Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
1、window操作系统的eclipse运行wordcount程序出现如下所示的错误:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at com.bie.hadoop.wordcount.WordCountRunner2.run(WordCountRunner2.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at com.bie.hadoop.wordcount.WordCountRunner2.main(WordCountRunner2.java:)
暂时解决方法如下所示:
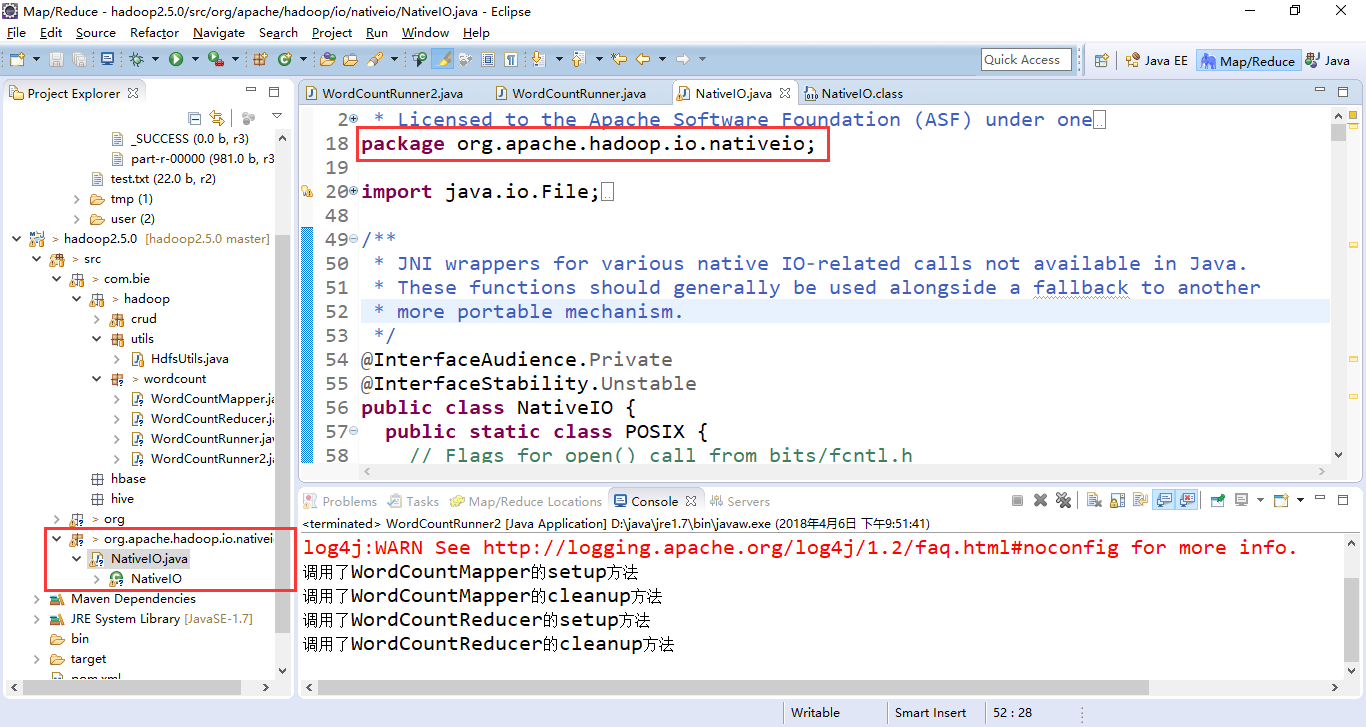
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。我们下载对应hadoop源代码,hadoop-2.6.0-src.tar.gz解压,D:\biexiansheng\hadoop\hadoop-2.5.0-cdh5.3.6-src\hadoop-2.5.0-cdh5.3.6\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的Eclipse的project,然后修改557行为return true如图所示:
注意:包的路径必须这样,不能变:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z的更多相关文章
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
在 windows 上运行 MapReduce 时报如下异常 Exception in thread "main" java.lang.UnsatisfiedLinkError: ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io .nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
首先,遇到这个问题的一个原因是windows环境中没有配置hadoophome.配置之后加入winutils工具 第二个原因,pom中执行的hadoop的版本与window环境中的hadoop的版本不 ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- 本地spark报:java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Ljava/lang/String;JJJI)Ljava/io/FileDescriptor;
我是在运行rdd.saveAsTextFile(fileName)的时候报的错,找了很多说法……最终是跑到hadoop/bin文件夹下删除了hadoop.dll后成功.之前某些说法甚至和这个解决方法自 ...
