感知器做二分类的原理及python实现
本文目录:
1. 感知器
2. 感知器的训练法则
3. 梯度下降和delta法则
4. python实现
1. 感知器[1]
人工神经网络以感知器(perceptron)为基础。感知器以一个实数值向量作为输入,计算这些输入的线性组合,然后如果结果大于某个阈值,就输出1,否则输出-1(或0)。更精确地,如果输入为$x_1$到$x_n$,那么感知器计算的输出为:

其中,$w_i$是实数常量,叫做权值,用来决定输入$x_i$对感知器输出的贡献率。因为仅以一个阈值来决定输出,我们有时也把这种感知器叫做硬限幅感知器,当输出为1和-1时,也叫做sgn感知器(符号感知器)。
2. 感知器的训练法则[1]
感知器的学习任务是决定一个权向量,它可以是感知器对于给定的训练样例输出正确的1或-1。为得到可接受的权向量,一种办法是从随机的权值开始,然后反复应用这个感知器到每一个训练样例,只要它误分类样例就修改感知器的权值。重复这个过程,直到感知器正确分类所有的训练样例。每一步根据感知器训练法则(perceptron Iraining rule) 来修改权值:${w_{i + 1}} \leftarrow {w_i} + \Delta {w_i}$,其中$\Delta {w_i} = \eta (t - o){x_i}$,$\eta$是学习速率,用来缓和或者加速每一步调整权值的程度。

3. 梯度下降和delta法则[1]








