Python爬虫:为什么你爬取不到网页数据
前言:
之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发布一篇关于爬虫爬取不到数据文章,希望各位读者更加了解爬虫。

1. 最基础的爬虫
通常编写爬虫代码,使用如下三行代码就可以实现一个网页的基本访问了。
from urllib import request
rsp = request.urlopen(url='某某网站')
print(rsp.read().decode('编码'))
或者
import requests
rsp = requests.get(url='某某网站')
print(rsp.text)
但是,有的网站你使用上述方式访问时,有可能出现一下情况:
- 直接报错;
- 没有报错,但是给出相应的响应码,如403;
- 没有报错,但是输出信息没有在浏览器上看到的那么多(这有可能是网页使用了动态加载的原因)。
2. 添加请求头的爬虫
上述讲到的三种情况,怎样解决呢?基本方式是添加一个请求头(请求头的字段通常只需添加user-agent字段即可,用来模拟浏览器访问;然而有的网站用Python爬虫来访问时,可能还要添加其他字段,最好是把这个网页所有请求头字段信息全部添加上;有的网页全部请求头字段信息全部添加上,然而也访问不到数据,这种情况小编也没有什么好的解决办法,不知道使用selenium模块直接操控浏览器是否可以,没有试过)。
1.如用urllib模块来访问bilibili网站时会报错,如下:
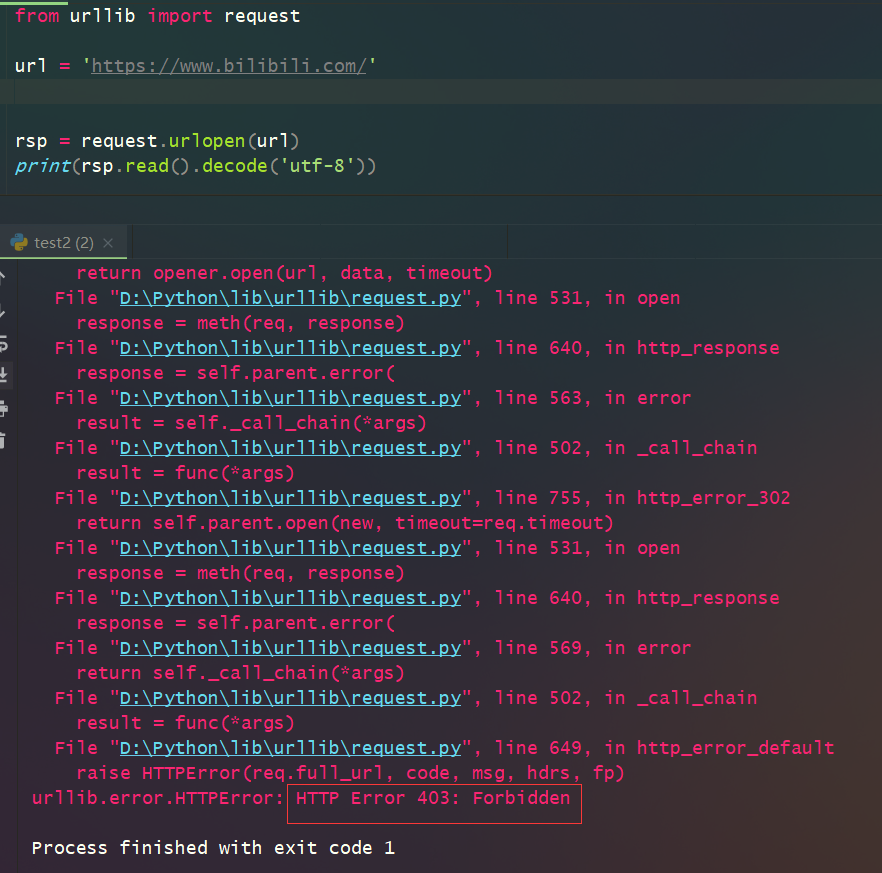
但是添加请求头之后,就可以正常访问了。
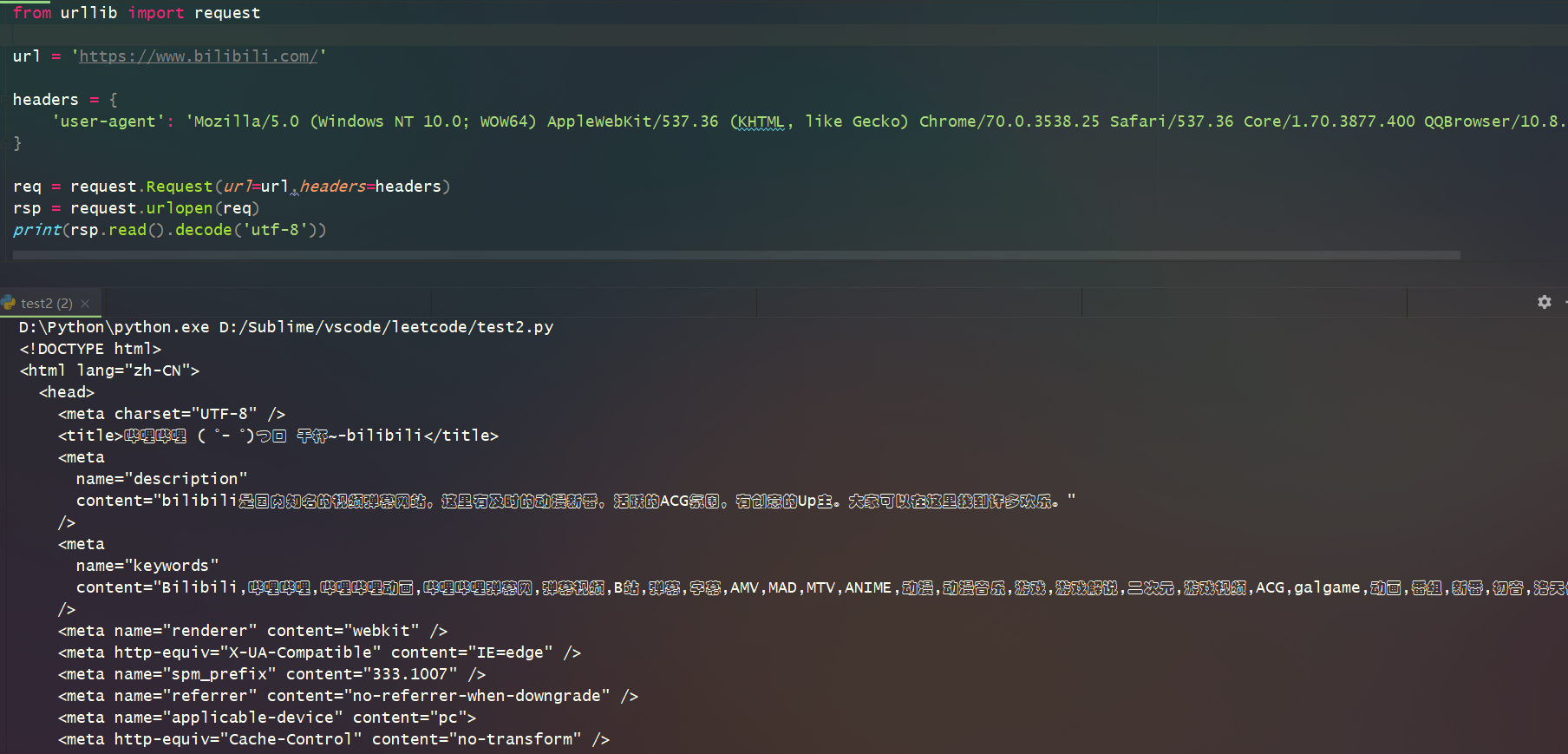
参考代码如下:
from urllib import request
