【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)
一、爬取老番茄B站数据
前几天开发了一个python爬虫脚本,成功爬取了B站李子柒的视频数据,共142个视频,17个字段,含:
视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕数,播放量,点赞数,投币量,收藏量,评论数,转发量,实时爬取时间
基于这个Python爬虫程序,我更换了up主的UID,把李子柒的uid换成了老番茄的uid,便成功爬取了老番茄的B站数据。共393个视频,17个字段,字段同上。
这里展示下爬取到的前20个视频数据:
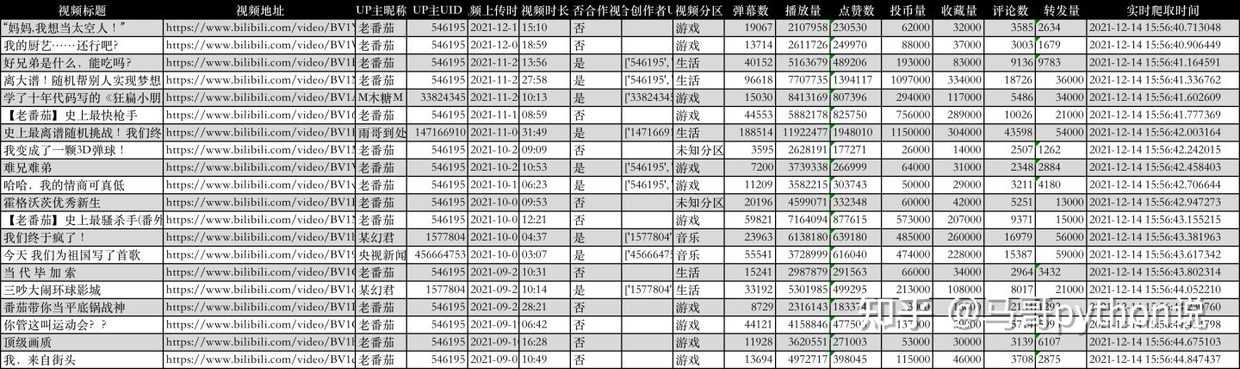
基于爬取的老番茄B站数据,用python做了以下基础数据分析的开发。
二、python数据分析
1、读取数据源
import pandas as pd
df = pd.read_excel('B站视频数据_老番茄.xlsx', parse_dates=['视频上传时间', '实时爬取时间']) # 读取excel数据
2、查看数据概况
df.head(3) # 查看前三行数据
df.shape # 查看形状,几行几列
df.info() # 查看列信息
df.describe() # 数据分析
df['是否合作视频'].value_counts() # 统计:是否合作视频
df['视频分区'].value_counts() # 统计:视频分区
3、查看异常值
df2 = df[['视频标题', '视频地址', '弹幕数', '播放量',
'点赞数', '投币量', '收藏量', '评论数', '转发量', '视频上传时间']] # 去掉不关心的列
df2.loc[df.评论数 == 0] # 评论数是0的数据
df2.isnull().any() # 空值
df2.duplicated().any() # 重复值
4.1、查看最大值(max函数)
df2.loc[df.播放量 == df['播放量'].max()] # 播放量最高的视频
df2.loc[df.弹幕数 == df['弹幕数'].max()] # 弹幕数最高的视频
4.2、查看最小值(min函数)
df2.loc[df.投币量 == df['投币量'].min()] # 投币量最小的视频
df2.loc[df.收藏量 == df['收藏量'].min()] # 收藏量最小的视频
5.1、查看TOP3的视频(nlargest函数)
df2.nlargest(n=3, columns='播放量') # 播放量TOP3的视频
df2.nlargest(n=3, columns='投币量') # 投币量TOP3的视频
5.2、查看倒数3的视频(nsmallest函数)
df2.nsmallest(n=3, columns='评论数') # 评论数倒数3的视频
df2.nsmallest(n=3, columns='转发量') # 转发量倒数3的视频
6、查看相关性
# 查看spearman相关性(得出结论:收藏量&投币量,相关性最大,0.98)
df2.corr(method='spearman')

7.1、可视化分析-plot
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 可视化效果不好
df2.plot(x='视频上传时间', y=['弹幕数', '播放量', '点赞数', '投币量', '收藏量', '评论数', '转发量'])
7.2、可视化分析-pyecharts
from pyecharts.charts import Line # 折线图所导入的包
from pyecharts import options as opts # 全局设置所导入的包
time_list = df2['视频上传时间'].astype(str).values.tolist()
line = (
Line() # 实例化Line
# 加入X轴数据
.add_xaxis(time_list)
# 加入Y轴数据
.add_yaxis("弹幕数", df2['弹幕数'].values.tolist())
.add_yaxis("播放量", df2['播放量'].values.tolist())
.add_yaxis("点赞数", df2['点赞数'].values.tolist())
.add_yaxis("投币量", df2['投币量'].values.tolist())
.add_yaxis("收藏量", df2['收藏量'].values.tolist())
.add_yaxis("评论数", df2['评论数'].values.tolist())
.add_yaxis("转发量", df2['转发量'].values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="老番茄B站数据分析"),
legend_opts=opts.LegendOpts(is_show=True),
)
# 全局设置项
)

至此,基础数据分析工作完成了。
三、同步讲解视频
逐行代码视频讲解:
https://www.zhihu.com/zvideo/1455460990275567616
by 马哥python说
【Python数据分析案例】python数据分析老番茄B站数据(pandas常用基础数据分析代码)的更多相关文章
- pandas数据分析案例
1.数据分析步骤 ''' 数据分析步骤: 1.先加载数据 pandas.read_cvs("path") 2.查看数据详情 df.info() ,df.describe() ,df ...
