梯度下降算法 Gradient Descent
梯度下降算法 Gradient Descent
梯度下降算法是一种被广泛使用的优化算法。在读论文的时候碰到了一种参数优化问题:
在函数\(F\)中有若干参数是不确定的,已知\(n\)组训练数据,期望找到一组参数使得残差平方和最小。通俗一点地讲就是,选择最合适的参数,使得函数的预测值与真实值最相符。
\]
其中,\(\hat{f}\)为真实值,\(f\)为测量值。在函数\(F\)中,存在n,m,p等参数,也存在自变量。训练数据给出了若干组自变量与真实值,算法需要找到合适的参数使得函数与训练数据相符。
这时就要用到今天的算法:梯度下降算法!
梯度下降算法的分类:
- 梯度下降算法 Batch Gradient Descent
- 随机梯度下降算法 Stochastic Gradient Descent
- 小批量梯度下降算法 Mini-batch Gradient Descent
梯度下降算法
在梯度下降算法中,我们根据梯度方向,迭代地调整参数。我们把所有参数(例如n,m,p之类的)打包进一个变量组\(\theta=\{n,m,p,..\}\),然后对这个变量组迭代更新;定义函数\(L=\sum_{i=1}^n (\hat{f}_i - f_i)^2\)为误差函数。
\]
其中,\(r\)为学习率。r的大小决定了参数移动的“步幅”,若r值过小,往往需要更长的时间才能算出结果;而值过大又可能导致无法得到最优值。
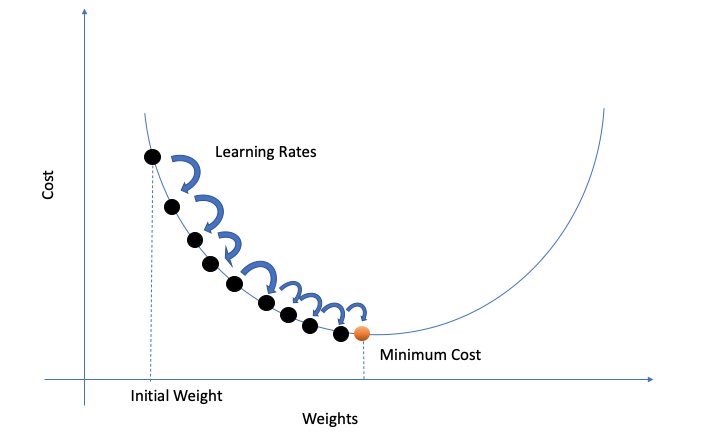
梯度的方向是函数增大最快的方向,那么梯度的反方向就是减小最快的方向。因此我们沿着梯度更小的方向进行参数更新可以有效地找到全局最优解。
def SGD(f, theta0, alpha, num_iters):
"""
Arguments:
f -- the function to optimize, it takes a single argument
and yield two outputs, a cost and the gradient
with respect to the arguments
theta0 -- the initial point to start SGD from
num_iters -- total iterations to run SGD for
Return:
theta -- the parameter value after SGD finishes
"""
theta = theta0
for iter in range(num_iters):
# For python 2.x - use xrange
grad = f(theta)[1]
# there is NO dot product ! return theta
theta = theta - r*(alpha * grad)
随机梯度下降算法
梯度下降算法看似已经解决了问题,但是还面临着“数据运算量过大”的问题。假设一下,我们现在有10000组训练数据,有10个参量,那么仅迭代一次就产生了10000*10=100000次运算。如果想让它迭代1000次的话,就需要10^8的运算量。显然易见,这个算法没法处理大规模的数据。
那么如何改进呢?在一次迭代中,将训练数据的量由“全体”改为“随机的一个”。这便是随机梯度下降算法(SGD)
优点:
打个比方,我们开发了一个新的软件,需要向100个用户收集体验数据并进行产品升级。在梯度下降方法中,我们会先向这100个用户挨个询问,然后进行一次优化;再挨个询问,再进行一次调整...在随机梯度下降方法中,我们会在询问完第一个用户之后就进行一次优化,然后拿着优化后的用户询问第二个客户,然后再优化;这样我们在完成一轮调查之后,就已经调整了100次!可以大大提高运行效率!
