节的例子中可以看出,webdriver可以很方便的使用findElement方法来定位某个特定的对象,不过有时候我们却需要定位一组对象, 这时候就需要使用findElements方法. 定 ...
- 关于C++ const 的全面总结 (转)
C++中的const关键字的用法非常灵活,而使用const将大大改善程序的健壮性,本人根据各方面查到的资料进行总结如下,期望对朋友们有所帮助. Const 是C++中常用的类型修饰符,常类型是指使用类 ...
- 微信如何获取unionid 并且打通微信公众号和小程序
准备 1.微信公众号 2.微信小程序 3.微信开发平台帐号 没有在开发平台绑定的小程序和公众号是没法获取unionid的 只需要在开发平台绑定小程序和公众号,便可以获取unionid 其中对于小程序和 ...
- Android SQLite用法
1.创建SQLite数据库 需要自己创建一个类来继承SQLiteOpenHelper类 SQLiteOpenHelper类是一个创建SQLite数据库的辅助类 继承此类的时候需要重写三个方法 publ ...
- 反序列化json的坑
json格式没有错误,内容没有什么异常 反序列化一直显示第一行有异常符号, 在https://jsonlint.com/上面检测了一下,发现了这个 解决办法: UTF-8格式编码 改成 UTF-8无B ...
- 创建Python虚拟环境
以window为例: 安装完python后, 打开cmd, 命令行输入: pip install virtualenv ,安装过程见截图 进入你想安装虚拟环境的目录, 命令行输入: virtualen ...
- 用servlet打内容到网页上
关键代码 response.setContentType("text/html;charset=UTF-8"); PrintWriter out=response.getWrite ...
- 统计各个数据库的各个数据表的总数,然后写入到excel中
1.最近项目基本进入最后阶段了,然后会统计一下各个数据库的各个数据表的数据量,开始使用的报表工具,report-designer,开源的,研究了两天,发现并不是很好使,最后自己下班回去,晚上思考,想着 ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- JDK1.7 Update14 HotSpot虚拟机GC收集器
在测试服务器上使用如下命令可以查看当前使用的 GC收集器,当然不止这一个命令可以看到,还有其他一些方式 第三列”=”表示第四列是参数的默认值,而”:=” 表明了参数被用户或者JVM赋值了 [csii@ ...