4. python实现[2]
训练数据:总共500个训练样本,链接https://pan.baidu.com/s/1qWugzIzdN9qZUnEw4kWcww,提取码:ncuj
损失函数:均方误差(MSE)
代码如下:
import numpy as np
import matplotlib.pyplot as plt class hardlim():
def __init__(self, path):
self.path = path def file2matrix(self, delimiter):
fp = open(self.path, 'r')
content = fp.read() # content现在是一行字符串,该字符串包含文件所有内容
fp.close()
rowlist = content.splitlines() # 按行转换为一维表
# 逐行遍历
# 结果按分隔符分割为行向量
recordlist = [list(map(float, row.split(delimiter))) for row in rowlist if row.strip()]
return np.mat(recordlist) def drawScatterbyLabel(self, dataSet):
m, n = dataSet.shape
target = np.array(dataSet[:, -1])
target = target.squeeze() # 把二维数据变为一维数据
for i in range(m):
if target[i] == 0:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='blue', marker='o')
if target[i] == 1:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='red', marker='o') def buildMat(self, dataSet):
m, n = dataSet.shape
dataMat = np.zeros((m, n))
dataMat[:, 0] = 1
dataMat[:, 1:] = dataSet[:, :-1]
return dataMat def classfier(self, x):
x[x >= 0.5] = 1
x[x < 0.5] = 0
return x if __name__ == '__main__':
hardlimit = hardlim('testSet.txt') print('1. 导入数据')
inputData = hardlimit.file2matrix('\t')
target = inputData[:, -1]
m, n = inputData.shape
print('size of input data: {} * {}'.format(m, n)) print('2. 按分类绘制散点图')
hardlimit.drawScatterbyLabel(inputData) print('3. 构建系数矩阵')
dataMat = hardlimit.buildMat(inputData) alpha = 0.1 # learning rate
steps = 600 # total iterations
weights = np.ones((n, 1)) # initialize weights
weightlist = [] print('4. 训练模型')
for k in range(steps):
output = hardlimit.classfier(dataMat * np.mat(weights))
errors = target - output
print('iteration: {} error_norm: {}'.format(k, np.linalg.norm(errors)))
weights = weights + alpha*dataMat.T*errors # 梯度下降
weightlist.append(weights) print('5. 画出训练过程')
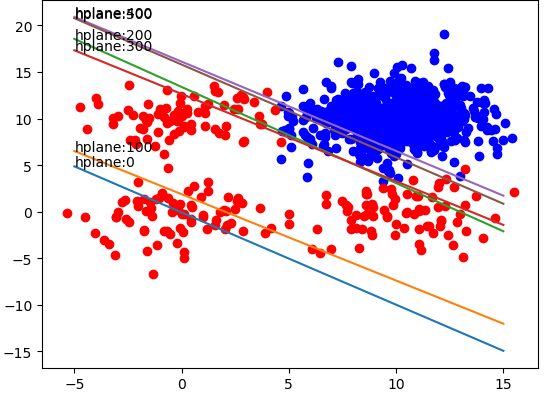
X = np.linspace(-5, 15, 301)
weights = np.array(weights)
length = len(weightlist)
for idx in range(length):
if idx % 100 == 0:
weight = np.array(weightlist[idx])
Y = -(weight[0] + X * weight[1]) / weight[2]
plt.plot(X, Y)
plt.annotate('hplane:' + str(idx), xy=(X[0], Y[0]))
plt.show() print('6. 应用模型到测试数据中')
testdata = np.mat([-0.147324, 2.874846]) # 测试数据
m, n = testdata.shape
testmat = np.zeros((m, n+1))
testmat[:, 0] = 1
testmat[:, 1:] = testdata
result = sum(testmat * (np.mat(weights)))
if result < 0.5:
print(0)
else:
print(1)
训练结果如下:
【参考文献】
《机器学习》Mitshell,第四章
《机器学习算法原理与编程实践》郑捷,第五章5.2.2
感知器做二分类的原理及python实现的更多相关文章
- softmax分类算法原理(用python实现)
逻辑回归神经网络实现手写数字识别 如果更习惯看Jupyter的形式,请戳Gitthub_逻辑回归softmax神经网络实现手写数字识别.ipynb 1 - 导入模块 import numpy as n ...
- 逻辑回归(Logistic Regression)二分类原理及python实现
本文目录: 1. sigmoid function (logistic function) 2. 逻辑回归二分类模型 3. 神经网络做二分类问题 4. python实现神经网络做二分类问题 1. si ...
- Python_sklearn机器学习库学习笔记(七)the perceptron(感知器)
一.感知器 感知器是Frank Rosenblatt在1957年就职于Cornell航空实验室时发明的,其灵感来自于对人脑的仿真,大脑是处理信息的神经元(neurons)细胞和链接神经元细胞进行信息传 ...
- 二、单层感知器和BP神经网络算法
一.单层感知器 1958年[仅仅60年前]美国心理学家FrankRosenblant剔除一种具有单层计算单元的神经网络,称为Perceptron,即感知器.感知器研究中首次提出了自组织.自学习的思想, ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- 人工神经网络(从原理到代码) Step 01 感知器 梯度下降
版权声明: 本文由SimonLiang所有,发布于http://www.cnblogs.com/idignew/.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 感知器 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- python之感知器-从零开始学深度学习
感知器-从零开始学深度学习 未来将是人工智能和大数据的时代,是各行各业使用人工智能在云上处理大数据的时代,深度学习将是新时代的一大利器,在此我将从零开始记录深度学习的学习历程. 我希望在学习过程中做到 ...
- 深度学习炼丹术 —— Taoye不讲码德,又水文了,居然写感知器这么简单的内容
手撕机器学习系列文章就暂时更新到此吧,目前已经完成了支持向量机SVM.决策树.KNN.贝叶斯.线性回归.Logistic回归,其他算法还请允许Taoye在这里先赊个账,后期有机会有时间再给大家补上. ...
随机推荐
- MyBatis-12-动态SQL
12.动态SQL 什么事动态SQL:动态SQL就是指根据不同的条件生成不同的SQL语句 利用动态SQL这一特性可以彻底摆脱这种痛苦 动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似 ...
- mybatis中foreach使用方法
作者:学无先后 达者为先 作者:偶尔记一下 foreach一共有三种类型,分别为List,[](array),Map三种. 下面表格是我总结的各个属性的用途和注意点. foreach属性 属性 描述 ...
- Java8-Stream-No.06
import java.io.IOException; import java.math.BigDecimal; import java.util.Arrays; import java.util.s ...
- Kafka中的消息是否会丢失和重复消费(转)
在之前的基础上,基本搞清楚了Kafka的机制及如何运用.这里思考一下:Kafka中的消息会不会丢失或重复消费呢?为什么呢? 要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费 ...
- Luogu P5048 [Ynoi2019模拟赛]Yuno loves sqrt technology III 分块
这才是真正的$N\sqrt{N}$吧$qwq$ 记录每个数$vl$出现的位置$s[vl]$,和每个数$a[i]=vl$是第几个$vl$,记为$P[i]$,然后预处理出块$[i,j]$区间的答案$f[i ...
- node 中的global对象和process对象
官方文档:http://nodejs.cn/api/ 因为Node.js是运行在服务区端的JavaScript环境,服务器程序和浏览器程序相比,最大的特点是没有浏览器的安全限制了,而且,服务器程序必须 ...
- codeforces700B
CF700B Connecting Universities 题意翻译 树之王国是一个由n-1条双向路连接着n个城镇的国家,任意两个城镇间都是联通的. 在树之王国共有2k所大学坐落于不同的城镇之中. ...
- async for 在爬虫中的使用例子
import asyncio import re import typing from concurrent.futures import Executor, ThreadPoolExecutor f ...
- Java终止线程的三种方式
停止一个线程通常意味着在线程处理任务完成之前停掉正在做的操作,也就是放弃当前的操作. 在 Java 中有以下 3 种方法可以终止正在运行的线程: 使用退出标志,使线程正常退出,也就是当 run() 方 ...
- SRS之SrsTsContext::encode_pes详解
1. SrsTsContext::encode_pes 该函数位于 srs_kernel_ts.cpp 中.下面的分析基于假设当前要封装的消息是视频. /* * @msg: 要写入到 ts 文件中的音 ...