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
环境: Spark2.1.0 .Hadoop-2.7.5 代码运行系统:Win 7在运行Spark程序写出文件(savaAsTextFile)的时候,我遇到了这个错误: // :: ERROR U ...
- [解决]Hadoop 2.4.1 UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
问题:UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0 我的系统 win7 64位 Hadoop ...
- dbca:Exception in thread "main" java.lang.UnsatisfiedLinkError: get
在64位的操作系统安装oracle10g 软件安装完成后,使用dbca建库的时候报下面的错: $ dbcaUnsatisfiedLinkError exception loading native l ...
- Java中调用c/c++语言出现Exception in thread "main" java.lang.UnsatisfiedLinkError: Test.testPrint(Ljava/lang/String;)V...错误
错误: Exception in thread "main" java.lang.UnsatisfiedLinkError: Test.testPrint(Ljava/lang/S ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError:
[oracle@landor database]$ ./runInstaller 正在启动 Oracle Universal Installer... 检查临时空间: 必须大于 MB. 实际为 MB ...
随机推荐
- 关于 DELPHI DATASNAP 的文章集
关于 DELPHI DATASNAP 的文章集: 1.墨者工作室 DataSnap基础 https://wenku.baidu.com/view/78715605cc1755270722088b. ...
- 网页块元素定位建议使用的xpath方式
取上图的新手上路文字 使用xpath "//div[@class='pbm mbm bbda cl']//li[contains(string(),'用户组')]/span/a/text() ...
- boost 随机数发生器
Random 随机数 在很多应用中都需要使用随机数.本库力求提供一个高效的,通用的随机数库.boost库有多种随机数生成方式.先熟悉一下各种随机数生成器的概念. 数字生成器(Number Ge ...
- Python os.access() 方法
概述 os.access() 方法使用当前的uid/gid尝试访问路径.大部分操作使用有效的 uid/gid, 因此运行环境可以在 suid/sgid 环境尝试. 语法 access()方法语法格式如 ...
- NOI2019 SX 模拟赛 no.5
Mas 的童年 题目描述:不知道传送门有没有用? 反正就是对于每个前缀序列求一个断点,使得断点左右两个区间的 分别的异或和 的和最大 分析 jzoj 原题? 但是我 TM 代码没存账号也过期了啊! 然 ...
- $Django 图片验证刷新 上传头像
1.图片验证刷新 $('img').click(function () { $('img')[0].src+='?' }) 2.上传头像 1.模板 <div class="form-g ...
- 配置percona mysql server 5.7基于gtid主主复制架构
配置mysql基于gtid主主复制架构 环境: 操作系统 centos7. x86_64 mysql版本:Percona-Server-- 测试环境: node1 10.11.0.210 node2 ...
- centos7 部署rabbitmq
1.安装 Erlang 就想我们编写Java引用程序需要安装 JDK一样,安装 RabbitMQ ,我们也需要安装 Erlang . ①.下载 erlang 安装包 将安装包下载到 /home/erl ...
- python中的各种锁
一.全局解释器锁(GIL) 1.什么是全局解释器锁 在同一个进程中只要有一个线程获取了全局解释器(cpu)的使用权限,那么其他的线程就必须等待该线程的全局解释器(cpu)使 用权消失后才能使用全局解释 ...
- 其他 Confluence 6 的 cookies 和备注
其他 Confluence 的 cookies 针对 Confluence 的功能,我们还使用了其他的一些 cookies 来存储基本的 产品持久性(product presentation).Con ...