缺点:
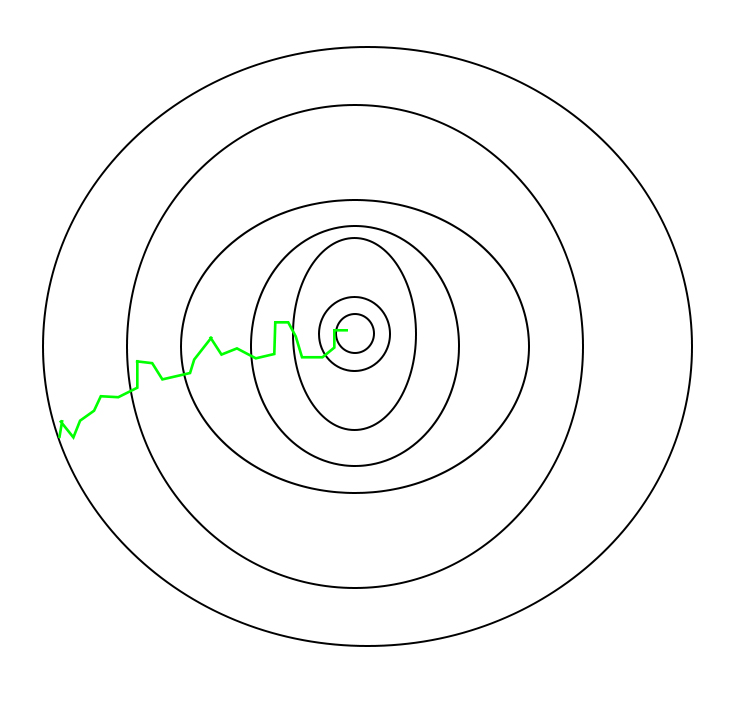
但是SGD在接近最优点之后很难稳定下来,而是在最优点附近徘徊,而难以到达最优。这一问题可以通到在后期适度降低学习率来解决。
并且由于随机性较大,所以下降的过程中较为曲折:
小批量梯度下降算法
小批量梯度下降算法则是吸收了前两者的优点。该算法存在一个变量Batch_size,指一次迭代中随机的选择多少的训练数据。如果Batch_size=n,就是梯度下降算法;如果Batch_size=1,就是随机梯度下降算法。
这样的小批量不仅可以减少计算的成本,还可以提高算法的稳定性。
梯度下降算法 Gradient Descent的更多相关文章
- 梯度下降算法(Gradient descent)GD
1.我们之前已经定义了代价函数J,可以将代价函数J最小化的方法,梯度下降是最常用的算法,它不仅仅用在线性回归上,还被应用在机器学习的众多领域中,在后续的课程中,我们将使用梯度下降算法最小化其他函数,而 ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- 梯度下降法Gradient descent(最速下降法Steepest Descent)
最陡下降法(steepest descent method)又称梯度下降法(英语:Gradient descent)是一个一阶最优化算法. 函数值下降最快的方向是什么?沿负梯度方向 d=−gk
随机推荐
- JVM中的堆
堆 内存结构 堆的核心概念 <java虚拟机规范>中对java堆的描述是:所有的对象实例以及数组都应当在运行时分配在堆上. 一个JVM实例只存在一个堆内存(就是new 出来一个对象),ja ...
- Vue学习之--------Vue中自定义插件(2022/8/1)
文章目录 1.插件的基本介绍 2.实际应用 2.1 目录结构 2.2 代码实例 2.2.1 学校组件(School.vue) 2.2.2 学生组件(Student.vue) 2.2.3 定义的插件 2 ...
- sql面试50题------(1-10)
文章目录 1.查询课程编号'01'比课程编号'02'成绩高的所有学生学号 2.查询平均成绩大于60分得学生的学号和平均成绩 3.查询所有学生的学号,姓名,选课数,总成绩 4.查询姓"猴&qu ...
- 表单快速启用城市地区功能 齐博x1齐博x2齐博x3齐博x4齐博x5齐博x6齐博x7齐博x8齐博x9齐博x10
比如分类系统\application\fenlei\config.php 修改这个文件,里边加入参数 'use_area'=>true, 那么会员中心与后台的,修改发布页面,都会自动加上城市地区 ...
- 各大厂 C/C++ 编程规范详解
来吧!各大厂知名规范体系~ 各有特点各有侧重~ Google C++ Style Guide Google C++ Style Guide,[中文版],简称 GSG,谷歌的 C++ 编程规范,在国内有 ...
- .Net Core redis 调用报错 '6000 Redis requests per hour' 解决 6000 此调用限制
问题描述 redis 是一种基于内存,性能高效的 NoSQL 数据库,性能高主要就体现在数据交互耗时较短,能够段时快速的对用户的请求做出反应,所以在业务比较复杂或交互量需求大时,必然会超过 6000次 ...
- 驱动开发:内核监控FileObject文件回调
本篇文章与上一篇文章<驱动开发:内核注册并监控对象回调>所使用的方式是一样的都是使用ObRegisterCallbacks注册回调事件,只不过上一篇博文中LyShark将回调结构体OB_O ...
- Python数据分析:实用向
文件处理 导包 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns ...
- HTML5和CSS3新特性
1.HTML5新标签和属性 1.1 兼容性前缀与语义化 兼容低版本的写法.比较新的浏览器,可以直接写.兼容性前缀,是每个浏览器私有的. 内核 兼容性前缀 浏览器 Gecko -moz- Firefox ...
- pinpoint部署
pinpoint是一个分析大型分布式系统的平台,提供解决方案来处理海量跟踪数据,主要面向基于tomcat的Java 应用. pinpoint使用HBASE储存数据. 下面介绍pinpoint部署及应用 ...