url = 'https://www.bilibili.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4507.400'
}
req = request.Request(url=url,headers=headers)
rsp = request.urlopen(req)
print(rsp.read().decode('utf-8'))
2.如用urllib模块来访问百度网站时会出现如下情况:
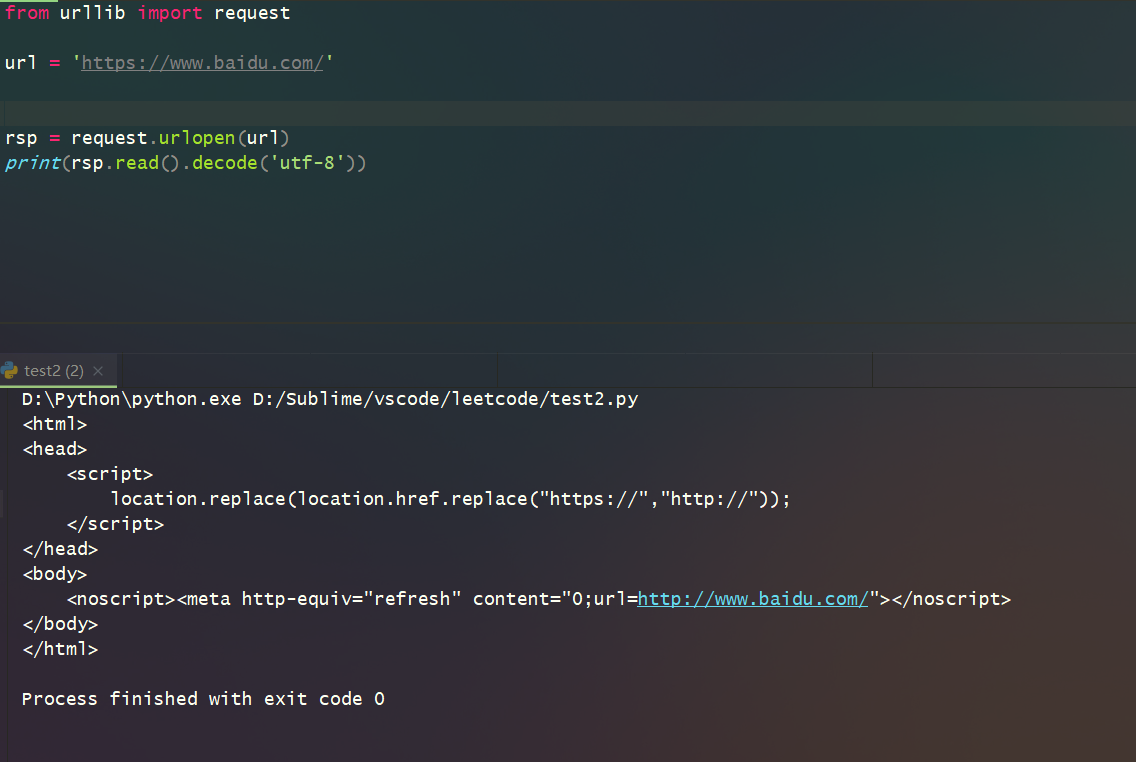
很显然,这个网页不可能就这么点代码标签,添加一个请求头之后,如下:

3. 动态网页加载的数据
提到动态网页,读者首先可以去看看小编的这篇文章:Python爬虫:什么是静态网页(数据),什么是动态网页(数据)、Python爬虫:爬取动态网页数据“你”需要知道的事,小编学习过后端知识,大体知道为什么用上述方式访问不到相应的数据。why(大概是这样吧!也有可能讲的不对,希望读者指正[如果有错误的话],一般而言,我们用爬虫爬取得到的数据是当前网页已经完全加载的,然而动态网页使用了ajax技术,而执行者一段ajax代码好像是网页完全加载之后才执行的,因此你用爬虫爬取不到那部分数据。)
此时,你有两种解决方式:
- 找到这个ajax的相关网页链接,访问这个链接,从而得到相关数据;
- 直接使用selenium这个模块,操作浏览器访问。
如果读者使用第1种解决方式,有可能你访问的那个链接一些参数是加密的,这时你需要利用js断点(使用谷歌浏览器),找到那段加密参数加密之前的数据信息和相关的一些js加密函数,找到加密之前的数据信息的组合规则。关于js加密函数,如果简单的话,直接用Python模拟出加密效果即可;如果复杂的话,最好使用execjs或者其他Python模块下的一些方法去执行这些js加密函数。
上述关于使用第1种解决方式,小编过去做过的有Python爬虫爬取酷狗音乐、网易云音乐、斗鱼视频等。
- Python爬虫:通过js逆向我发现了斗鱼视频请求参数的加密原理
- Python爬虫:通过做项目,小编了解了酷狗音乐的加密过程
- python爬虫:了解JS加密爬取网易云音乐
- Python反爬:利用js逆向和woff文件爬取猫眼电影评分信息
4. 总结
有的读者也许会问,如果我ip封掉了,怎样爬取网页数据,其实,使用相关ip代理即可,IP代理文章链接为:Python爬虫:制作一个属于自己的IP代理模块2、Python爬虫:运用多线程、IP代理模块爬取百度图片上小姐姐的图片。另外,还有一些高大上的反爬措施,小编并不是很了解,就不在这一一赘述了,如果未来小编真的了解到了,到时候再在本文章后加上吧!
Python爬虫:为什么你爬取不到网页数据的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
随机推荐
- Map和WeakMap的方法和区别
Map Map是一组键值对的结构,具有极快的查找速度. 一.构造函数不同 let map = new Map(); let weakmap = new WeakMap(); 二.内置函数不同 Map的 ...
- 在vue中路径中的@
1.在Vue的路径中@等于src 2.在css的路径中~@等于src
- 场景实践:基于 IntelliJ IDEA 插件部署微服务应用
体验简介 阿里云云起实验室提供相关实验资源,点击前往 本场景指导您把微服务应用部署到 SAE 平台: 登陆 SAE 控制台,基于 jar 包创建应用 基于 IntelliJ IDEA 插件更新 SAE ...
- vue新手入门之使用vue框架搭建用户登录注册案例,手动搭建webpack+Vue项目(附源码,图文详解,亲测有效)
前言 本篇随笔主要写了手动搭建一个webpack+Vue项目,掌握相关loader的安装与使用,包括css-loader.style-loader.vue-loader.url-loader.sass ...