- 向大家介绍我的新书:《基于股票大数据分析的Python入门实战》
我在公司里做了一段时间Python数据分析和机器学习的工作后,就尝试着写一本Python数据分析方面的书.正好去年有段时间股票题材比较火,就在清华出版社夏老师指导下构思了这本书.在这段特殊时期内,夏老 ...
- 基于股票大数据分析的Python入门实战(视频教学版)的精彩插图汇总
在我写的这本书,<基于股票大数据分析的Python入门实战(视频教学版)>里,用能吸引人的股票案例,带领大家入门Python的语法,数据分析和机器学习. 京东链接是这个:https://i ...
- 【Python开发】Python中数据分析环境的搭建
注:无论是任何一门语言,刚开始入门的时候,语言运行环境的搭建都是一件不轻松的事情. Python的运行环境 要运行或写Python代码,就需要Python的运行环境,主要的Python有以下三类: 原 ...
- Python数据分析与挖掘所需的Pandas常用知识
Python数据分析与挖掘所需的Pandas常用知识 前言Pandas基于两种数据类型:series与dataframe.一个series是一个一维的数据类型,其中每一个元素都有一个标签.series ...
- [学习笔记] [数据分析] 01.Python入门
1.安装Python与环境配置 ① ② 安装pip以及利用pip安装Python库 2.Anaconda安装 conda list 要在root环境下 3.常用数据分析库 ① Numpy 安装:con ...
- 零基础学习Python web开发、Python爬虫、Python数据分析,从基础到项目实战!
随着大数据和人工智能的发展,目前Python语言的上升趋势比较明显,而且由于Python语言简单易学,所以不少初学者往往也会选择Python作为入门语言. Python语言目前是IT行业内应用最为广泛 ...
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
NoteBook of <Data Analysis with Python> 3.IPython基础 Tab自动补齐 变量名 变量方法 路径 解释 ?解释, ??显示函数源码 ?搜索命名 ...
- 01 学习数据分析的python库
网页爬取 1.requests 2.BeautifulSoup 3.Scrapy 科学计算与数据分析 1.scipy 2.numpy 3.pandas 机器学习和深度学习 1.Scikit-learn ...
随机推荐
- MariaDB 存储引擎一览(官方文档翻译)
inline-translate.translate { } inline-translate.translate::before, inline-translate.translate::after ...
- piwik安装部署
1.piwik介绍 Piwik是一个PHP和MySQL的开放源代码的Web统计软件,它给你一些关于你的网站的实用统计报告,比如网页浏览人数,访问最多的页面,搜索引擎关键词等等. Piwik拥有众多不同 ...
- js如何获取iframe页面内的对象
简单介绍iframe标签,所有的浏览器都支持<iframe>标签,iframe 元素会创建包含另外一个文档的内联框架(即行内框架).通常我们常用的iframe标签的属性有:width(if ...
- 每日学习--Kociemba魔方算法
由图可知19步还原魔方
- PAT B1081 检查密码
题目描述: 本题要求你帮助某网站的用户注册模块写一个密码合法性检查的小功能.该网站要求用户设置的密码必须由不少于6个字符组成,并且只能有英文字母.数字和小数点 .,还必须既有字母也有数字. 输入格式: ...
- flex布局图片和文字同级,文字过多导致图片变形问题
图片增加css样式即可 flex-grow: 0;flex-shrink: 0;
- SSM实现个人博客-day01
1.需求分析 项目源码免费下载:SSM实现个人博客 有问题请询问vx:kht808
- crm多对多
多对多要使用service.Associate传入两表的id和中间表的 service.Associate("invoice", entityReferenceInvoice.Id ...
- GopherCon SG 2019 "Understanding Allocations" 学习笔记
本篇是根据 GopherCon SG 2019 "Understanding Allocations" 演讲的学习笔记. Understanding Allocations: th ...
- SpringCloud分布式尝试记录
服务提供端: 客户消费端: