如何用快排思想在O(n)内查找第K大元素--极客时间王争《数据结构和算法之美》
前言
半年前在极客时间订阅了王争的《数据结构和算法之美》,现在决定认真去看看。看到如何用快排思想在O(n)内查找第K大元素这一章节时发现王争对归并和快排的理解非常透彻,讲得也非常好,所以想记录总结一下。文章内容主要分析归并排序和快速排序原理,并根据它们共同的分治思想,引出如何在 O(n) 的时间复杂度内查找一个无序数组中的第 K 大元素?
归并排序原理
核心思想:将数组从中间分成前后两部分,然后对前后两部分分别进行排序,再将排序好的两个部分有序合并在一起,这样整个数组有序。
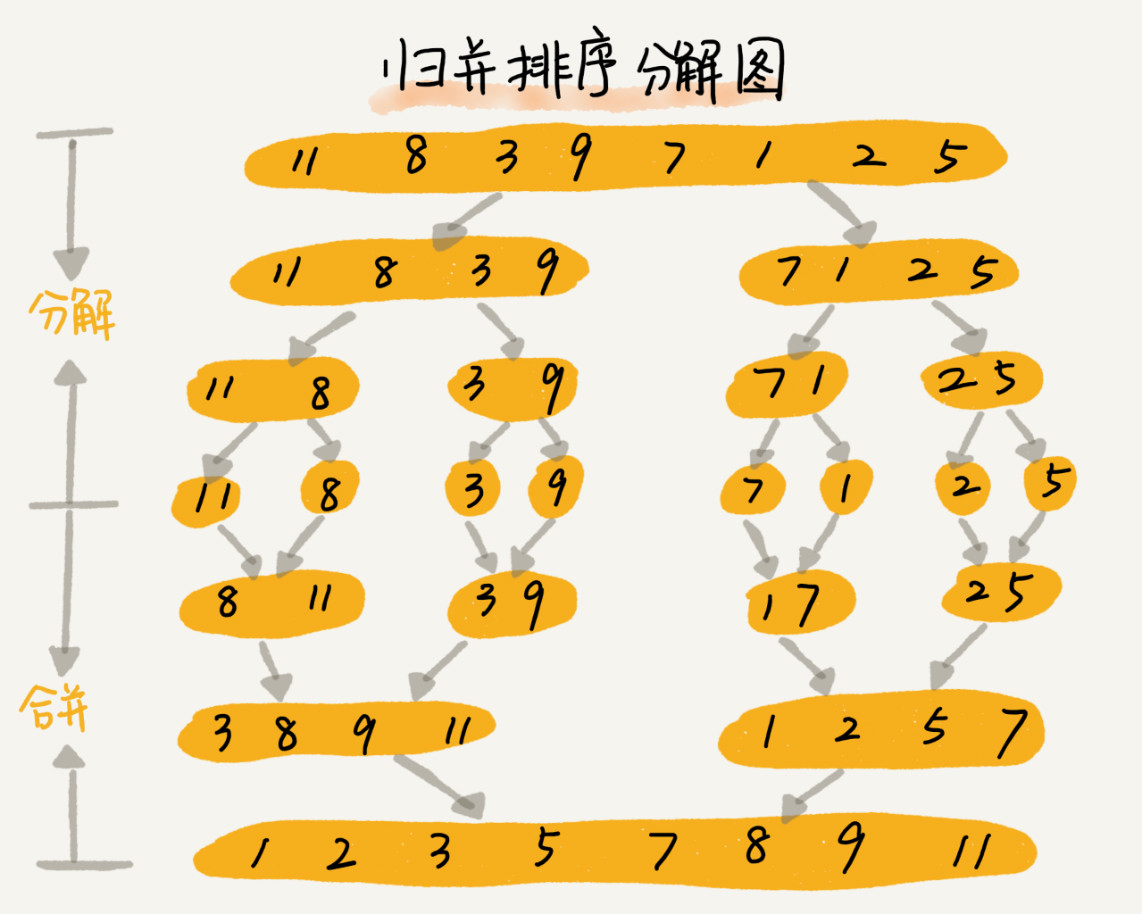
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,讲一个大的问题分解成小的问题来解决,小的问题解决了大的问题也就解决了。分治算法一般都是用递归来实现,分治是一种解决问题的处理思想,递归是一种编程技巧,两者并不冲突。以下重点讨论如何用递归代码来实现归并排序。下面是归并排序的递推公式。
递推公式:
merge_sort(p...r) = merge(merge_sort(p...q), merge_sort(q+...r)) 终止条件:
p >= r 不用继续分解
具体解释如下:
merge_sort(p...r) 表示给下标从 p 到 r 之间的数组排序。将这个排序问题转化为两个子问题 merge_sort(p...q) 和merge_sort(q+1...r),其中 q 为 p 和 r 的中间位置,即(p+r)/2。当前后两个子数组排好序之后,再将它们合并在一起,这样下标从 p 到 r 之间的数据也就排序好了。
C语言代码实现:
// 归并排序算法, A 是数组,n 表示数组大小
void mergeSort(int *a, int n){
mergeSortC(a, , n-);
} // 递归调用函数
void mergeSortC(int *a, int left, int right){
// 递归终止条件
if (left >= right)
return; int mid = left + (right - left)/;
mergeSortC(a, left, mid);
mergeSortC(a, mid+, right);
merge(a, left, mid, right);
} // 合并函数
void merge(int *a, int left, int mid, int right){
int i = left, j = mid+, k = ;
int *tmp = new int[right-left+]; // 申请一个大小为right-left+1临时数组