- 解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法
摘要:本文提出了两个用于无监督的具备可解释性和鲁棒性时间序列离群点检测的自动编码器框架. 本文分享自华为云社区<解读ICDE'22论文:基于鲁棒和可解释自编码器的无监督时间序列离群点检测算法&g ...
- redis入门,linux安装
1.下载 https://redis.io/download 2.上传到linux服务器tools文件夹下 3.解压到安装目录 tar -zxf /app/redis/redis-5.0.4.tar. ...
- HDLBits->Verilog Language->Modules:Hierarchy->Modules and vectors
题目要求如上不再赘述,主要关注到最后的四选一多路选择器. 最初编写的选择器代码如下 always@(sel) case(sel) 2'd0:q <= d; 2'd1:q <= in1; 2 ...
- Python Excel 操作
1.Excel Code import os import time import re import win32com.client def dealpath(pathname='') -> ...
- 零基础学Python:元组(Tuple)详细教程
Python的元组与列表类似,不同之处在于元组的元素不能修改,元组使用小括号,列表使用方括号,元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可https://jq.qq.com/?_wv=1 ...
- MySQL通过binlog日志恢复数据
一.查看下自己的MySQL是否开启了binlog日志 # 是否启用binlog日志 OFF:关闭 ON:开启 show variables like 'log_bin'; 二.开启binlog日志 在 ...