while (i <= mid && j <= right){
if(a[i] < a[j])
tmp[k++] = a[i++];
else
tmp[k++] = a[j++];
} while (i <= mid)
tmp[k++] = a[i++]; while (j <= right)
tmp[k++] = a[j++]; for (i=; i <= right-left; i++){
a[left+i] = tmp[i];
} delete[] tmp;
}
归并排序的时间复杂度任何情况下都是 O(nlogn),看起来非常优秀(快速排序最坏情况系时间复杂度也是 O(n2))。但归并排序并没有像快排那样应用广泛,因为它有一个致命的“弱点”,那就是归并排序不是原地排序算法。原因是合并函数需要借助额外的存储空间,空间复杂度为 O(n)。
C++实现:
void merge(std::vector<int>& a, int left, int mid, int right) {
int i = left;
int j = mid + ;
int k = ;
std::vector<int> v(right - left + );
while (i <= mid && j <= right) {
v[k++] = a[i] < a[j] ? a[i++] : a[j++];
}
while (i <= mid) {
v[k++] = a[i++];
}
while (j <= right) {
v[k++] = a[j++];
}
for (i = ; i < v.size(); ++i) {
a[left + i] = v[i];
}
}
void mergeSort(std::vector<int>& a, int left, int right) {
if (left >= right) return;
int mid = left + (right - left) / ;
mergeSort(a, left, mid);
mergeSort(a, mid+, right);
merge(a, left, mid, right);
}
void mergeSort(std::vector<int>& a) {
mergeSort(a, , a.size() - );
}
快速排序原理
核心思想:选取一个基准元素(pivot,比 pivot 小的放到左边,比 pivot 大的放到右边,对 pivot 左右两边的序列递归进行以上操作。
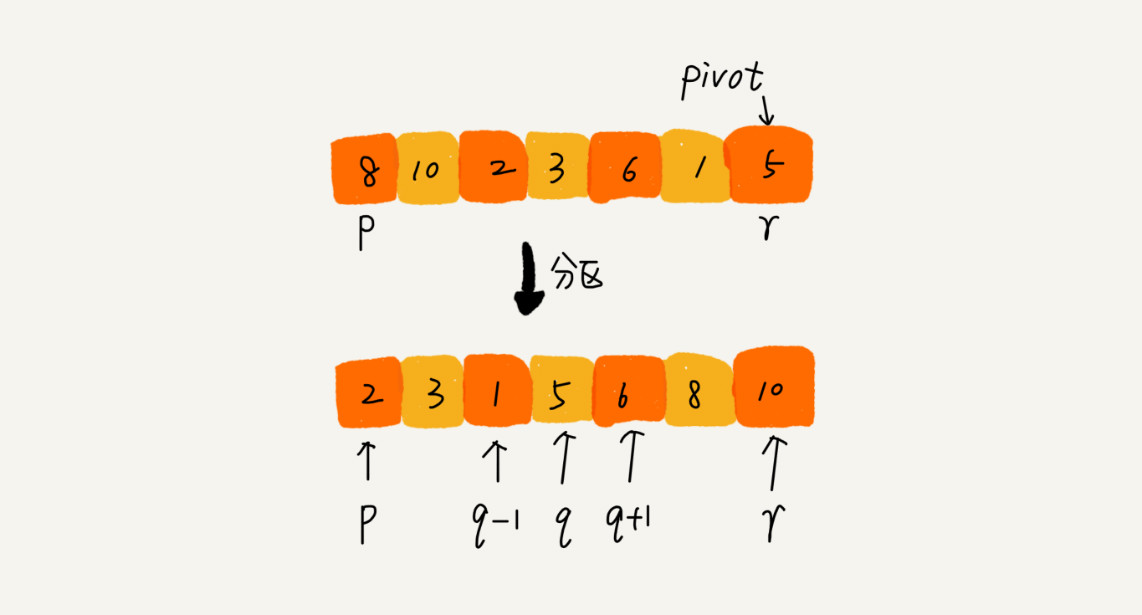
快速排序也是根据分治、递归的处理思想实现。地推公式如下:
递推公式:
quick_sort(p…r) = quick_sort(p…q-) + quick_sort(q+...r) 终止条件:
p >= r
C语言代码实现:
// 快速排序算法, A 是数组,n 表示数组大小
void quickSort(int *a, int n){
quickSortC(a, , n-);
} // 快排递归函数
void quickSortC(int *a, int left, int right){
// 递归终止条件
if (left >= right)
return;
// 获取分区点
int pivot = partition(a, left, right);
quickSortC(a, left, pivot-);
quickSortC(a, pivot+, right);
} /* 原地分区函数,非常巧妙,以a[right]为基准,运算结果
* 是i前面的元素都小于pivot,i后面的元素大于等于pivot */
int partition(int *a, int left, int right){
int pivot = a[right];
int i = left;
for (int j=left; j < right; j++){
if (a[j] < pivot){
swap(a[i], a[j]);
i++;
}
}
swap(a[i], a[right]);
return i;
}
快速排序的算法的平均时间复杂度是 O(nlogn),最坏时间复杂度是 O(n2),空间复杂度是O(1)。快速排序不是一个稳定的排序算法。
C++ 实现:
int partition(std::vector<int>& a, int left, int right) {
using std::swap;
int pivot = a[right];
int j = left;
for (int i = left; i < right; ++i) {
if (a[i] < pivot)
swap(a[i], a[j++]);
}
swap(a[right], a[j]);
return j;
}
void quickSort(std::vector<int>& a, int left, int right) {
if (left >= right) return;
int pivot = partition(a, left, right);
quickSort(a, left, pivot-);
quickSort(a, pivot+, right);
}
void quickSort(std::vector<int>& a) {
quickSort(a, , a.size() - );
}
归并排序和快速排序的区别
快排和归并用的都是分治思想,递归公式和代码都非常相似,但它们的区别在哪里呢?
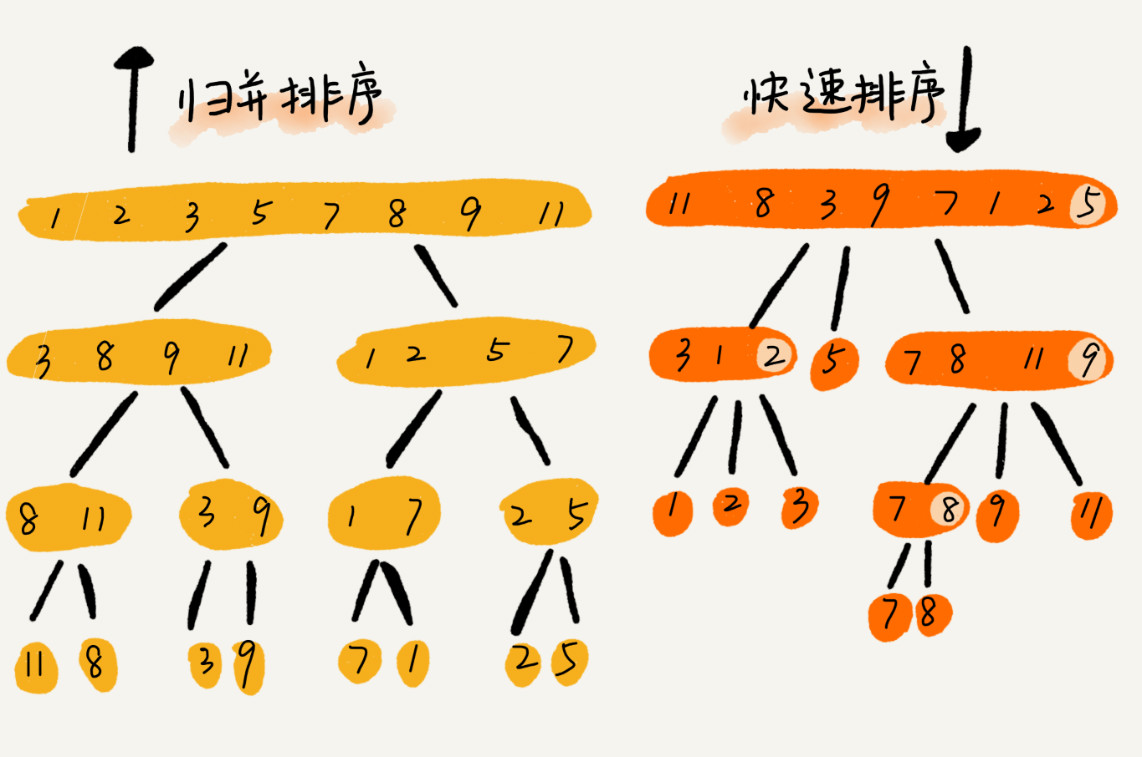
由上图可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后合并。而快排正好相反,其处理过程是由上而下的,先分区,然后处理子问题。归并排序虽然是稳定的,时间复杂度是 O(nlogn)的排序算法,但它是非原地排序算法。快排通过设计巧妙的原地分区函数,可以实现原地排序,解决归并排序占用太多内存的问题。
第 K 大元素
快排核心思想就是分治和分区,我们可以利用分区的思想来求解开篇问题: O(n)时间复杂度内求无序数组中的第 K 大元素。
C语言代码实现:
// top K 算法, A 是数组,n 表示数组大小,k 表示第 k 大
int getTopK(int *a, int n, int k){
if (a == nullptr || n < k)
return -; return topK(a, , n-, k);
} int topK(int *a, int left, int right, int k){
int p = partition(a, left, right);
if (k == p+)
return a[p]; if(k < p+)
return topK(a, left, p-, k);
else
return topK(a, p+, right, k);
} /* 原地分区函数,非常巧妙,以a[right]为基准,运算结果
* 是i前面的元素都大于pivot,i后面的元素小于于等于pivot */
int partition(int *a, int left, int right){
int pivot = a[right];
int i = left;
for (int j=left; j < right; j++){
if (a[j] > pivot){
swap(a[i], a[j]);
i++;
}
}
swap(a[i], a[right]);
return i;
}
LeetCode 215 C++实现:
class Solution {
public:
int partition(vector<int>& nums, int left, int right) {
using std::swap;
int pivot = nums[right];
int j = left;
for (int i = left; i < right; ++i) {
if (nums[i] > pivot)
swap(nums[i], nums[j++]);
}
swap(nums[right], nums[j]);
return j;
}
int getTopK(vector<int>& nums, int left, int right, int k) {
if (left >= right) return nums[left];
int pivot = partition(nums, left, right);
if (pivot + == k)
return nums[pivot];
return (pivot + < k) ? getTopK(nums, pivot+, right, k)
: getTopK(nums, left, pivot-, k);
}
int findKthLargest(vector<int>& nums, int k) {
return getTopK(nums, , nums.size() - , k);
}
};
如何用快排思想在O(n)内查找第K大元素--极客时间王争《数据结构和算法之美》的更多相关文章
- 基于快排思想的第(前)k大(小)
算法思路就是根据快排的partition,先随机选择一个分隔元素(或a[0]),将数组分为[小于a[p]的元素] a[p] [大于a[p]的元素],如果这时候n-p+1等于k的话,a[p]就是所求的第 ...
- 2018.4.24 快排查找第K大
import java.util.Arrays; /* 核心思想:利用快排思想,先假定从大到小排序,找枢纽,枢纽会把大小分开它的两边,当枢纽下标等于k时, 即分了k位在它左边或右边,也就是最大或最小的 ...
- 基于快速排序思想partition查找第K大的数或者第K小的数。
快速排序 下面是之前实现过的快速排序的代码. function quickSort(a,left,right){ if(left==right)return; let key=partition(a, ...
- 算法导论学习之线性时间求第k小元素+堆思想求前k大元素
对于曾经,假设要我求第k小元素.或者是求前k大元素,我可能会将元素先排序,然后就直接求出来了,可是如今有了更好的思路. 一.线性时间内求第k小元素 这个算法又是一个基于分治思想的算法. 其详细的分治思 ...
- HDU 5696 ——区间的价值——————【线段树、快排思想】
区间的价值 Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Subm ...
- Hints of sd0061(快排思想)
Hints of sd0061 Time Limit: 5000/2500 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others ...
- java快排思想
1分治思想 1.1比大小在分区 1.2从数组中取出一个数做基准数 1.3将比他小的数全放在他的左边,比他大的数全放在他的右边 1.4然后递归 左边 和右边 }
- 无序数组中用 快速排序的分治思想 寻找第k大元素
#include <stdio.h> int *ga; int galen; void print_a(){ ; i < galen; i++){ printf("%d & ...
- 数组第K小数问题 及其对于 快排和堆排 的相关优化比较
题目描述 给定一个整数数组a[0,...,n-1],求数组中第k小数 输入描述 首先输入数组长度n和k,其中1<=n<=5000, 1<=k<=n 然后输出n个整形元素,每个数 ...
随机推荐
- JavaStript基础 —— JavaStript语法
JavaStript 简介 JavaScript诞生于 1995年.当然,它的主要目的是处理以前由服务器端语言负责的一些输入验证操作. 如今,JavaStript的用途早就不再局限于简单的数据验证,而 ...
- 【Python之路】特别篇--Bottle
Bottle Bottle是一个快速.简洁.轻量级的基于WSIG的微型Web框架,此框架只由一个 .py 文件,除了Python的标准库外,其不依赖任何其他模块. Bottle框架大致可以分为以下部分 ...
- Shell登陆
Shell登录信息 注:只对本地终端起作用,远程终端不起作用(也就是说这个文件对远程登录是无效的). 修改后: 输出: 注:这里在配置文件中添加\l之后会显示终端(这里为终端1),按住Alt+F2可以 ...
- K8S中Service
Service 的概念Kubernetes Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务. 这一组 Pod 能够被 Serv ...
- webpack官方文档分析(三):Entry Points详解
1.有很多种方法可以在webpack的配置中定义entry属性,为了解释为什么它对你有用,我们将展现有哪些方法可以配置entry属性. 2.单一条目语法 用法: entry: string|Array ...
- 欧拉函数(线性筛)(超好Dong)
欧拉函数:对于一个正整数n,小于n且和n互质的正整数(包括1)的个数,记作φ(n) . #include <bits/stdc++.h> using namespace std; cons ...
- AcWing:164. 可达性统计(拓扑排序 + 状态压缩算法)
给定一张N个点M条边的有向无环图,分别统计从每个点出发能够到达的点的数量. 输入格式 第一行两个整数N,M,接下来M行每行两个整数x,y,表示从x到y的一条有向边. 输出格式 输出共N行,表示每个点能 ...
- C++入门经典-例7.10-运算符的重载,重载加号运算符
1:曾经介绍过string类型的数据,它是C++标准模版库提供的一个类.string类支持使用加号“+”连接两个string对象.但是使用两个string对象相减确实非法的,其中的原理就是C++所提供 ...
- 标准C++常用头文件及描述
#include <algorithm> //STL 通用算法 #include <bitset> //STL 位集容器 #include <cctype> //字 ...
- JNI知识扩展
JNI(Java Native Interface,JAVA原生接口) 使用JNI可以使Java代码和其他语言写的代码(如C/C++代码)进行交互. 问:为什么要进行交互? |- 首先,Java语言提 ...